📝 Paper Summary
Agentic RAG pipeline
Reasoning-based Retrieval
ReSearch trains LLMs to autonomously interleave reasoning and search actions using reinforcement learning without any supervised labels for the reasoning or search steps.
Core Problem
Current multi-step RAG approaches rely on labor-intensive, unscalable manual prompts or heuristics, and collecting supervised labels for complex reasoning-search chains is impractical.
Why it matters:
- Real-world questions are often complex and require multiple retrieval steps, which static RAG pipelines fail to address effectively.
- Manually designing prompts for every complex scenario is not scalable.
- Existing RL approaches focus on internal reasoning (like DeepSeek-R1) but have not fully explored integrating external knowledge retrieval into the reinforcement loop.
Concrete Example:
When asking a multi-hop question, a standard model might search once and hallucinate connections. ReSearch, as shown in the case study, searches for a term, realizes 'I made a mistake' when results are irrelevant, reflects, and generates a corrected query to find the answer.
Key Novelty
Reinforcement Learning for Interleaved Reasoning and Search (ReSearch)
- treats search operations as integral actions within a chain-of-thought reasoning process, optimized purely via RL (GRPO) based on final answer correctness.
- Eliminates the need for supervised 'gold' reasoning chains or search queries; the model self-learns when to search and how to use results through trial and error.
- Introduces a specialized rollout format where the model generates <search> tags, pauses for external retrieval, and resumes reasoning with <result> context.
Architecture
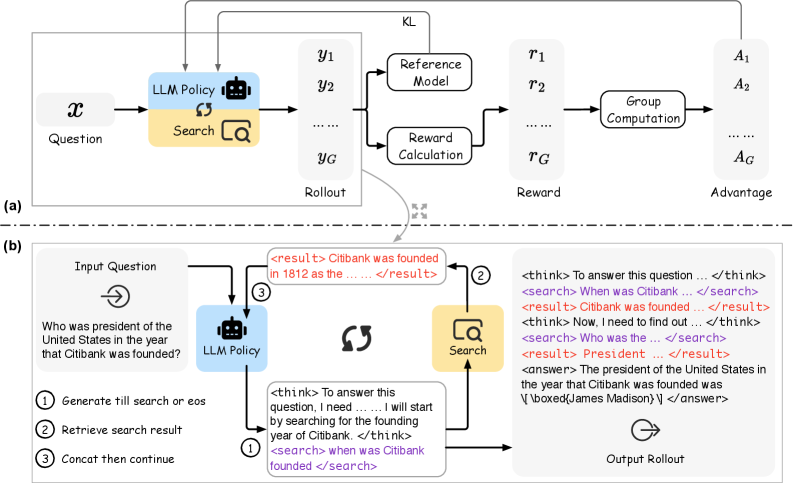
Illustration of the ReSearch framework and the GRPO training process.
Evaluation Highlights
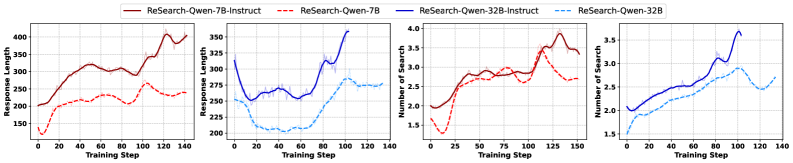
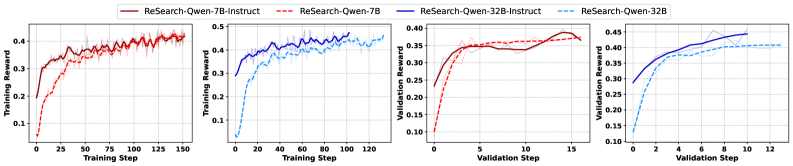
- Outperforms best baselines by +15.81% (Exact Match) on average across benchmarks using Qwen2.5-7B.
- Achieves strong generalization: trained only on MuSiQue but shows consistent gains on HotpotQA, 2WikiMultiHopQA, and Bamboogle.
- Surpasses prompt-based methods like IRCoT and Iter-RetGen by margins ranging from 8.9% to 22.4%.
Breakthrough Assessment
8/10
Strong evidence that RL alone can induce sophisticated search behaviors (including self-correction) without supervised process data. Bridges the gap between DeepSeek-R1 style reasoning and RAG.