📝 Paper Summary
Modularized RAG pipeline
Domain adaptation
RAFT adapts language models to domain-specific RAG by fine-tuning them on a mix of relevant and distractor documents, teaching the model to ignore irrelevant context and cite evidence.
Core Problem
Existing methods either fine-tune models on domain data (ignoring test-time retrieval imperfections) or use RAG with generic models (failing to learn domain style/patterns), leading to poor performance when distractors are present.
Why it matters:
- LLMs are increasingly used in specialized domains (legal, medical, enterprise) where general knowledge is less critical than maximizing accuracy on specific documents
- Standard fine-tuning (DSF) often encourages memorization rather than reasoning from context, failing open-book exams
- RAG-based in-context learning fails to leverage the learning opportunity afforded by the fixed domain setting
Concrete Example:
When asked 'Who is the screenwriter of [Movie]?', a standard fine-tuned model might hallucinate a famous movie written by that person instead of naming the person, whereas RAFT correctly identifies the name by citing the provided document.
Key Novelty
Retrieval Augmented Fine Tuning (RAFT)
- Prepares fine-tuning data where each sample contains a question, a set of documents (including 'golden' relevant ones and 'distractor' irrelevant ones), and a chain-of-thought answer citing the text
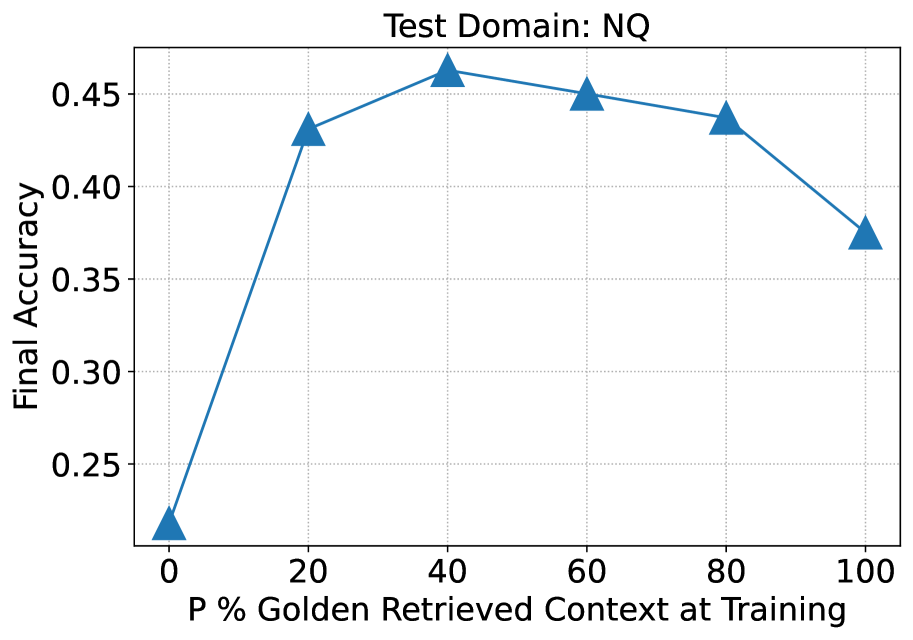
- Intentionally removes the 'golden' document in a subset of training data (P% of the time) to force the model to memorize some answers, while learning to extract answers from context in others
- Trains the model to explicitly ignore distractor documents that do not help answer the question, simulating imperfect retrieval at test time
Architecture
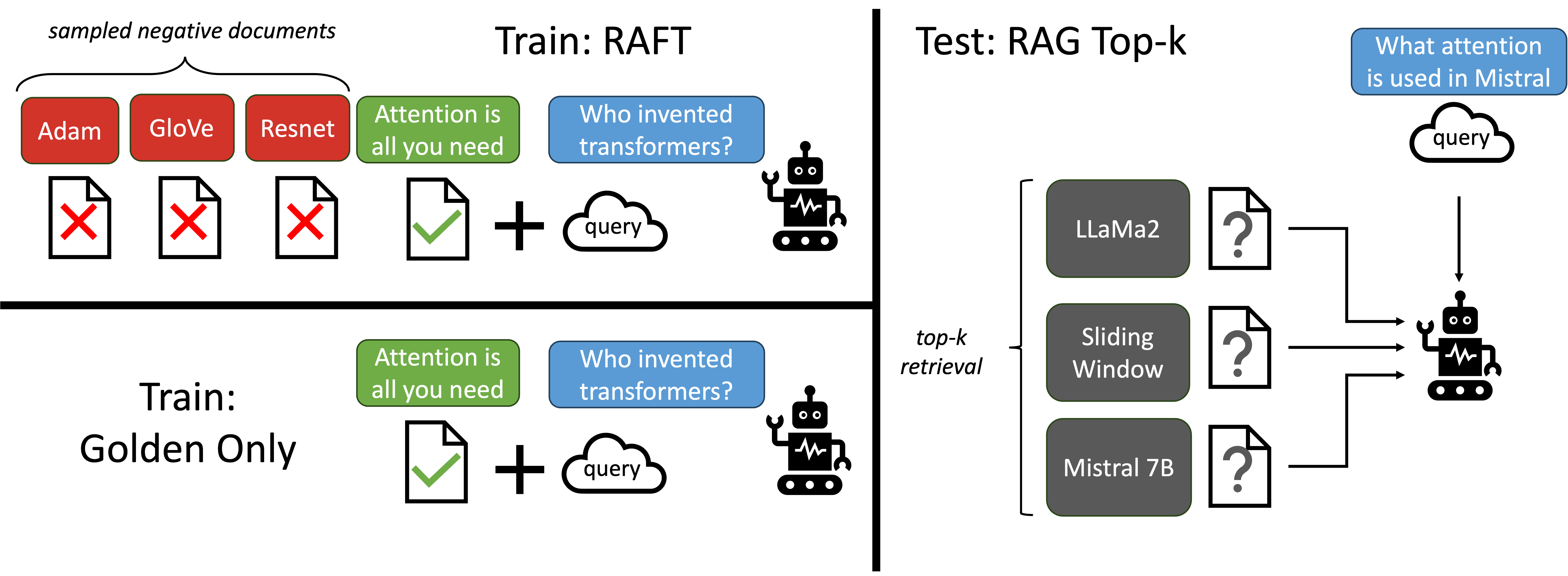
The high-level design principle for RAFT, illustrating the data preparation process where questions are paired with documents (some golden, some distractor) to train the model.
Evaluation Highlights
- +35.25% improvement on HotpotQA compared to Llama2-7B-chat with RAG
- +76.35% improvement on Torch Hub (API documentation) compared to Llama2-7B-chat with RAG
- RAFT outperforms domain-specific fine-tuning (DSF) + RAG by significant margins (e.g., +30.87% on HotpotQA), proving that standard fine-tuning is insufficient for RAG robustness
Breakthrough Assessment
8/10
Simple yet highly effective data construction recipe that bridges the gap between fine-tuning and RAG. Addresses a critical robustness issue (distractors) in practical RAG deployments.