📝 Paper Summary
Modularized RAG pipeline
REALM pre-trains a language model and a neural retriever jointly from scratch by treating retrieved documents as latent variables and maximizing the marginal likelihood of masked tokens.
Core Problem
Standard language models like BERT store world knowledge implicitly in fixed parameters, requiring massive scaling to learn more facts and lacking interpretability.
Why it matters:
- Implicit knowledge storage limits model capacity; increasing knowledge requires training ever-larger networks which is computationally expensive
- Parameter-based knowledge is opaque (hard to interpret where facts come from) and static (hard to update without re-training)
- Previous retrieval-augmented approaches used fixed, heuristic retrievers (like TF-IDF) that couldn't learn to find better documents during pre-training
Concrete Example:
To predict 'The [MASK] is the currency of the UK', a standard LM must memorize 'pound' in its weights. REALM instead retrieves a document containing 'The pound is the currency...', making the prediction easier and traceable.
Key Novelty
Latent Variable Pre-training for Neural Retrieval
- Treats the retrieval step as a latent variable in a generative process: the model samples a document, then predicts missing tokens based on it
- Backpropagates the language modeling loss through the retrieval decision, rewarding the retriever when selected documents help predict the correct token
- Refreshes the retrieval index asynchronously during pre-training, allowing the retriever to evolve and index millions of documents without stalling the training loop
Architecture
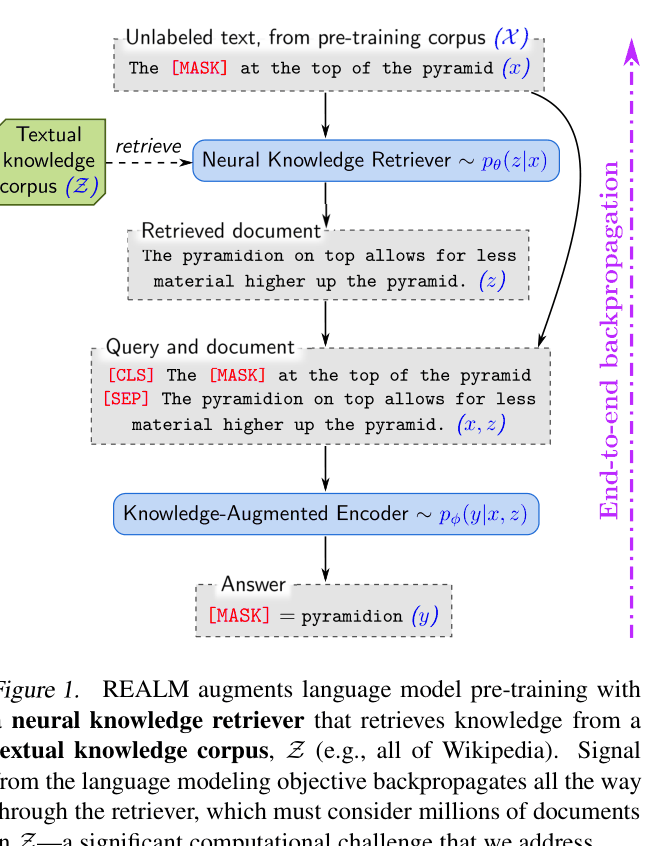
The REALM framework: unsupervised pre-training loop where the retriever and encoder are jointly optimized via backpropagation through the retrieved documents.
Evaluation Highlights
- +3.8% to +5.9% accuracy improvement over state-of-the-art retrieval models (ORQA) on NaturalQuestions-Open
- Outperforms the massive T5-11B model (11 billion parameters) on Open-QA while being ~30x smaller (330M parameters)
- Achieves 40.4% exact match on NaturalQuestions using CC-News as the pre-training corpus, showing it can learn from corpora distinct from the knowledge base
Breakthrough Assessment
9/10
A foundational paper that introduced end-to-end pre-training for neural retrievers. It established that retrieval can be learned from unsupervised signal, significantly influencing modern RAG architectures.