📝 Paper Summary
Memory recall
Modularized RAG pipeline
TRIME aligns language model representations with memory units during training by treating in-batch segments as accessible memory, enabling effective use of local, long-term, and external memories at inference.
Core Problem
Existing memory-augmented language models typically introduce memories only at test time (e.g., kNN-LM) or use separately trained encoders, resulting in suboptimal alignment between the LM and the memory representations.
Why it matters:
- Current approaches miss the opportunity to optimize how the model interacts with memory during the training phase
- Separate training leads to a disconnect where the query representation and memory keys are not aligned for the retrieval task
- Standard attention mechanisms scale quadratically, limiting the ability to leverage long-range context efficiently without explicit memory structures
Concrete Example:
In kNN-LM, the model is trained normally, and a datastore is only added during inference. If a rare word appears in the context, the model's internal representation might not be sharp enough to retrieve the correct instance from the external memory because it was never trained to perform that retrieval.
Key Novelty
TRIME (Training with In-batch Memories)
- Utilizes a contrastive loss that aligns the current context's representation with both the target token embedding and positive memory examples from the same batch
- Constructs training memories on-the-fly using specific batching strategies (consecutive segments for long-term memory; BM25-similar segments for external memory)
- Allows back-propagation through the memory representations, ensuring the query and key representations are jointly optimized
Architecture
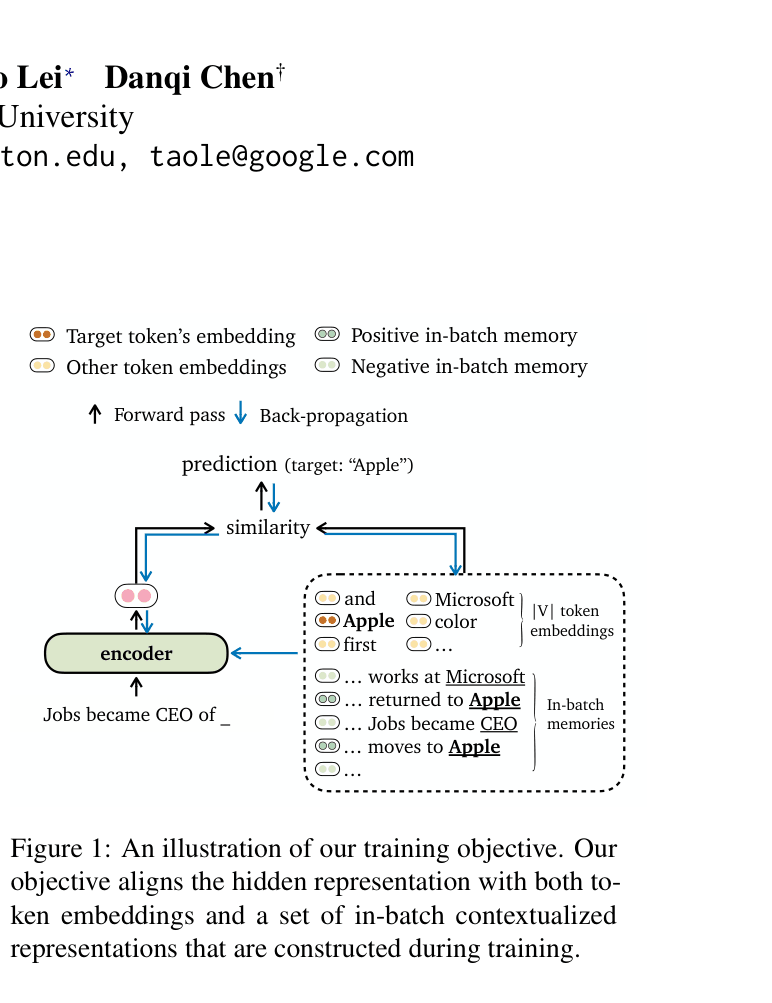
Illustration of the TRIME training objective and forward pass.
Evaluation Highlights
- Reduces perplexity from 18.70 to 15.37 on WikiText-103 (247M parameter model) by leveraging external memory
- Outperforms kNN-LM (perplexity 16.23 → 15.41) and kNN-MT on machine translation, showing better utilization of large datastores
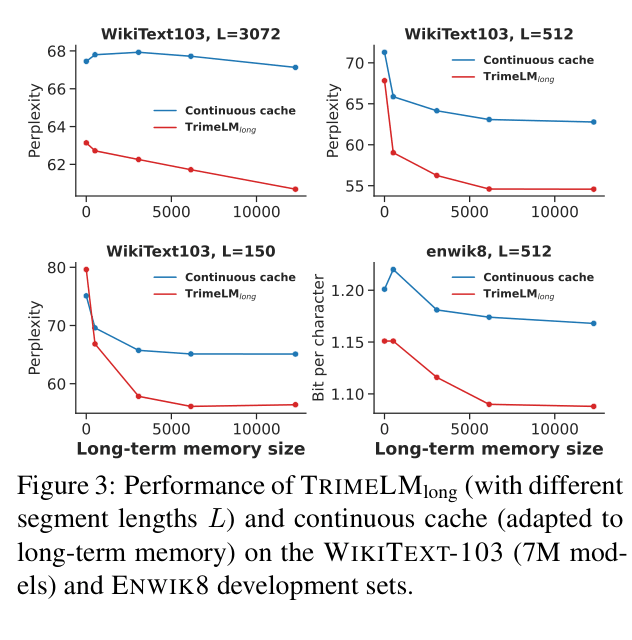
- Enables effective use of 15k-25k token contexts, outperforming specialized long-context architectures like Transformer-XL on WikiText-103
Breakthrough Assessment
8/10
Simple yet highly effective training paradigm that unifies local, long-term, and external memory augmentation. It consistently outperforms strong baselines like kNN-LM and Transformer-XL without architectural changes.