📝 Paper Summary
Modularized RAG pipeline
Open Domain Question Answering
Fusion-in-Decoder (FiD) processes retrieved passages independently in the encoder but jointly in the decoder, allowing generative models to scale efficiently to large numbers of supporting documents.
Core Problem
Existing generative approaches for open-domain QA require massive parameters to store knowledge, while extractive approaches struggle to aggregate evidence from multiple passages effectively.
Why it matters:
- Purely generative models (like GPT-3) are expensive to train and query because knowledge must be stored in weights
- Extractive models (like DrQA) often fail to combine information distributed across multiple documents
- Previous retrieval-augmented generative models were computationally expensive (quadratic complexity) when scaling to many retrieved passages
Concrete Example:
When answering 'Where was Alan Turing born?', a standard model might need to read 100 passages. If it concatenates them all into one long input, the self-attention mechanism becomes prohibitively slow (quadratic cost), limiting how much evidence can be used.
Key Novelty
Fusion-in-Decoder (FiD)
- Encodes each retrieved passage (paired with the question) independently to keep computational cost linear with the number of passages
- Fuses the information only during the decoding step, where the decoder attends to the concatenation of all encoder outputs jointly to generate the answer
Architecture
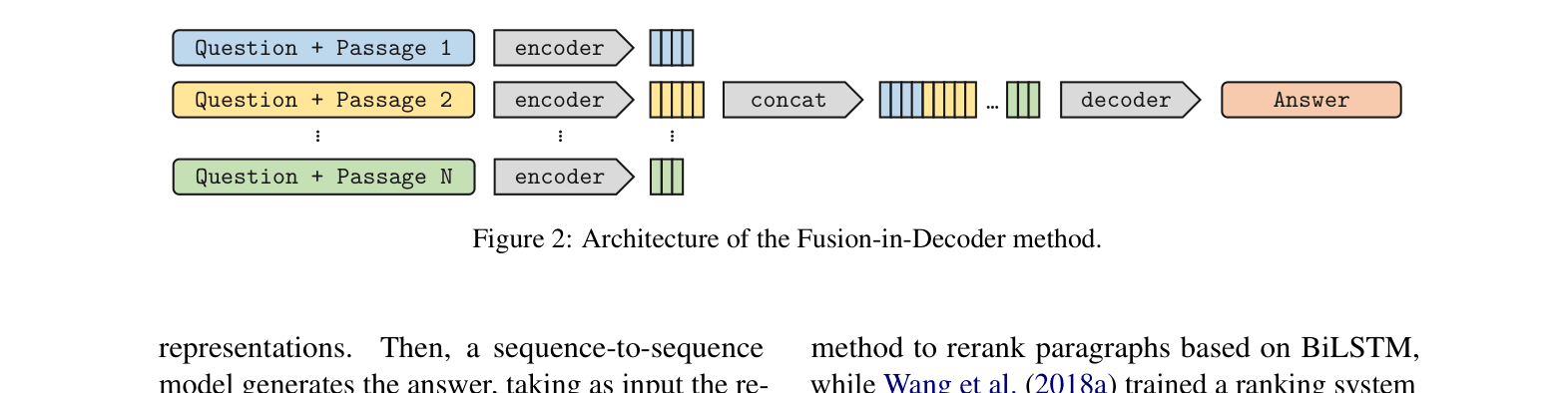
The architecture of the Fusion-in-Decoder method.
Evaluation Highlights
- Achieves 51.4% Exact Match on NaturalQuestions with the large model, outperforming RAG (44.5%) and T5 (36.6%)
- Achieves 67.6% Exact Match on TriviaQA, surpassing state-of-the-art extractive and generative baselines
- Scaling the number of retrieved passages from 10 to 100 leads to significant performance gains (+6% on TriviaQA), unlike extractive models which plateau early
Breakthrough Assessment
9/10
This paper introduced the standard architecture for high-performance generative reader models. FiD became the default baseline for evidence fusion in RAG due to its simplicity and scalability.