📝 Paper Summary
Modularized RAG pipeline
Agentic RAG pipeline
IRCoT alternates between generating reasoning steps (Chain-of-Thought) and using those steps as search queries to progressively retrieve missing information for complex questions.
Core Problem
Standard one-step retrieval fails for multi-hop questions because the necessary search terms for later steps only become apparent after partial reasoning on initial evidence.
Why it matters:
- LLMs struggle with open-domain questions where knowledge is not in their parameters or up-to-date
- One-shot retrieval often misses evidence that has no lexical overlap with the original question but is crucial for intermediate reasoning steps
- Without retrieving supporting facts first, models hallucinate reasoning steps; without correct reasoning steps, models cannot retrieve the next necessary fact
Concrete Example:
Question: 'In what country was Lost Gravity manufactured?' Initial retrieval on 'Lost Gravity' finds a roller coaster description but not the country. The model must first infer the manufacturer ('Mack Rides') from the text, then use that new term to retrieve the manufacturing location ('Germany'). One-step retrieval misses this connection.
Key Novelty
Interleaved Retrieval guided by Chain-of-Thought (IRCoT)
- Uses the LLM's generated reasoning sentence as a dynamic search query to find new paragraphs
- Uses the newly retrieved paragraphs to inform the generation of the next reasoning sentence
- This cycle repeats until the answer is found, allowing retrieval and reasoning to guide each other step-by-step
Architecture
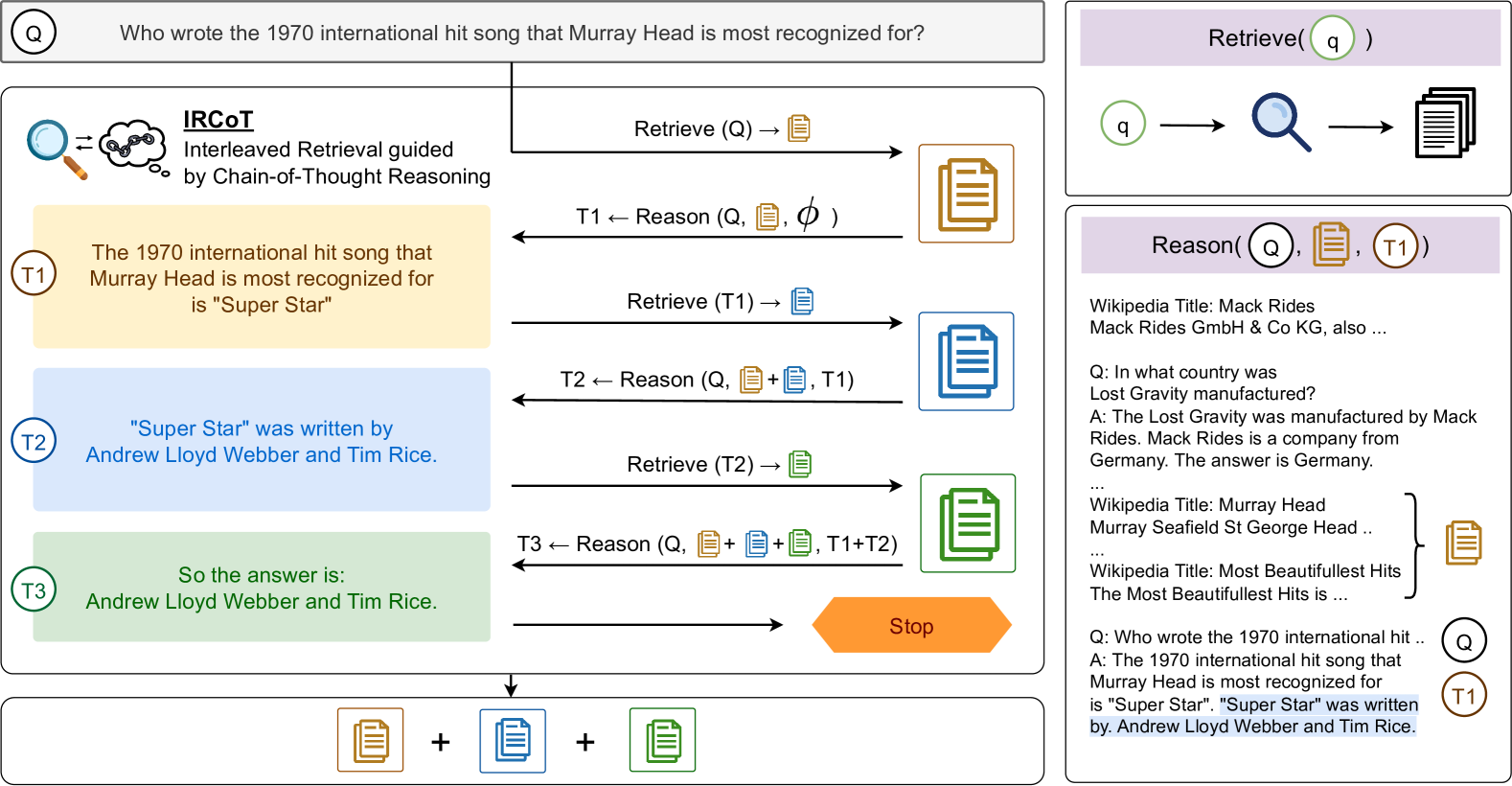
Overview of the IRCoT method compared to standard one-step retrieval
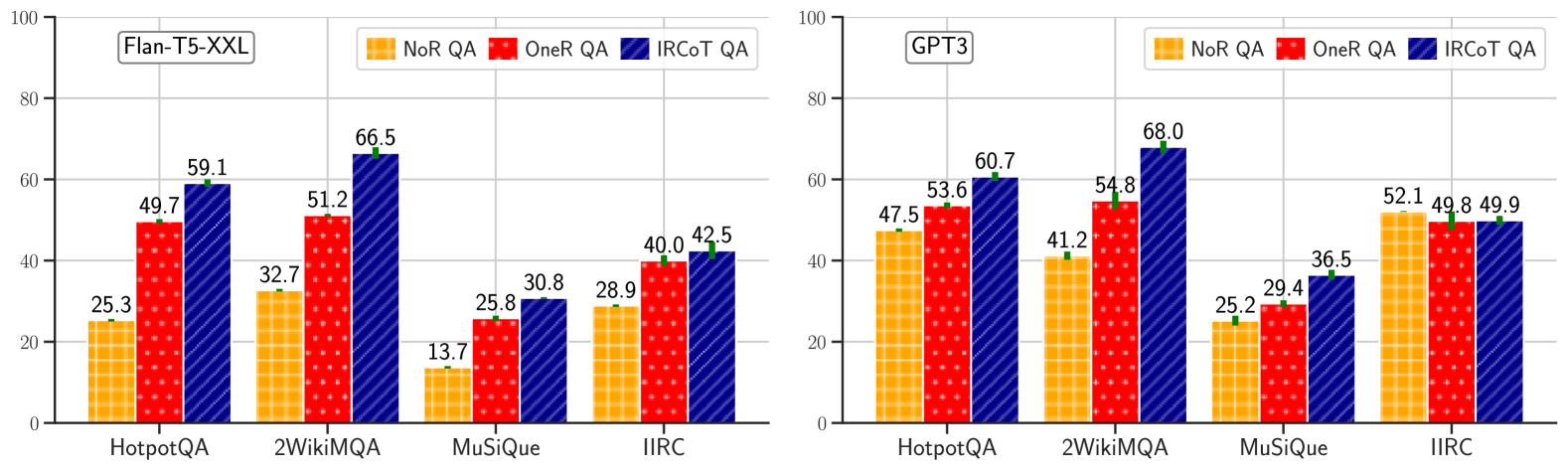
Evaluation Highlights
- Improves retrieval recall by 11-21 points over one-step retrieval baselines on datasets like HotpotQA and 2WikiMultihopQA
- Boosts downstream few-shot QA performance by up to 15 F1 points using GPT-3 (code-davinci-002)
- Reduces factual errors in generated Chain-of-Thought reasoning by up to 50% compared to baselines
- Smaller model (Flan-T5-XL, 3B) with IRCoT outperforms a 58x larger GPT-3 model using standard one-step retrieval
Breakthrough Assessment
9/10
Significantly advances few-shot multi-step QA by solving the disconnect between static retrieval and dynamic reasoning. Demonstrated efficacy across model sizes (3B to 175B) and OOD settings without training.