📝 Paper Summary
Modularized RAG pipeline
Few-shot learning
Atlas is a retrieval-augmented language model that achieves state-of-the-art few-shot performance on knowledge-intensive tasks by jointly pre-training the retriever and reader components.
Core Problem
Large language models require massive parameter counts to store knowledge for few-shot tasks, but it is unclear if this memorization is strictly necessary or efficient.
Why it matters:
- Scaling parameter count for knowledge storage is computationally expensive and inefficient compared to retrieving from external memory
- Prior retrieval-augmented models had not demonstrated compelling few-shot learning capabilities comparable to closed-book LLMs like GPT-3
- Decoupling memorization from reasoning allows for smaller, more updateable, and interpretable models
Concrete Example:
For the query 'Where is the Bermuda Triangle?', a closed-book model must rely on internal weights. If it hasn't memorized the fact, it fails. Atlas retrieves documents about the Bermuda Triangle from a corpus and uses them to generate the answer 'Western part of the North Atlantic Ocean', achieving high accuracy with 50x fewer parameters than PaLM.
Key Novelty
Joint Pre-training for Few-shot Retrieval Augmented Generation
- Jointly pre-trains a dense retriever and a sequence-to-sequence reader using unsupervised objectives like Perplexity Distillation, allowing the retriever to learn what documents help the language model
- Demonstrates that retrieval-augmented models can match or beat massive closed-book LLMs (like PaLM 540B) on few-shot tasks with significantly fewer parameters (11B)
- Investigates efficient fine-tuning strategies like query-side fine-tuning and re-ranking to handle index freshness without full re-indexing
Architecture
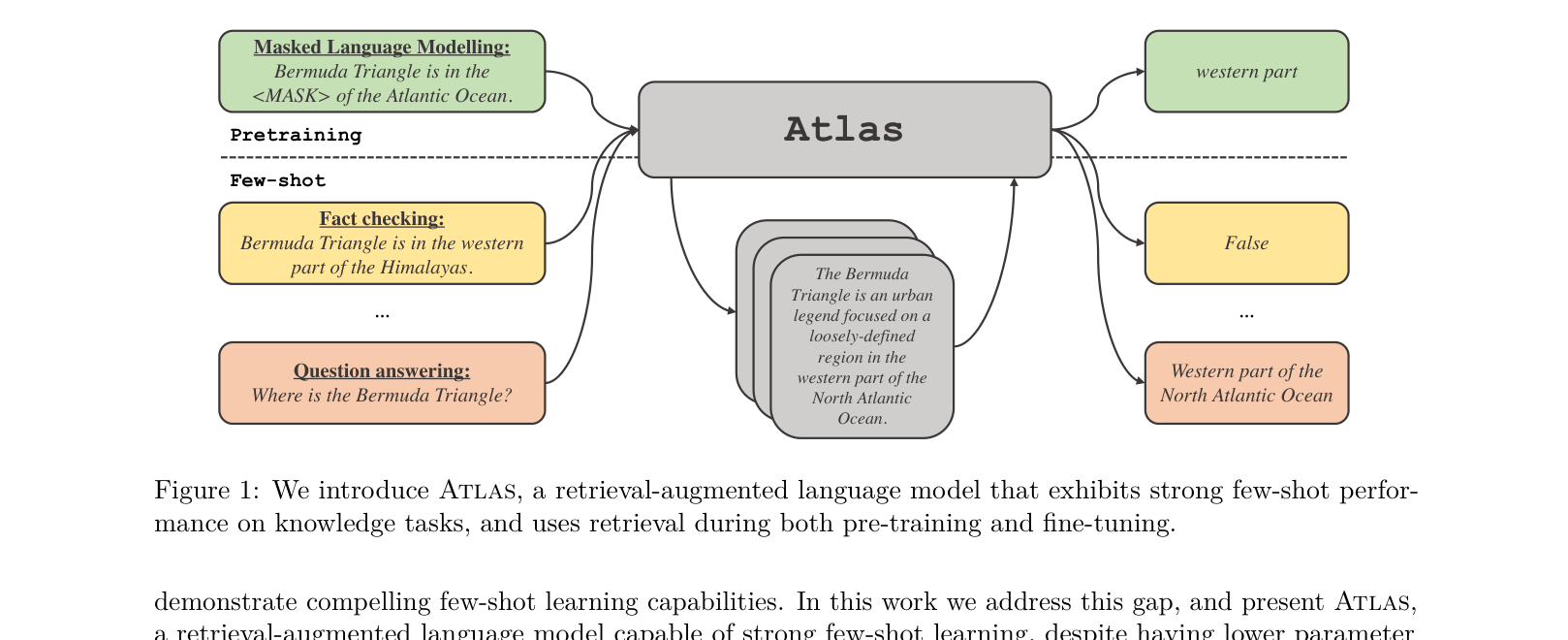
Overview of the Atlas framework, showing the retrieval-augmented workflow during pre-training (Masked Language Modeling) and few-shot fine-tuning (QA/Fact Checking).
Evaluation Highlights
- Atlas-11B achieves 42.4% accuracy on Natural Questions with only 64 training examples, outperforming PaLM-540B (39.6%) despite having 50x fewer parameters
- Sets new state-of-the-art on full-dataset Natural Questions (64.0%) and TriviaQA (84.7%), surpassing prior bests by over 8 points
- On 5-shot MMLU, Atlas-11B achieves 43.4% accuracy (47.9% with de-biasing), outperforming GPT-3's 43.9% while using 15x fewer parameters
Breakthrough Assessment
9/10
Establish Atlas as the standard for retrieval-augmented few-shot learning. It convincingly demonstrates that retrieval can replace massive parameter scale for knowledge tasks, outperforming models 50x its size.