📝 Paper Summary
Modularized RAG pipeline
RAG triggering
Large language models struggle to memorize long-tail factual knowledge, but a simple adaptive method can predict when to retrieve external information based on entity popularity, improving efficiency and accuracy.
Core Problem
LMs fail to encode long-tail factual knowledge in their parameters, and scaling model size does not significantly improve performance on less popular entities.
Why it matters:
- Relying solely on parametric memory requires prohibitively large models, yet knowledge still becomes obsolete or hallucinatory for rare entities
- Always retrieving external knowledge is computationally expensive and can hurt performance on popular questions where the model already knows the answer (due to misleading retrieval contexts)
Concrete Example:
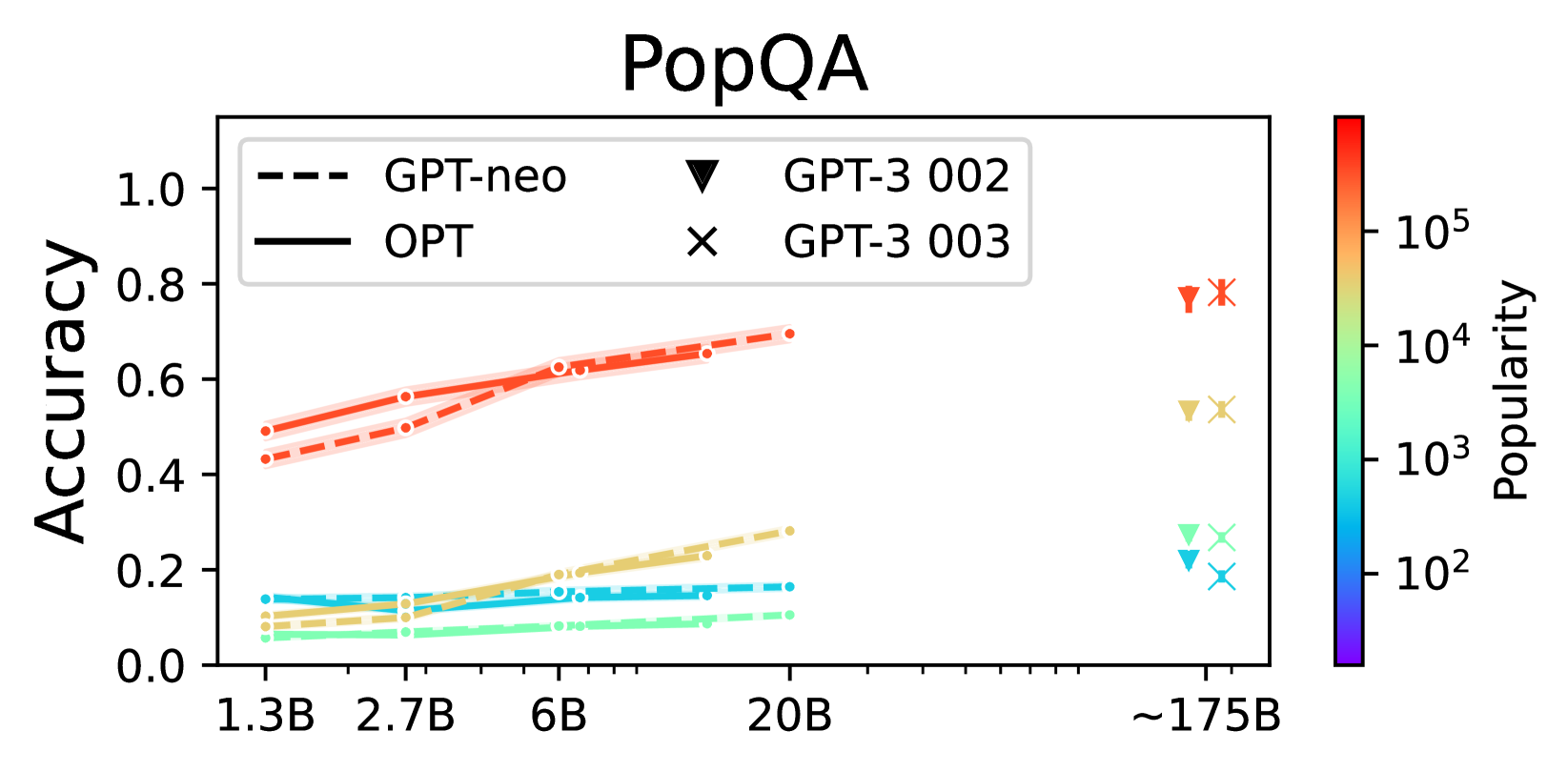
For the 4,000 least popular questions in PopQA, scaling from GPT-Neo 6B to GPT-3 davinci-003 only improves accuracy from 16% to 19%, whereas retrieval augmentation can boost it significantly.
Key Novelty
Adaptive Retrieval based on Entity Popularity
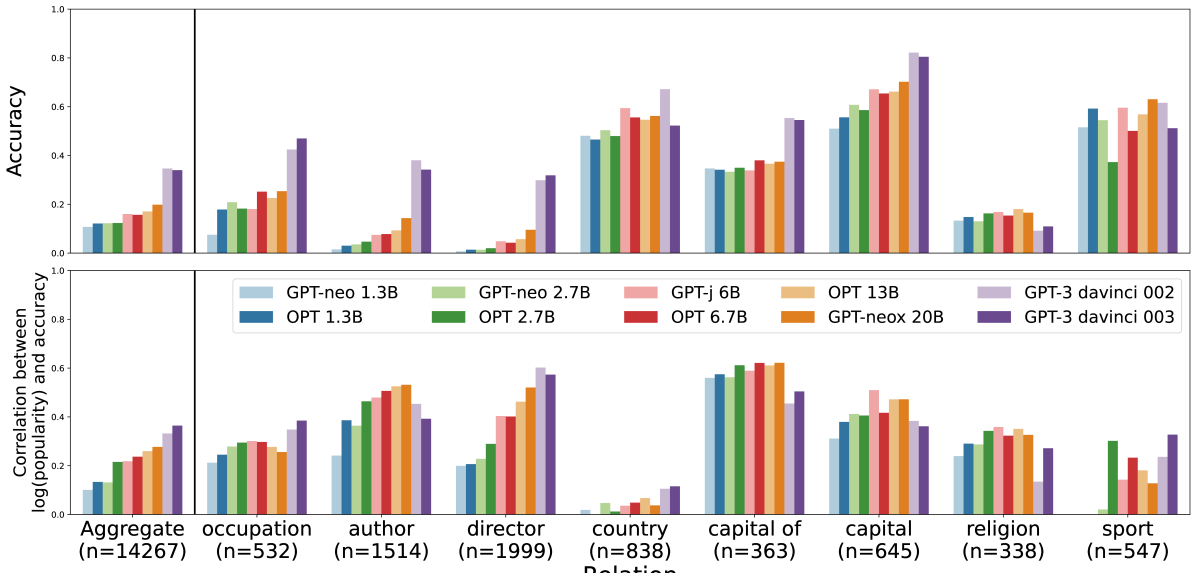
- Identifies a strong correlation between subject entity popularity (measured by Wikipedia page views) and LM memorization accuracy
- Proposes a threshold-based system: if the entity in the question is popular, use the LM's internal memory; if it is rare (long-tail), trigger retrieval
- Introduces PopQA, a new dataset specifically designed to probe knowledge across a wide spectrum of entity popularities
Architecture
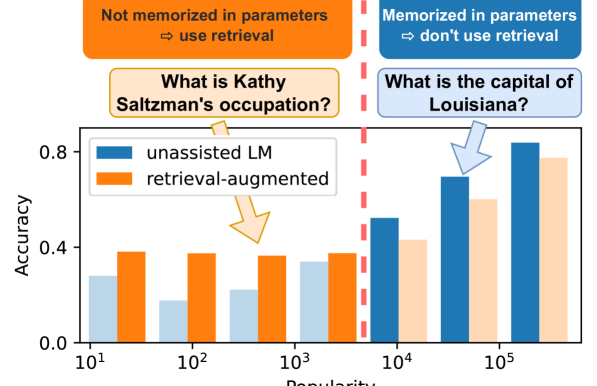
Conceptual flowchart of Adaptive Retrieval (text-based reconstruction)
Evaluation Highlights
- Retrieval-augmented GPT-Neo 2.7B outperforms GPT-3 davinci-003 on the 4,000 least popular PopQA questions
- Adaptive Retrieval improves PopQA accuracy by up to 10% compared to non-retrieval baselines while reducing inference costs
- Scaling model size (from 1.3B to 175B) yields negligible improvement on long-tail questions (staying below 20% accuracy for the least popular bin)
Breakthrough Assessment
8/10
Provides crucial empirical evidence that scaling laws don't apply to long-tail fact memorization and offers a practical, efficient solution (Adaptive Retrieval) that balances cost and accuracy.