📊 Experiments & Results
Evaluation Setup
Pretraining LMs from scratch on 300B tokens and evaluating on downstream tasks
Benchmarks:
- Language Modeling (Perplexity) (Next token prediction on Wikipedia, Arxiv, Books)
- In-Context Learning (Classification (SST-2, AGNews, etc.) with 32 shots)
- Reading Comprehension (QA (RACE, SQuAD, HotpotQA, BoolQ, DROP))
- Retrieval Augmentation (Open-domain QA (Natural Questions, TriviaQA))
Metrics:
- Perplexity
- Accuracy
- Exact Match (EM)
- Faithfulness (MemoTrap)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Reading Comprehension results show ICLM significantly outperforming baselines, especially on multi-hop tasks like HotpotQA. | ||||
| HotpotQA | Exact Match | 17.4 | 23.6 | +6.2 |
| RACE-High | Accuracy | 44.6 | 47.2 | +2.6 |
| Average (8 datasets) | Score (Acc/EM) | 42.0 | 48.2 | +6.2 |
| In-Context Learning evaluation demonstrates ICLM's superior ability to learn from demonstrations. | ||||
| Average (8 classification datasets) | Accuracy | 69.0 | 74.8 | +5.8 |
| Retrieval Augmentation results show ICLM is better at utilizing external context. | ||||
| Natural Questions (Open-Book) | Exact Match | 18.8 | 21.6 | +2.8 |
| Faithfulness evaluation using MemoTrap. | ||||
| MemoTrap | Accuracy | 50.1 | 58.1 | +8.0 |
Experiment Figures
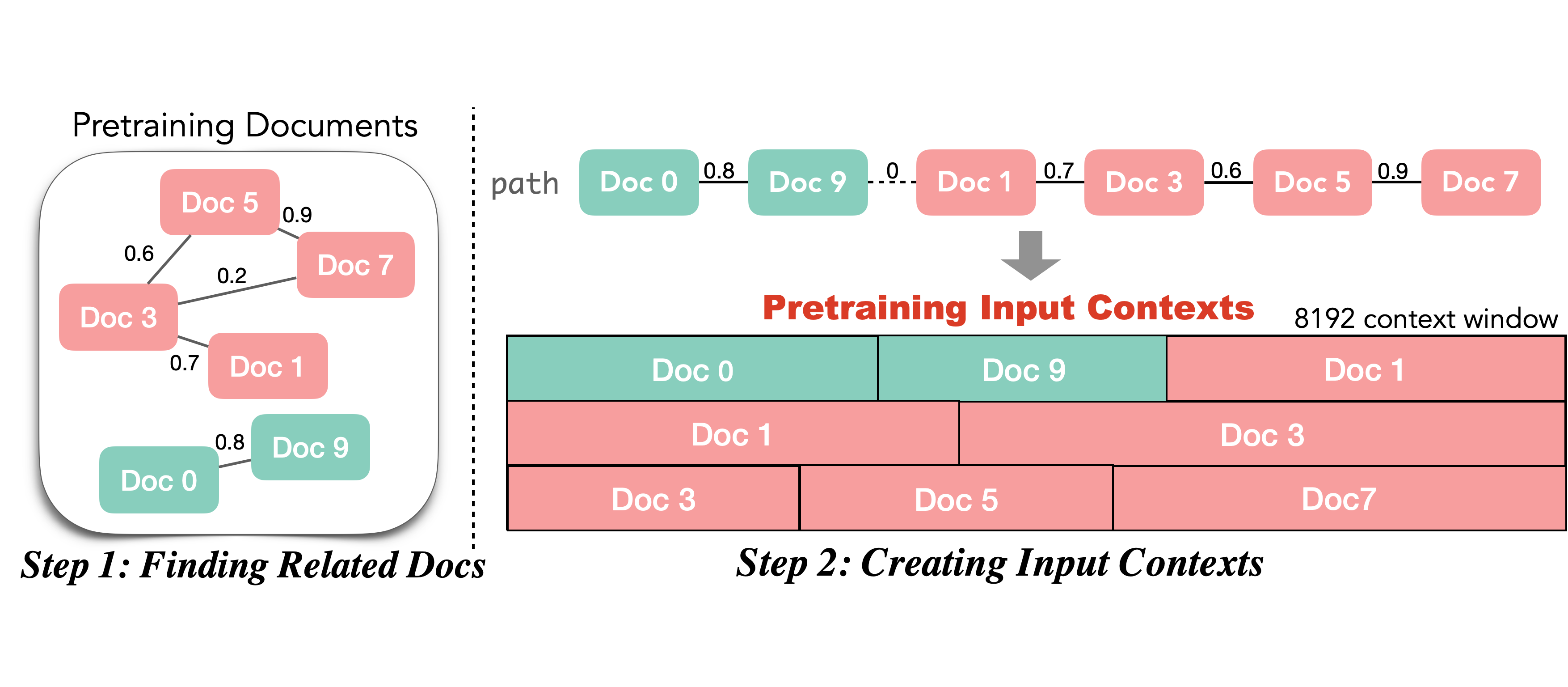
Language modeling perplexity on Wikipedia, Arxiv, and Books for Standard, kNN, and ICLM models across different parameter scales.
Main Takeaways
- In-Context Pretraining consistently outperforms standard training and kNN baselines across model scales (0.3B to 7B) and diverse tasks.
- The method is particularly effective for tasks requiring complex reasoning over context (Reading Comprehension) and utilization of provided demonstrations (In-Context Learning).
- kNN pretraining (allowing repeats) often underperforms standard training due to overfitting/lack of diversity, validating the need for the non-repeating TSP graph traversal approach.
- Deduplication during graph construction is crucial; without it, performance drops significantly.