📊 Experiments & Results
Evaluation Setup
Evaluated on complex reasoning tasks (Science, Math, Coding) and open-domain QA.
Benchmarks:
- Various Science/Math/Coding tasks (Complex Reasoning)
- Six Open-domain QA benchmarks (Question Answering)
Metrics:
- Accuracy
- Uncertainty frequency (count of words like 'perhaps')
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Challenging reasoning problems | Frequency of uncertain terms ('perhaps') | 30 | ~0 | -30 |
Experiment Figures
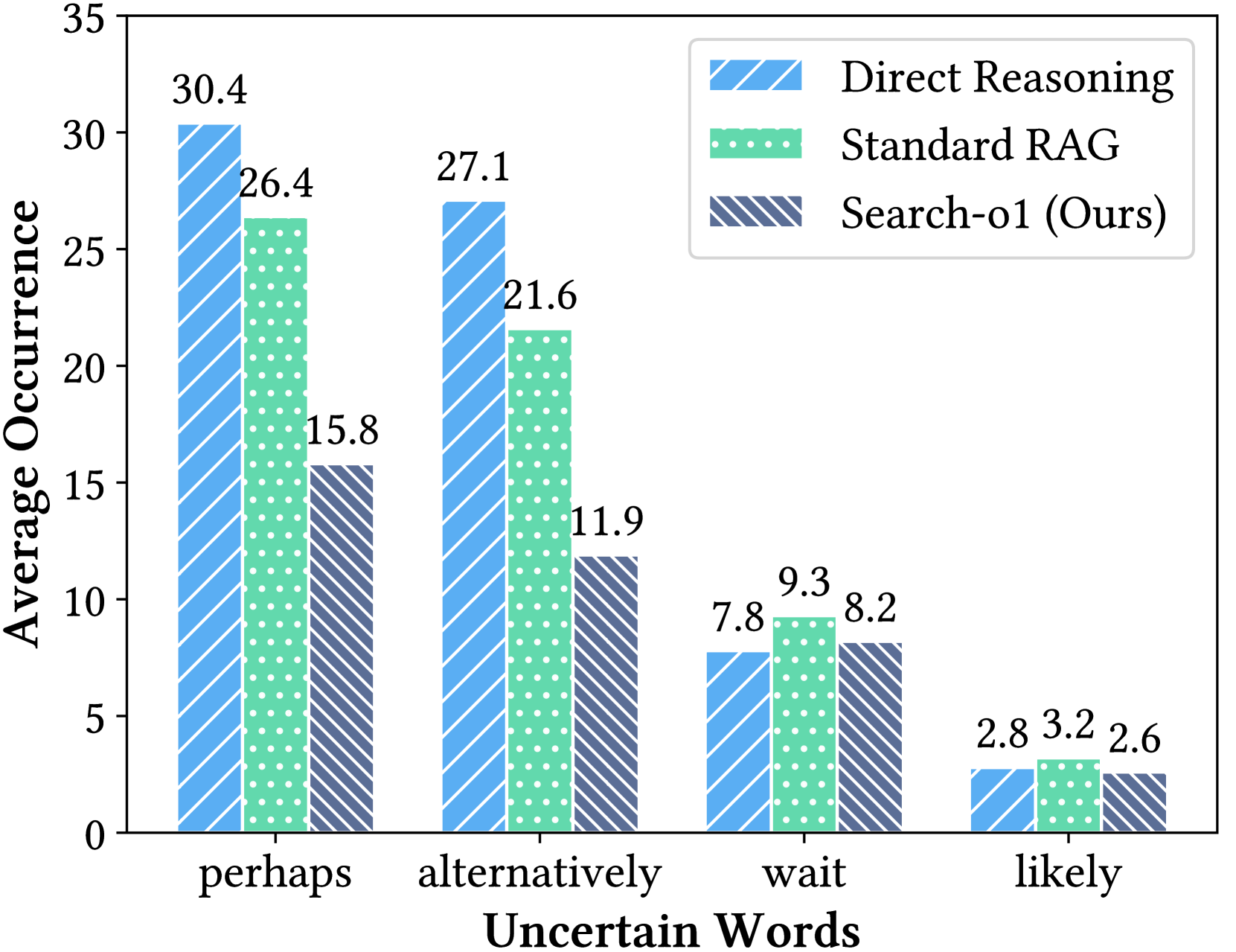
Frequency of uncertain words (e.g., 'perhaps') in reasoning chains and comparison of Standard RAG vs. Direct Reasoning.
Main Takeaways
- Standard RAG fails to address knowledge gaps in complex reasoning because the necessary information often depends on intermediate reasoning steps, not just the initial question.
- Directly injecting raw retrieved documents disrupts the coherence of the Chain-of-Thought; the 'Reason-in-Documents' refinement is crucial for maintaining performance.
- The framework significantly reduces model hallucination and uncertainty by grounding reasoning steps in retrieved data.