📝 Paper Summary
Memory organization
Linear memory
Agentic AI
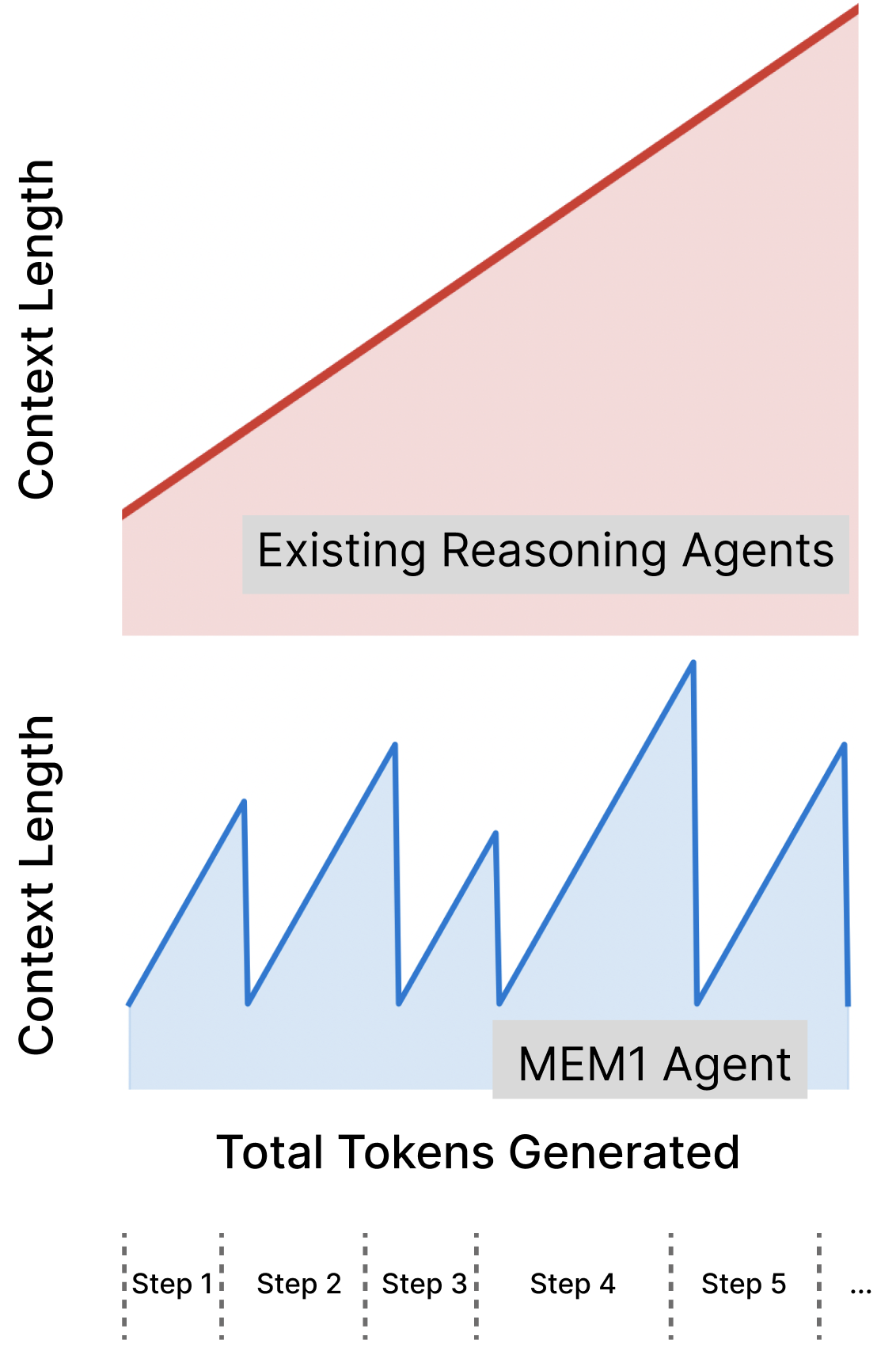
MEM1 trains agents via reinforcement learning to constantly update a compact internal state, allowing them to solve long-horizon tasks with fixed memory size rather than growing context windows.
Core Problem
Standard multi-turn agents simply append all history to the prompt, causing linear memory growth, increased inference cost, and performance degradation as context length exceeds training limits.
Why it matters:
- Real-world applications like research assistants or shopping agents require dozens of turns, making full-context prompting computationally prohibitive
- Growing contexts accumulate irrelevant information that dilutes the model's attention, reducing reasoning accuracy even if the answer is present
- Existing external memory modules (summarizers/retrievers) are often trained separately from the policy, preventing end-to-end optimization of what to remember
Concrete Example:
A research assistant asked 'What is the evidence for X?' followed by 'Who published it?' appends every intermediate search result to the context. Eventually, the prompt exceeds GPU memory or the model gets confused by old, irrelevant search snippets, failing to answer 'Is the source credible?'.
Key Novelty
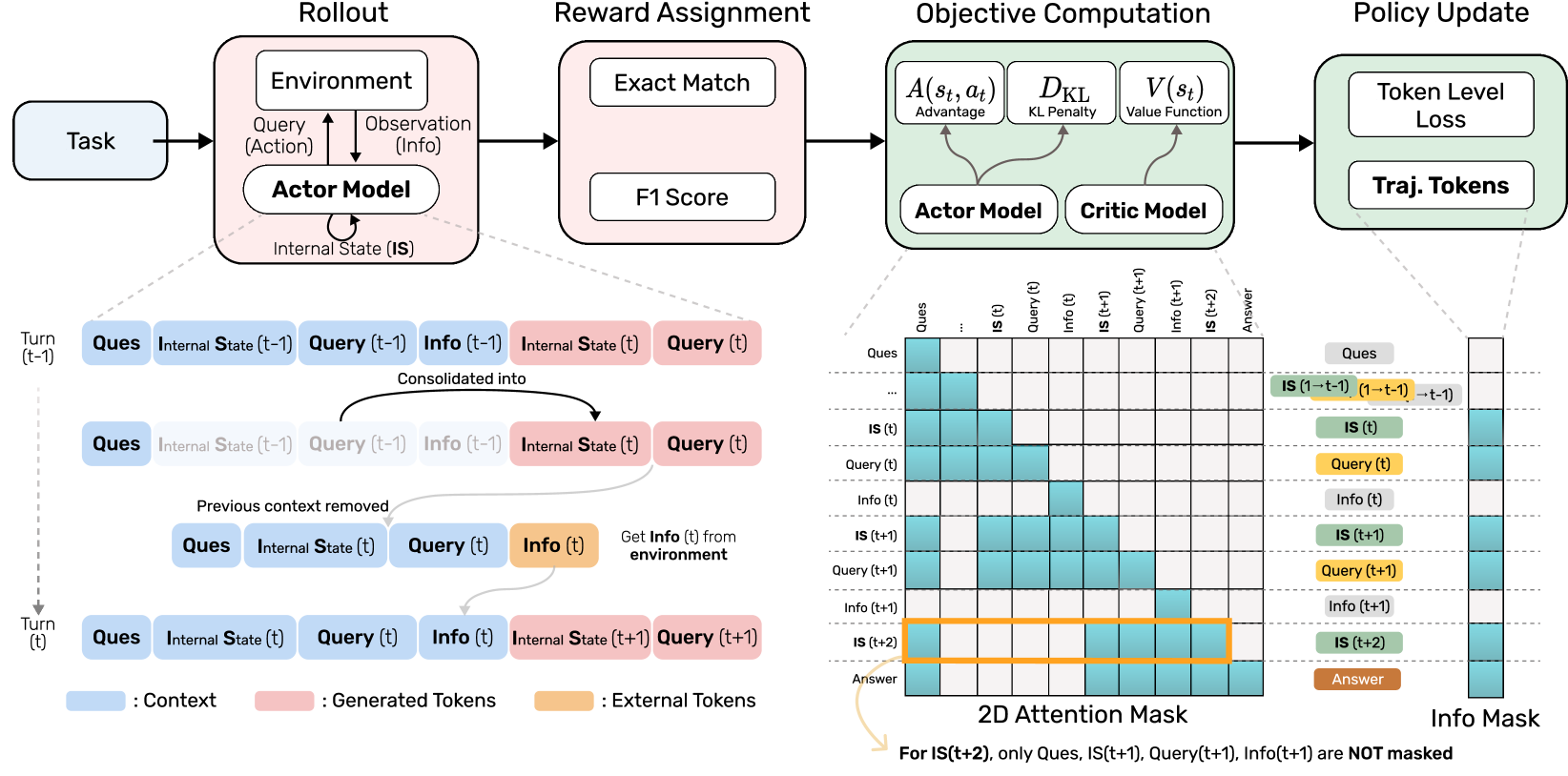
Learning to Forget via 1-Step Consolidation
- Replaces the growing interaction history with a single, evolving 'Internal State' (<IS>) that is updated at every turn
- Uses reinforcement learning to force the model to compress necessary history into this state, as all other context is pruned after each step
- treats reasoning as 'working memory,' unifying the process of thinking about the next step with the process of deciding what to remember
Architecture
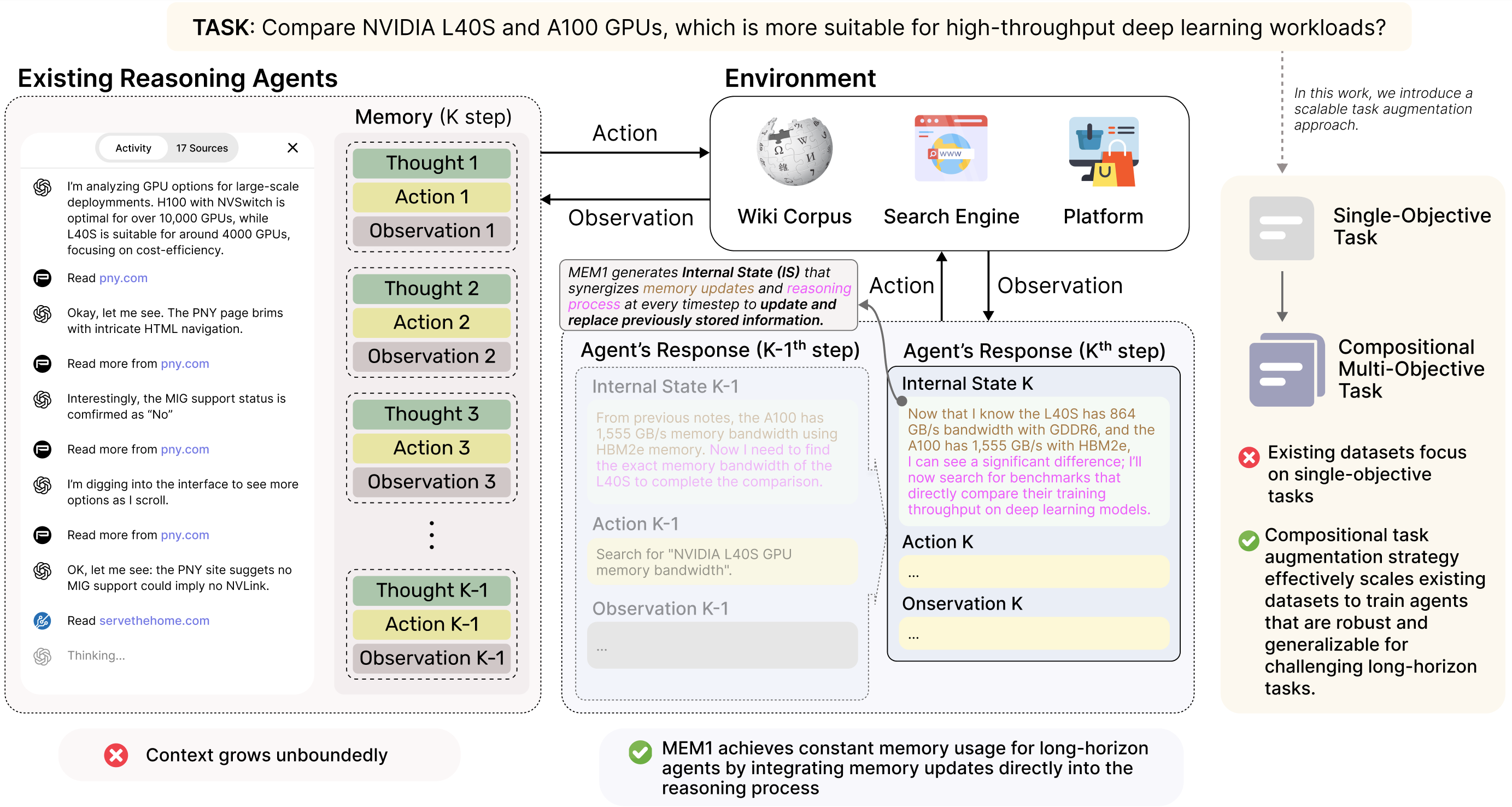
Conceptual comparison between Full-Context agents and MEM1 agents
Evaluation Highlights
- Improves performance by 3.5x while reducing memory usage by 3.7x compared to Qwen2.5-14B-Instruct on a 16-objective multi-hop QA task
- Achieves 1.27x lower peak memory usage and 1.78x faster inference than the best uncollapsed baseline at the 16-objective level
- Generalizes effectively from training on 2-objective compositions to solving tasks with up to 16-objective compositions
Breakthrough Assessment
8/10
Offers a scalable, RL-driven alternative to infinite context windows. Successfully demonstrating generalization from 2 to 16 reasoning steps with constant memory is a significant efficiency milestone.