📝 Paper Summary
Modularized RAG pipeline
Efficient Retrieval
This paper proposes three strategies—adaptive retrieval, datastore pruning, and dimension reduction—to speed up k-nearest neighbor language models (kNN-LM) by up to 6x while maintaining performance.
Core Problem
Non-parametric models like kNN-LM require retrieving from massive datastores (billions of tokens) at every generation step, causing significant inference latency and storage overhead.
Why it matters:
- The high computational cost of dense retrieval at every step prevents the deployment of effective non-parametric models in real-world applications
- Storing full-dimension vectors for every token in a large corpus creates unmanageable memory footprints (e.g., hundreds of GBs)
- Retrieval is often unnecessary for easy predictions, yet standard kNN-LM forces costly retrieval operations regardless of difficulty
Concrete Example:
In standard kNN-LM, generating a common word like 'the' triggers a search through a 103-million-entry datastore (WikiText-103), taking ~200ms, whereas the base neural model could predict it instantly without retrieval. This accumulates to prohibitively slow generation speeds (e.g., ~50 tokens/sec vs ~1800 tokens/sec for vanilla LM).
Key Novelty
Efficient kNN-LM via Datastore Pruning and Adaptive Retrieval
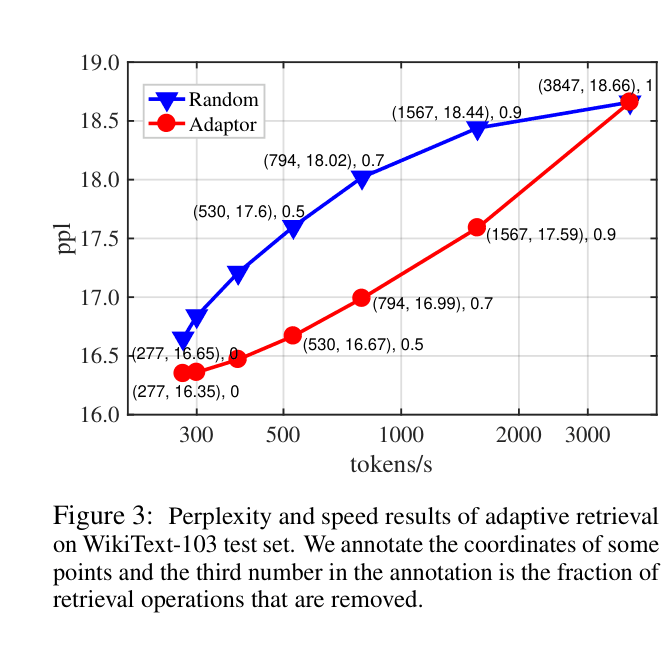
- Adaptive Retrieval: Lightweight classifier decides *when* to retrieve based on the vanilla LM's confidence, skipping retrieval for easy tokens
- Datastore Pruning: Removing redundant datastore entries by clustering vectors and keeping only representative centroids or by selecting tokens where the kNN-LM provides high gain
- Dimension Reduction: Projecting high-dimensional retrieval keys into a lower-dimensional space using PCA to speed up distance calculations
Architecture

Overview of the Efficient kNN-LM pipeline incorporating pruning, dimension reduction, and adaptive retrieval.
Evaluation Highlights
- Achieves up to 6x inference speedup compared to vanilla kNN-LM on WikiText-103 while maintaining comparable perplexity
- Reduces datastore size by 95% (pruning) with negligible performance loss compared to the full datastore
- Adaptive retrieval skips neighbor search for up to 80% of tokens without significant perplexity degradation
Breakthrough Assessment
7/10
Provides practical, effective solutions to the major bottleneck of kNN-LMs (speed/storage). While the techniques (PCA, pruning) are standard, their application and combination in this specific context enable the deployment of previously impractical models.