📝 Paper Summary
Web agents
Agentic RAG pipeline
WebGPT fine-tunes GPT-3 to answer long-form questions by interacting with a text-based web browser, optimizing for human preference and factual accuracy via imitation learning and rejection sampling.
Core Problem
Language models struggle with long-form question answering (LFQA) because they hallucinate facts and lack up-to-date information, while existing retrieval methods often fail to synthesize information effectively.
Why it matters:
- LFQA systems lag behind human performance despite their potential to replace traditional search engines
- Current systems either have poor retrieval or poor synthesis; combining them effectively is difficult
- Evaluating factual accuracy without citations is extremely difficult and subjective for human labelers
Concrete Example:
When asked 'What happens if you smash a mirror?', GPT-3 (QA prompt) answers 'If you smash a mirror, you will have seven years of bad luck,' reproducing a misconception. WebGPT searches the web and correctly answers 'When you break a mirror you might cut yourself...'
Key Novelty
Browser-assisted QA with Human Feedback
- Creates a text-based web-browsing environment where a language model can issue commands (Search, Click, Quote) to gather information
- Uses references (quotes extracted by the model) to allow human labelers to objectively judge factual accuracy
- Combines imitation learning from human demonstrations with rejection sampling against a reward model trained on human preferences
Architecture

The text-based browsing environment as seen by humans (GUI) vs the model (Text). It illustrates the observation format including the question, quotes, past actions, and the simplified text of the current webpage.
Evaluation Highlights
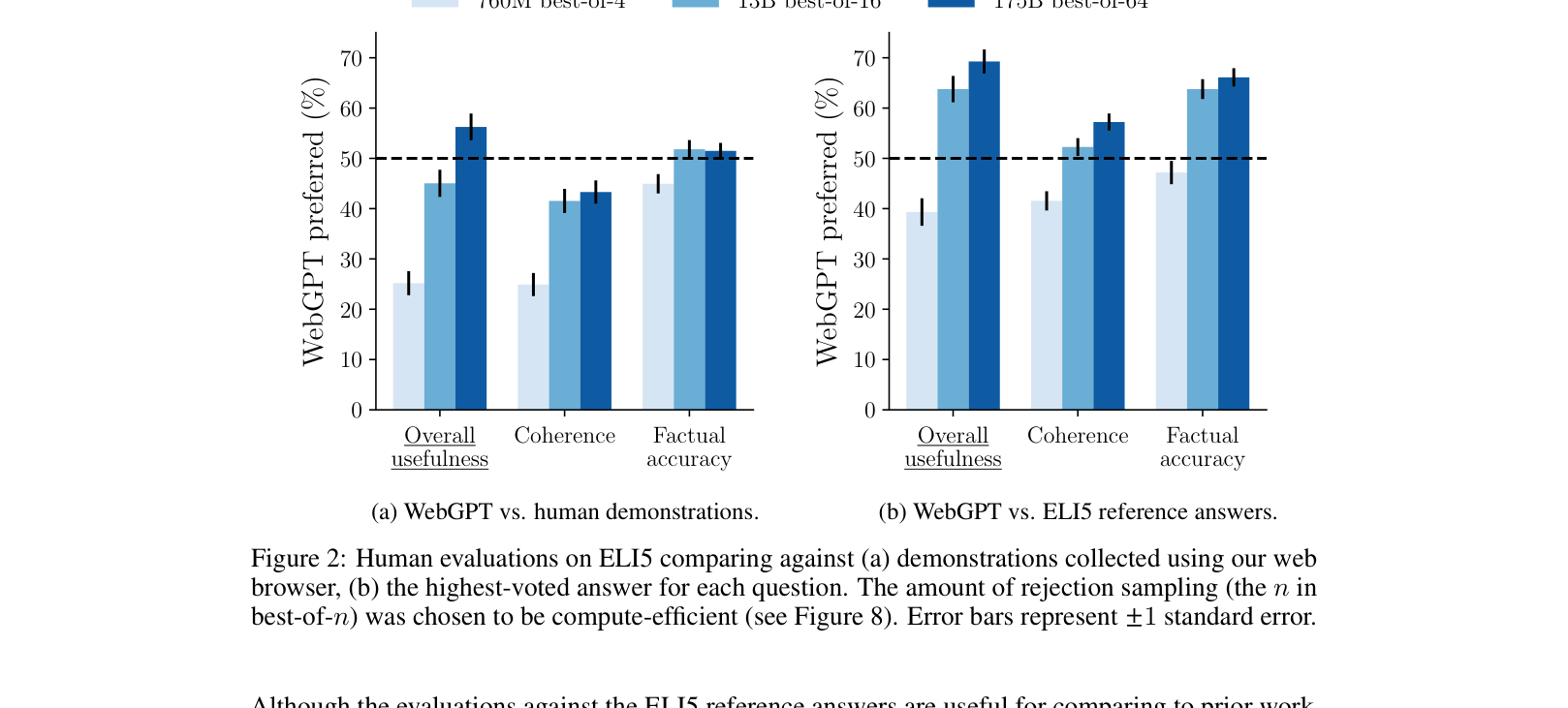
- WebGPT 175B (best-of-64) answers are preferred to human expert demonstrations 56% of the time on ELI5
- WebGPT answers are preferred to the highest-voted Reddit answers 69% of the time on ELI5
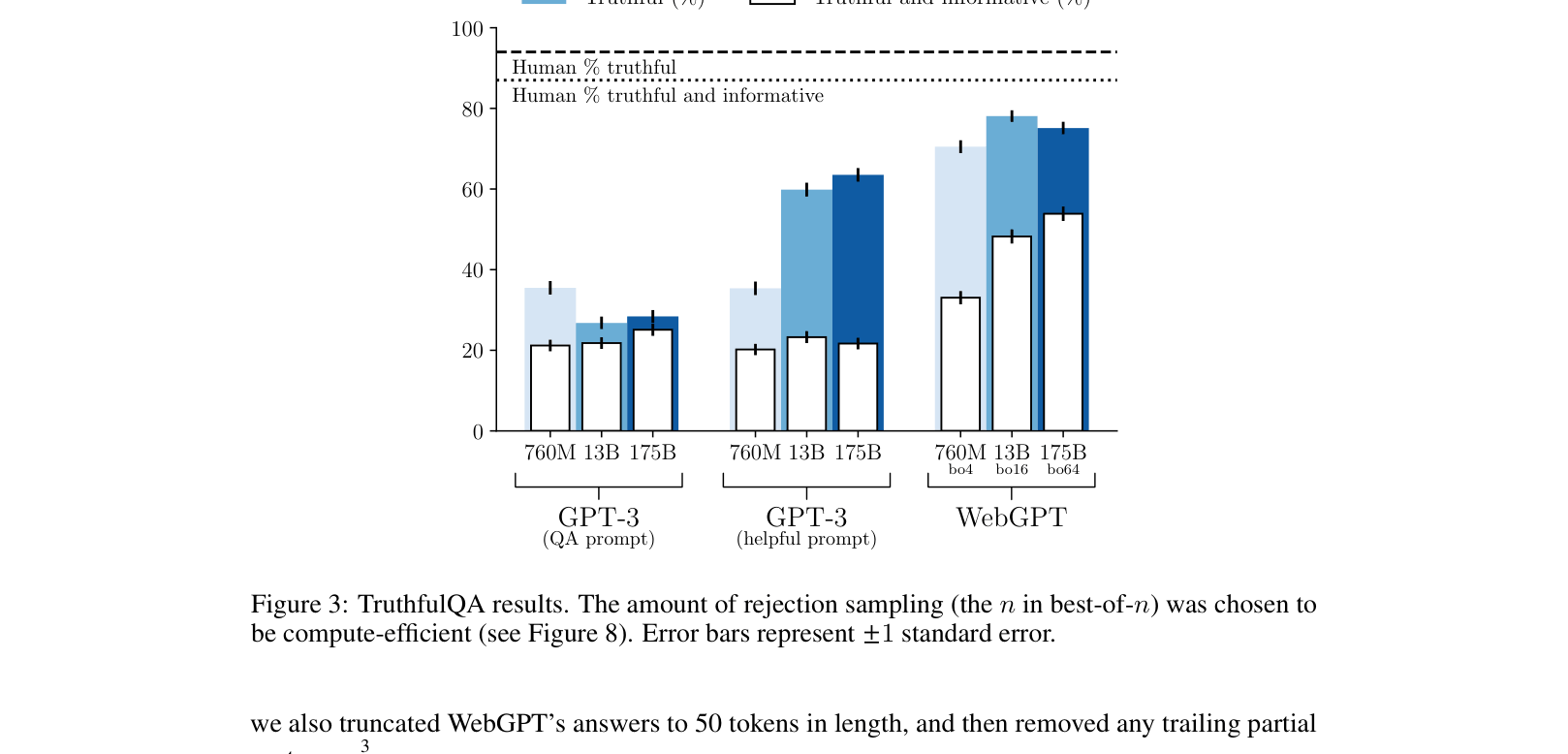
- Outperforms GPT-3 on TruthfulQA: 75% truthful answers vs GPT-3's baseline (lower performance not explicitly quantified in summary text but visible in plots)
Breakthrough Assessment
9/10
A seminal paper establishing the paradigm for web-browsing agents. It demonstrated that LLMs can effectively use tools to cite sources and beat human performance on open-ended QA via RLHF.