📝 Paper Summary
Knowledge internalization
Memory recall
Sparse memory QA
Entities as Experts (EAE) enhances Transformers by learning distinct memory representations for entities from text, accessing them sparsely only when those entities are mentioned.
Core Problem
Standard language models struggle to capture and access declarative knowledge about entities because they must construct representations from sub-word tokens (like "Charles" + "Darwin") rather than accessing a dedicated entity memory.
Why it matters:
- Language models are increasingly used as knowledge bases, but standard architectures are inefficient at storing and retrieving specific factual knowledge
- Previous methods rely on external, fixed entity embeddings (like Knowledge Graph embeddings), limiting the model to pre-existing knowledge bases rather than learning from text context
- Dense access to all parameters for every token is computationally inefficient; sparse access allows scaling model capacity without proportional compute cost
Concrete Example:
A standard Transformer sees "Charles Darwin" as separate tokens and might confuse it with "Charles River." EAE identifies the span "Charles Darwin," retrieves a specific learned memory vector for that entity, and uses it to answer questions like "Which Dr. Who villain has been played by...?"
Key Novelty
Entities as Experts (EAE)
- Replaces dense parameter access with a sparse 'Entity Memory' layer that contains learned embeddings for specific entities (e.g., one vector for 'Paris', one for 'London')
- Uses an internal mention detector to identify entity spans in text and route them to the correct 'expert' (entity memory) during the forward pass
- Learns entity embeddings jointly with the rest of the network from raw text, rather than relying on pre-trained external knowledge base embeddings
Architecture
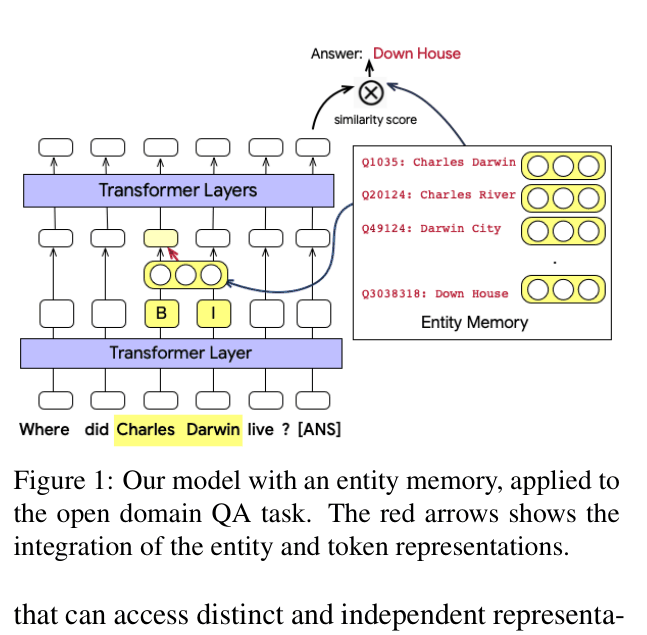
The EAE architecture interleaving Transformer layers with an Entity Memory layer.
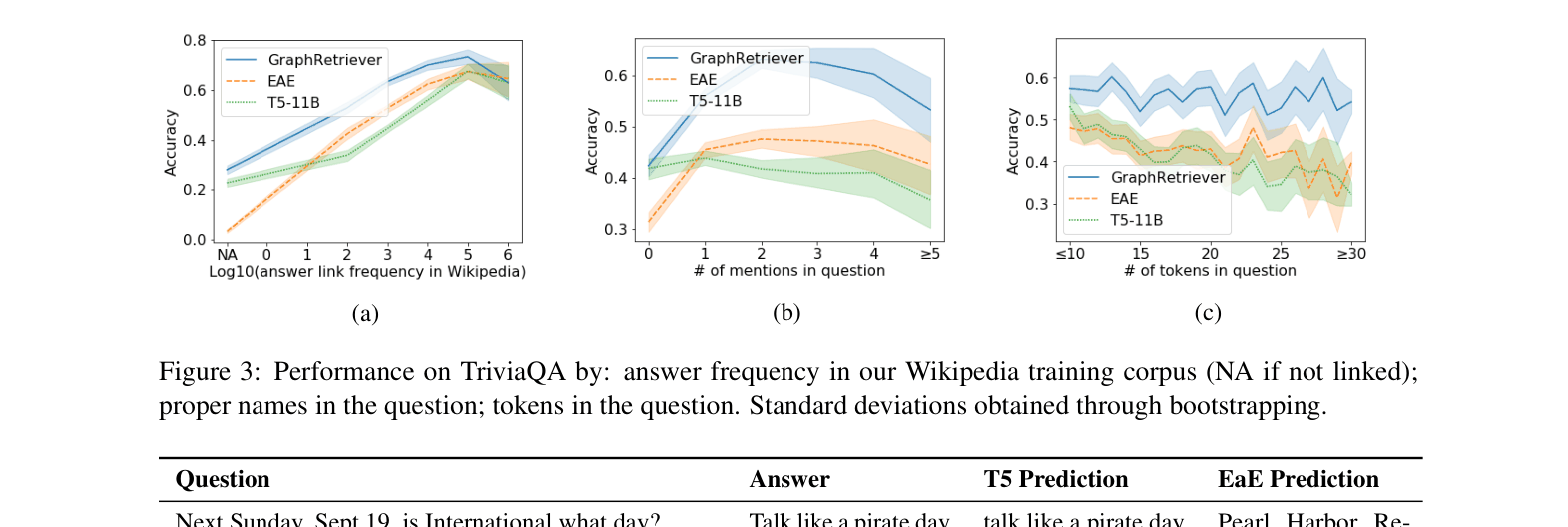
Evaluation Highlights
- Outperforms a Transformer encoder-generator (T5-Base) on TriviaQA while using 10x fewer parameters
- Achieves 43.2% Exact Match on TriviaQA (open-domain), surpassing T5-3B (34.4%) using only ~367M parameters
- Surpasses BERT-Large on the LAMA knowledge probe (T-REx subset) by 5.1 points (37.4 vs 32.3) despite having similar total parameter counts
Breakthrough Assessment
8/10
Significant architectural innovation in sparse memory access. Demonstrates that learned entity memories outperform massive dense models (T5-3B) on knowledge-intensive tasks with far fewer parameters.