📝 Paper Summary
Modularized RAG pipeline
Open-domain dialogue
Internet-augmented generation
SeeKeR decomposes open-domain generation into three sequential modular tasks (search, knowledge generation, response generation) handled by a single transformer to incorporate up-to-date internet information.
Core Problem
Large language models hallucinate facts, have outdated knowledge frozen at training time, and struggle to aggregate information from multiple retrieved documents into coherent responses.
Why it matters:
- Standard LMs cannot learn new facts after training, making them useless for current events
- Existing retrieval models (like FiD) often mix facts incorrectly or generate generic responses that ignore retrieved content
- Black-box retrieval systems (like LaMDA) are not openly available for research comparison
Concrete Example:
When asked about 'Beyonce 2022', a standard model might hallucinate based on old data. SeeKeR generates a search query, retrieves a news snippet about her album release, extracts that specific fact, and then generates a response incorporating it.
Key Novelty
SeeKeR (Search-engine -> Knowledge -> Response)
- Decomposes the generation process into three explicit steps: generating a search query, generating/copying a knowledge span from search results, and generating the final response
- Uses a single transformer model iteratively for all three modules, feeding the output of one as input to the next
- Applies this modular approach to both dialogue (finding relevant facts for conversation) and prompt completion (finding up-to-date news)
Architecture
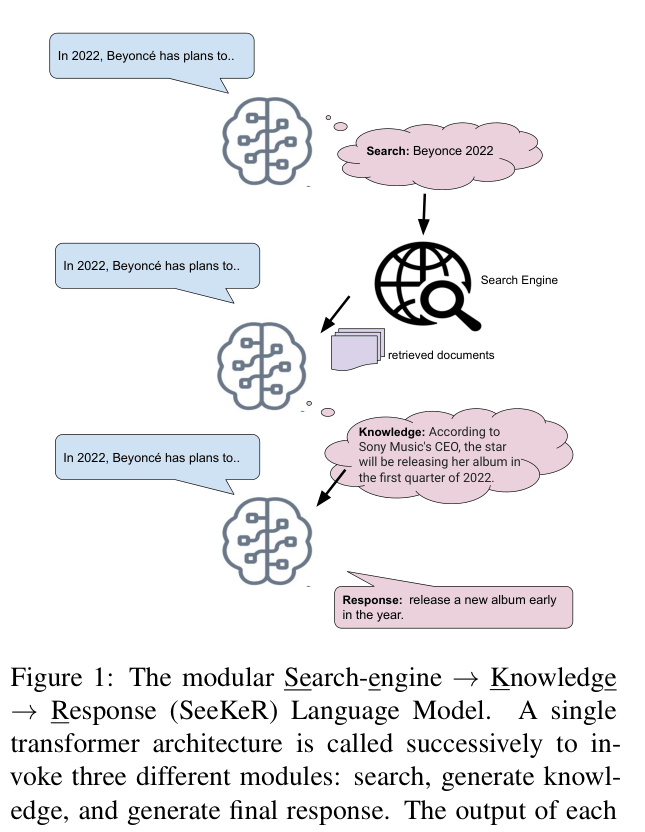
The modular SeeKeR architecture where a single transformer is invoked three times sequentially.
Evaluation Highlights
- Outperforms BlenderBot 2 (3B) on consistency (78.5% vs 65.1%) and knowledge (46.5% vs 27.9%) in human evaluations
- Reduces hallucinations on topical prompts compared to GPT2-XL (1.5B), improving 'True' ratings from 14% to 43%
- Surpasses GPT3 (175B) in topicality (15-19% vs 4%) and hallucination reduction (58% vs 62% false) on current events prompts despite being 500x smaller
Breakthrough Assessment
8/10
Strong empirical results showing that a modular search-and-generate approach allows much smaller models to outperform giant models (GPT3) on topical accuracy. The decomposition strategy effectively addresses the 'hallucination vs. outdated knowledge' trade-off.