📝 Paper Summary
Modularized RAG pipeline
Agentic RAG pipeline
DRAGIN dynamically decides when and what to retrieve during generation by calculating the LLM's real-time information needs using uncertainty, token importance, and self-attention patterns.
Core Problem
Existing dynamic RAG methods rely on static rules or limited context (last sentence) to trigger retrieval, failing to capture the model's actual real-time information needs.
Why it matters:
- Static rules (e.g., every 4 tokens) trigger unnecessary retrieval, increasing computational cost and introducing noise that jeopardizes output quality
- Querying based only on the most recent sentence misses global context, leading to suboptimal retrieval for complex tasks where needs span the entire history
Concrete Example:
When generating a biography for Einstein, the model might mention '1903'. A standard method might just query '1903', retrieving irrelevant dates. DRAGIN detects the need for 'job' context and formulates a query like 'Einstein 1903 secured job' by attending to previous relevant tokens.
Key Novelty
Real-time Information Needs Detection (RIND) & Query Formulation based on Self-attention (QFS)
- RIND triggers retrieval by calculating a composite score of a token's uncertainty (entropy), its influence on future tokens (attention), and its semantic importance
- QFS constructs queries by selecting the top-k most attended tokens from the entire preceding context, rather than just using the most recent sentence
Architecture
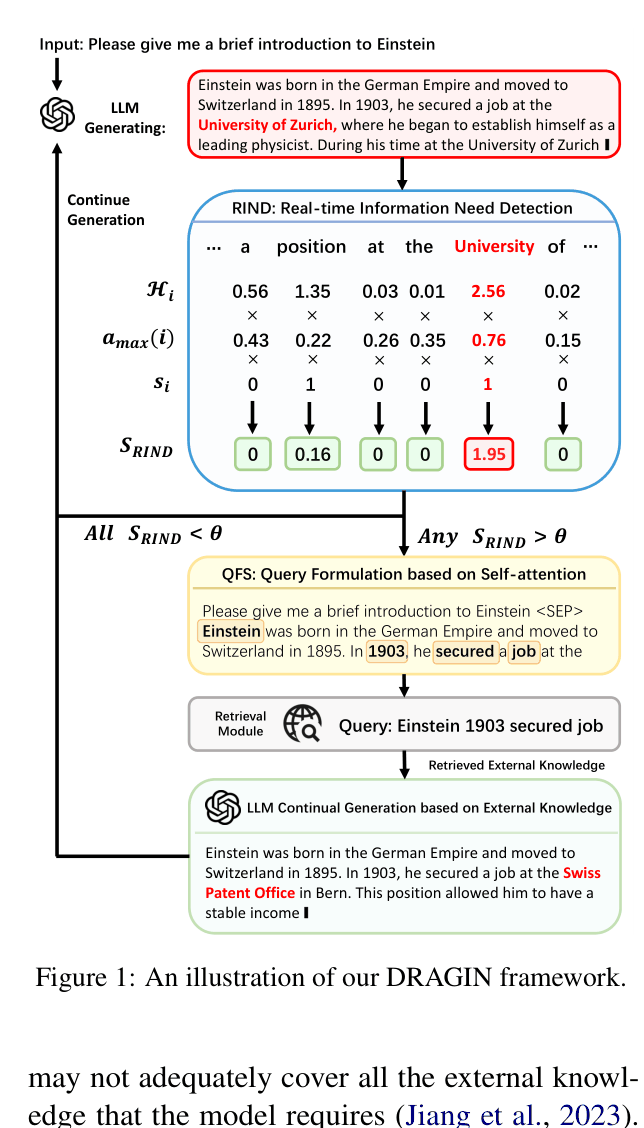
The DRAGIN framework workflow illustrating the interaction between the LLM generation, RIND detection, and QFS query formulation.
Evaluation Highlights
- +22.7% F1 improvement over Single-Round RAG on HotpotQA using LLaMA-2-13B-Chat
- +22.1% F1 improvement over FLARE on 2WikiMultihopQA using LLaMA-2-13B-Chat
- Achieves higher performance with fewer retrieval calls compared to fixed-interval methods (e.g., ~2.6 calls vs 3.7 for FL-RAG on 2WikiMultihopQA)
Breakthrough Assessment
7/10
Significant improvement over baselines like FLARE by leveraging internal model states (attention/entropy) for RAG timing. Highly effective but relies on access to attention weights, limiting use with closed-source APIs.