📝 Paper Summary
Modularized RAG pipeline
Internalization through post-training
kNN-LM augments pre-trained language models by linearly interpolating the next-token distribution with a retrieval mechanism that searches a datastore of training examples, improving performance without retraining.
Core Problem
Neural language models struggle to predict rare patterns and factual knowledge (the long tail) because they must implicitly memorize training examples in their parameters.
Why it matters:
- Implicit memorization in parameters is inefficient for rare events and factual knowledge, leading to poor generalization on the long tail.
- Scaling models often requires massive retraining; current methods lack efficient ways to scale or adapt to new domains without further training.
Concrete Example:
A model might know 'Dickens wrote...' implies an author name, but fails to predict 'David Copperfield' specifically. In the paper, a standard LM assigns probability 0.124 to the target 'honour' after a Gallipoli context, while kNN-LM assigns 0.998 by retrieving a near-identical training example.
Key Novelty
k-Nearest Neighbor Language Model (kNN-LM)
- Constructs a key-value datastore from training data, where keys are context embeddings and values are target tokens.
- During inference, retrieves the nearest neighbors of the test context from the datastore and computes a distribution over their values.
- Interpolates this retrieval-based distribution with the standard model's output distribution, allowing explicit memory access without retraining parameters.
Architecture
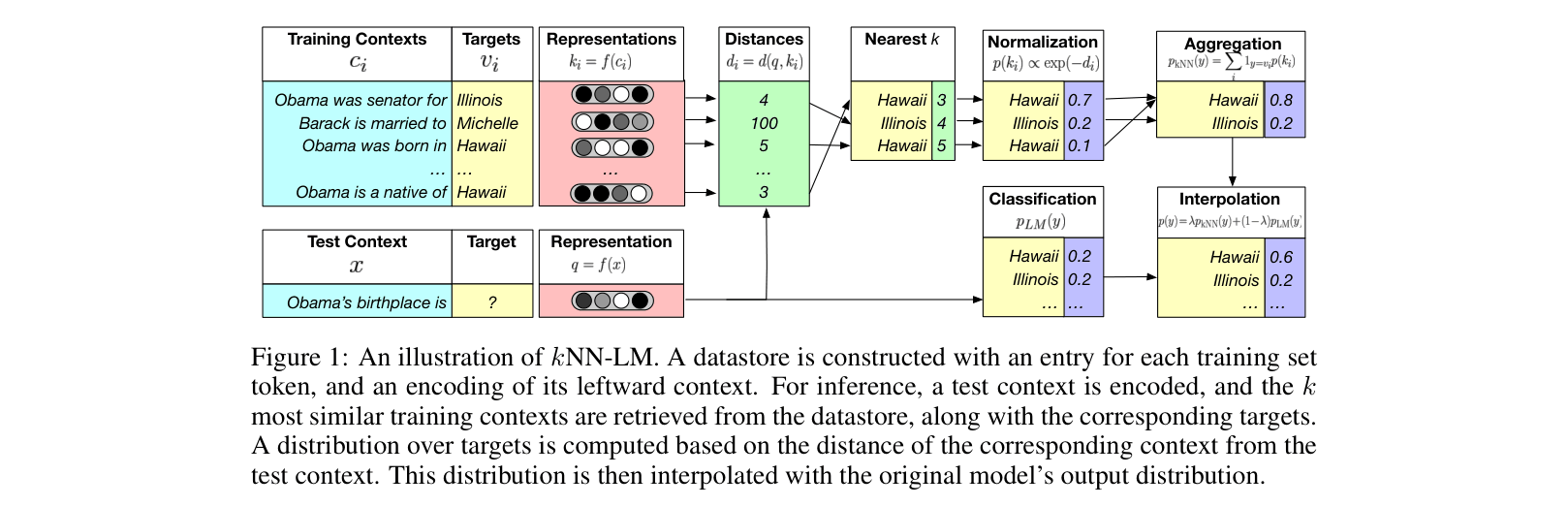
Illustration of the kNN-LM inference process using a pre-trained LM and a datastore.
Evaluation Highlights
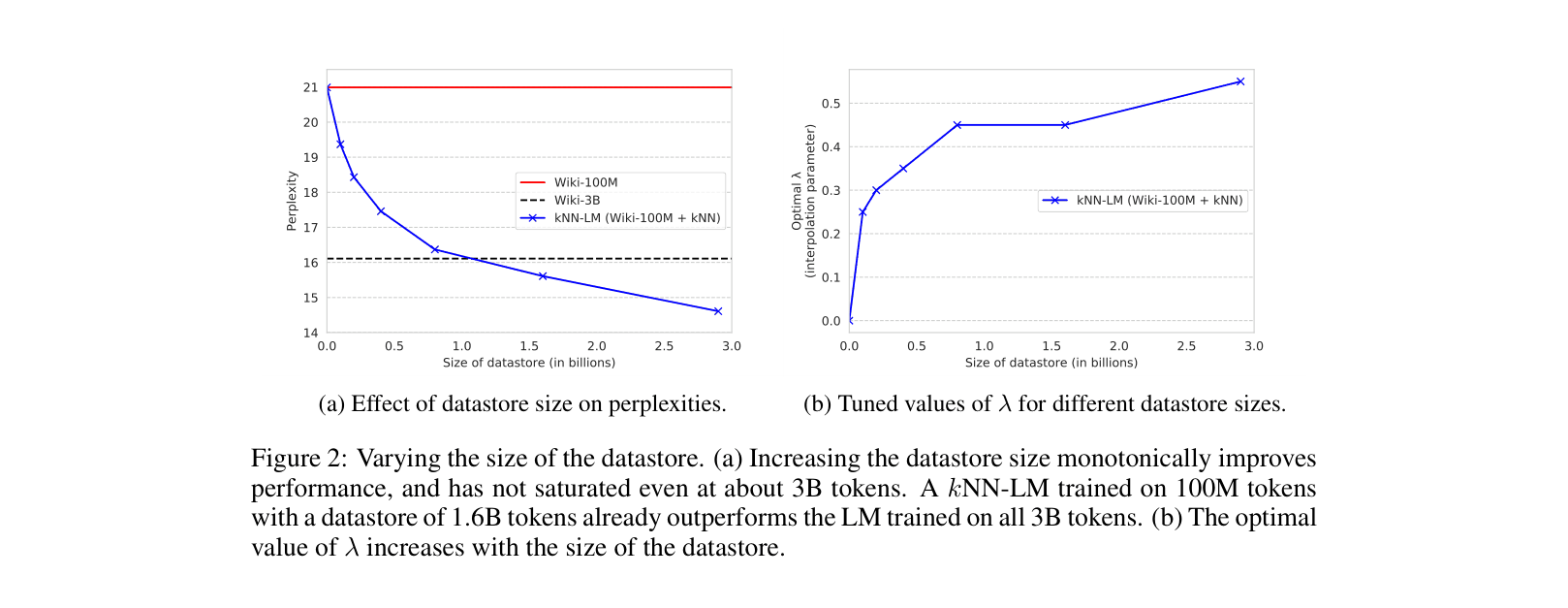
- Achieves state-of-the-art perplexity of 15.79 on WikiText-103, a 2.86 point improvement over the base model.
- Outperforms a model trained on 3B tokens (15.17 perplexity) by training on just 100M tokens and retrieving from the 3B corpus (13.73 perplexity).
- Effective domain adaptation: Adding a 'Books' datastore to a 'Wiki' model improves perplexity on Books from 34.84 to 20.47 without retraining.
Breakthrough Assessment
9/10
Simple yet highly effective method that achieved SOTA without training, demonstrated that retrieval can substitute for massive training data, and influenced subsequent retrieval-augmented generation research.