📝 Paper Summary
Agentic RAG pipeline
Modularized RAG pipeline
FLARE improves long-form generation by iteratively anticipating future content, using low-confidence tokens in that anticipation to trigger retrieval, and regenerating the sentence with retrieved context.
Core Problem
Standard RAG methods retrieve only once before generation (insufficient for long texts) or passively retrieve at fixed intervals (often irrelevant or unnecessary), failing to capture evolving information needs during long-form generation.
Why it matters:
- Single-time retrieval fails for long-form tasks (e.g., summaries, essays) where information needs shift as the text progresses
- Passive multi-time retrieval (e.g., every 16 tokens) is inefficient and often retrieves irrelevant information based on past context rather than future intent
- Large Language Models (LLMs) still hallucinate facts when generating long content without access to updated or specific external knowledge
Concrete Example:
When generating a summary for 'Joe Biden', a model might correctly state his birth date but hallucinate the date of his 2020 campaign announcement later in the text because the initial retrieval only covered general biography facts, not specific campaign details needed mid-generation.
Key Novelty
Forward-Looking Active REtrieval (FLARE)
- Anticipates future information needs by generating a temporary 'hypothetical' next sentence without retrieval
- Triggers retrieval ONLY if this hypothetical sentence contains low-confidence tokens (indicating a lack of knowledge)
- Uses the hypothetical sentence itself (or questions derived from it) as the search query to fetch relevant documents before regenerating the actual sentence
Architecture
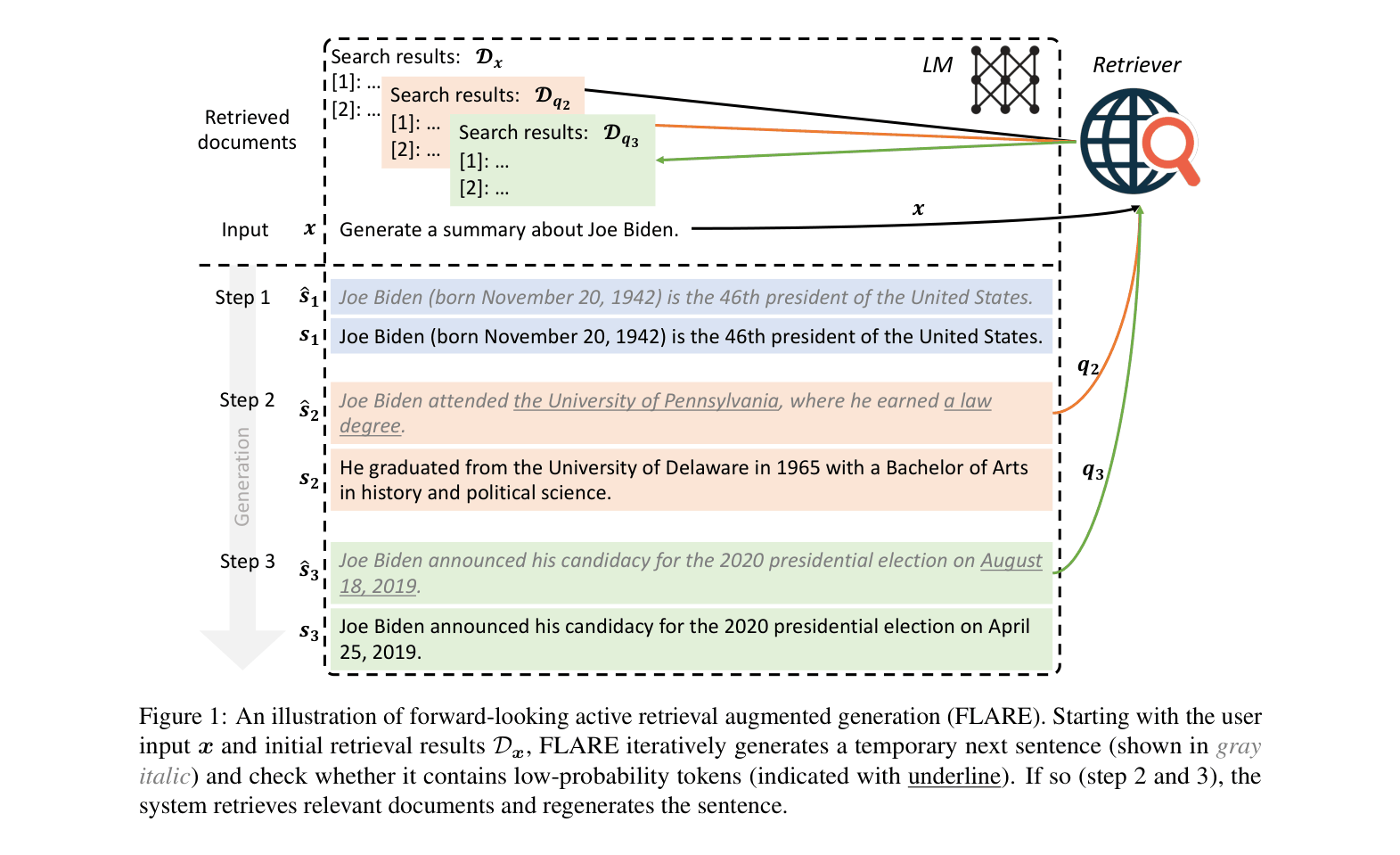
The FLARE workflow showing the iterative process of generating a temporary sentence, checking for low-confidence tokens, retrieving documents if needed, and regenerating.
Evaluation Highlights
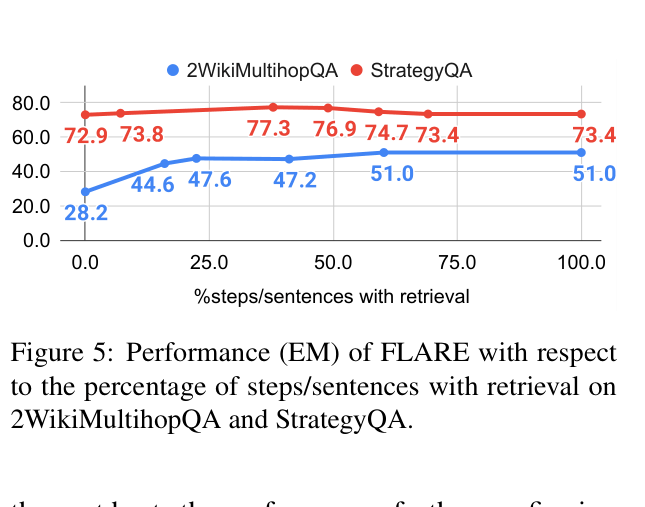
- +11.6% Exact Match (EM) improvement on 2WikiMultihopQA compared to single-time retrieval baselines
- Outperforms passive multi-time retrieval (retrieving every sentence) by +2.0% EM on 2WikiMultihopQA while being more efficient
- Achieves superior performance across 4 diverse long-form tasks including Multihop QA, Commonsense Reasoning, and Open-domain Summarization
Breakthrough Assessment
8/10
Introduces a highly intuitive 'active' paradigm that links model confidence to retrieval actions. Significantly improves long-form generation reliability without retraining the base LM.