📝 Paper Summary
Internalization through pre-training and mid-training
Factuality analysis via training data statistics
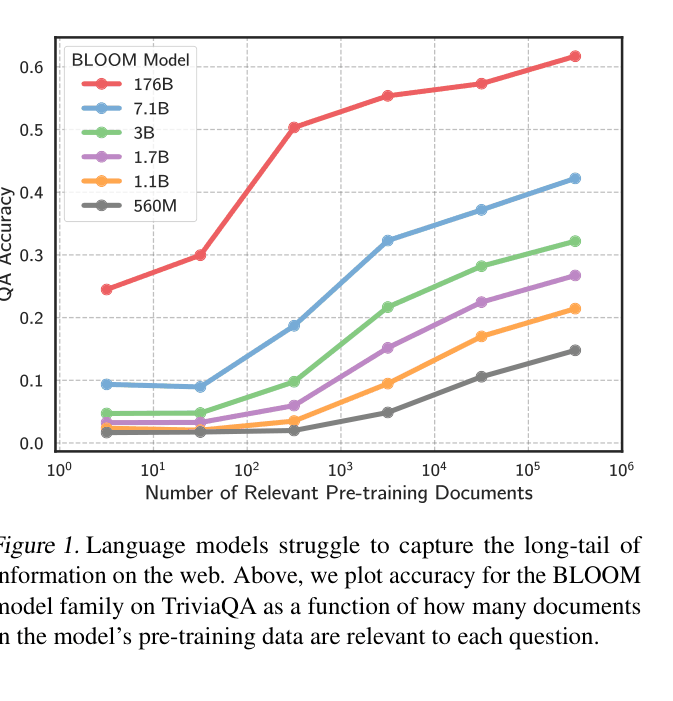
LLM accuracy on factual questions is causally determined by the number of times the relevant fact appears in the pre-training corpus, making rare knowledge inherently difficult to learn via scaling alone.
Core Problem
It is unclear why LLMs succeed on some factual questions but fail on others, and whether they can effectively learn 'long-tail' knowledge that appears rarely in pre-training data.
Why it matters:
- Understanding the source of LLM capabilities is crucial for predicting performance and limitations on downstream tasks
- Blindly scaling model size or data size may be inefficient if the underlying relationship between data frequency and accuracy is log-linear
- Identifying failure modes for rare facts motivates architectural changes like retrieval augmentation over simple scaling
Concrete Example:
For the question 'In what city was the poet Dante born?', an LLM might answer correctly if 'Dante' and 'Florence' co-occur frequently in its training data (e.g., >100 times), but fail if they co-occur rarely (<10 times), despite knowing who Dante is.
Key Novelty
Entity-Linked Document Counting Analysis
- Systematically counts 'relevant documents' in massive pre-training corpora (e.g., The Pile, C4) by finding co-occurrences of question and answer entities (e.g., 'Dante' + 'Florence')
- Establishes a causal link (not just correlation) between these counts and QA accuracy by re-training a model on a dataset where specific relevant documents were deleted
Architecture
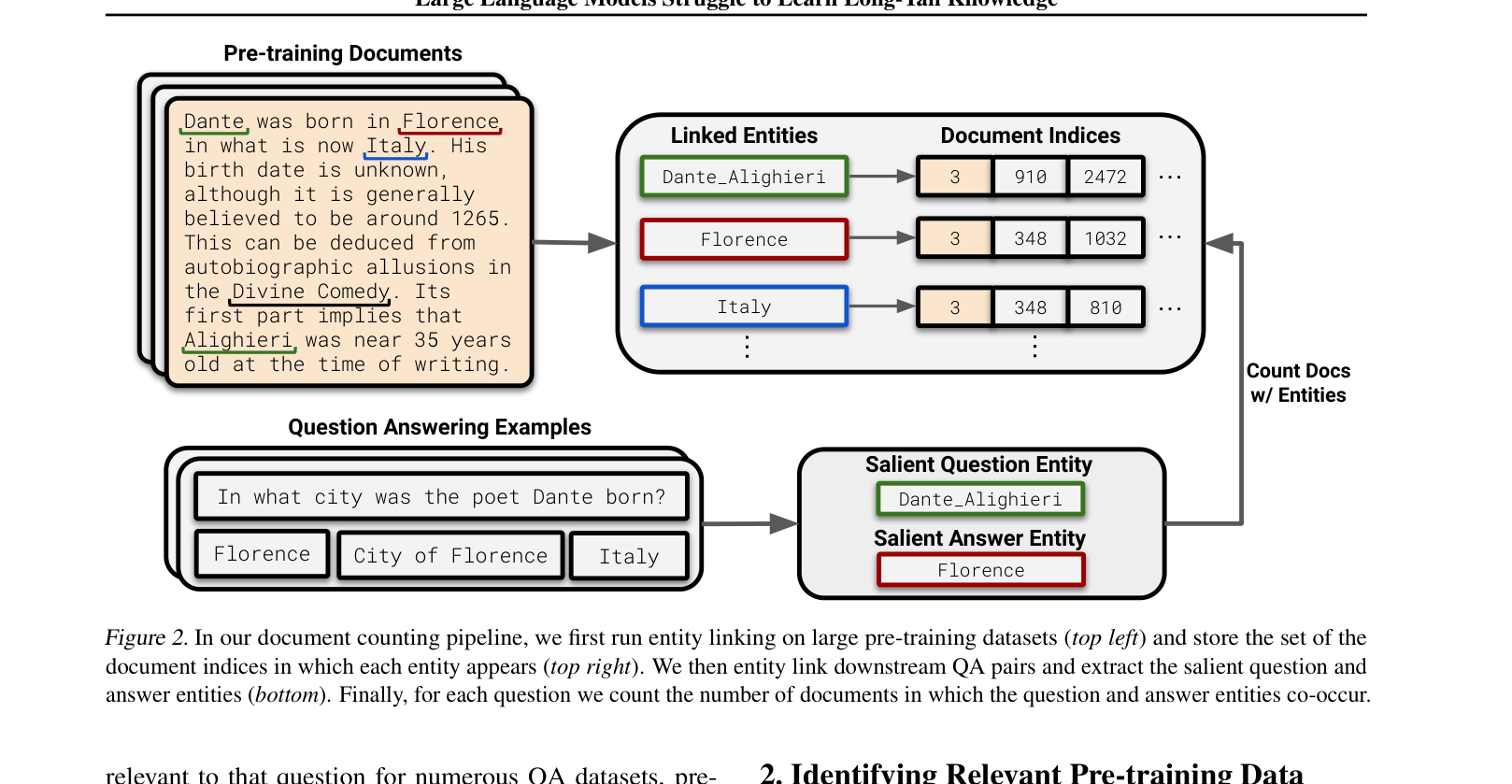
The pipeline for identifying relevant documents using entity linking.
Evaluation Highlights
- BLOOM-176B accuracy on TriviaQA jumps from ~25% to >55% as relevant pre-training documents increase from 100 to 10,000
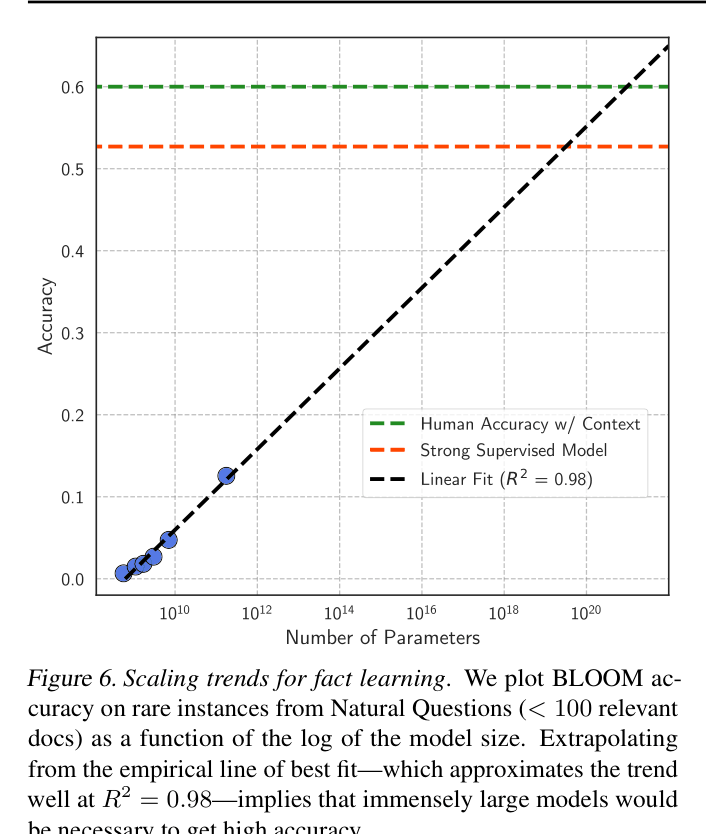
- Scaling laws indicate a model would need 10^18 (one quintillion) parameters to reach competitive accuracy on rare facts (<100 documents)
- Retrieval augmentation (BM25) significantly boosts accuracy on rare facts, breaking the dependence on pre-training frequency
Breakthrough Assessment
9/10
A foundational study that quantitatively explains 'why' LLMs know what they know. The finding that scaling is a log-linear dead end for rare facts is a crucial insight for the field.