📝 Paper Summary
Modularized RAG pipeline
Agentic RAG pipeline
LLM-Augmenter iteratively improves a fixed black-box LLM's responses by verifying them against external knowledge and generating automated feedback to revise the prompts until validation passes.
Core Problem
LLMs like ChatGPT suffer from hallucinations due to lossy knowledge encoding and cannot access up-to-date or proprietary data stored in external databases.
Why it matters:
- Hallucinations in mission-critical applications cause damage and erode trust
- Frequent real-world changes make fixed LLM weights quickly stale (e.g., news)
- Fine-tuning massive LLMs for every domain is prohibitively expensive and privacy-invasive
Concrete Example:
When asked about a 2013 LA Galaxy player transfer, a standard LLM might confidently invent a player. LLM-Augmenter retrieves the transfer table, sees the LLM's guess is unsupported, generates feedback ('no info about titles'), and forces the LLM to try again with corrected context.
Key Novelty
Plug-and-Play (PnP) Augmentation with Feedback Loop
- Augments a frozen black-box LLM (ChatGPT) with external modules (Policy, Knowledge Consolidator, Utility) without fine-tuning the LLM itself
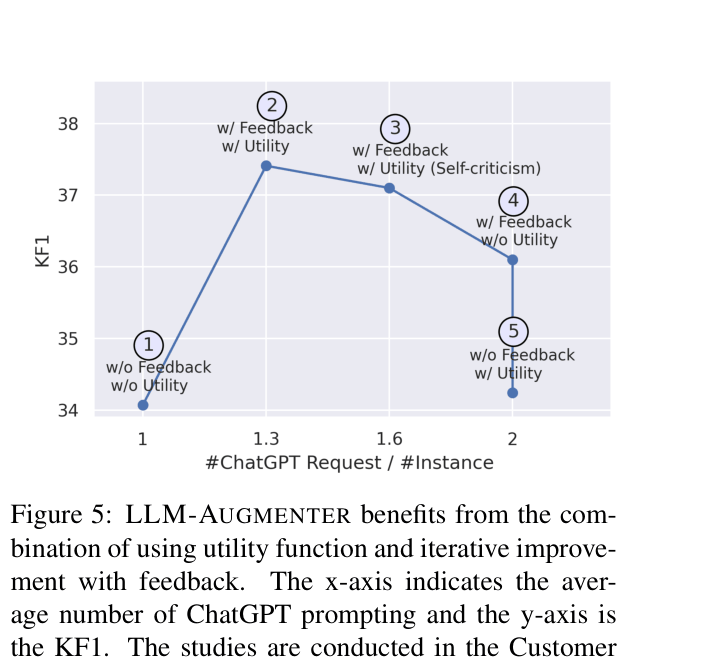
- Introduces an iterative feedback loop where a Utility module critiques the LLM's candidate response against evidence, prompting the LLM to revise its answer if it hallucinates
Architecture
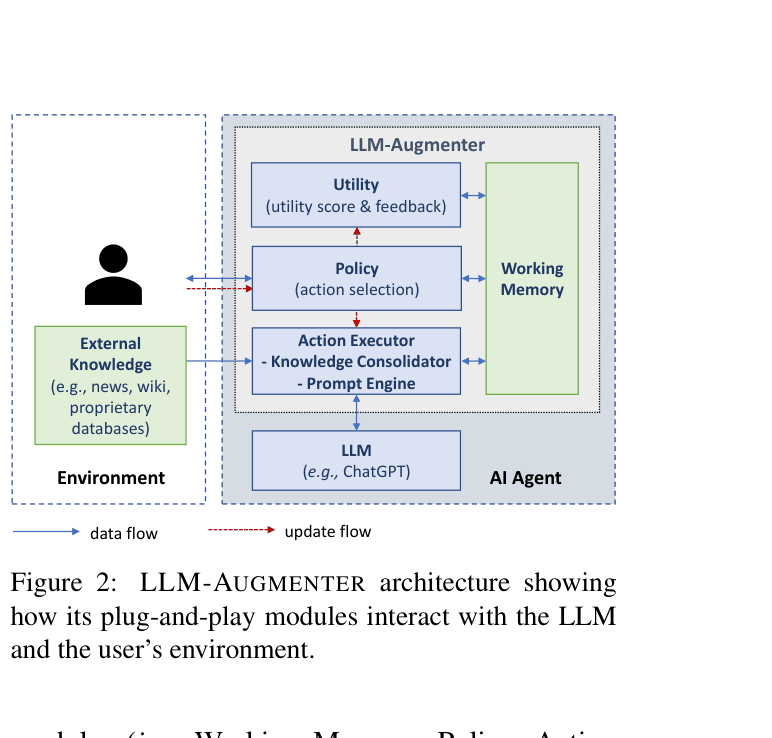
The LLM-Augmenter system architecture illustrating the interaction between the User/Environment and the components: Working Memory, Policy, Action Executor (Knowledge Consolidator + Prompt Engine), Utility, and the fixed LLM.
Evaluation Highlights
- +10.0% F1 improvement on open-domain Wiki QA (OTT-QA) compared to closed-book ChatGPT
- Reduces hallucination significantly: +32.3% improvement in human-rated 'Usefulness' on Customer Service dialogs
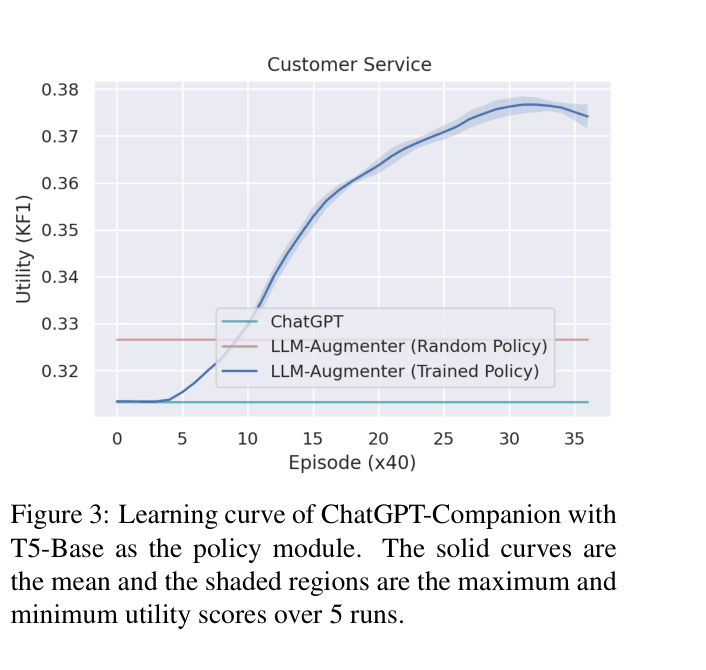
- Policy learning via RL surpasses random baselines, reaching ~37.5 Knowledge F1 on customer service tasks
Breakthrough Assessment
8/10
Significant for being one of the first systems to combine external knowledge retrieval with an iterative verification-feedback loop for black-box LLMs like ChatGPT, explicitly addressing hallucination without fine-tuning.