📝 Paper Summary
Modularized RAG pipeline
Factuality and hallucination
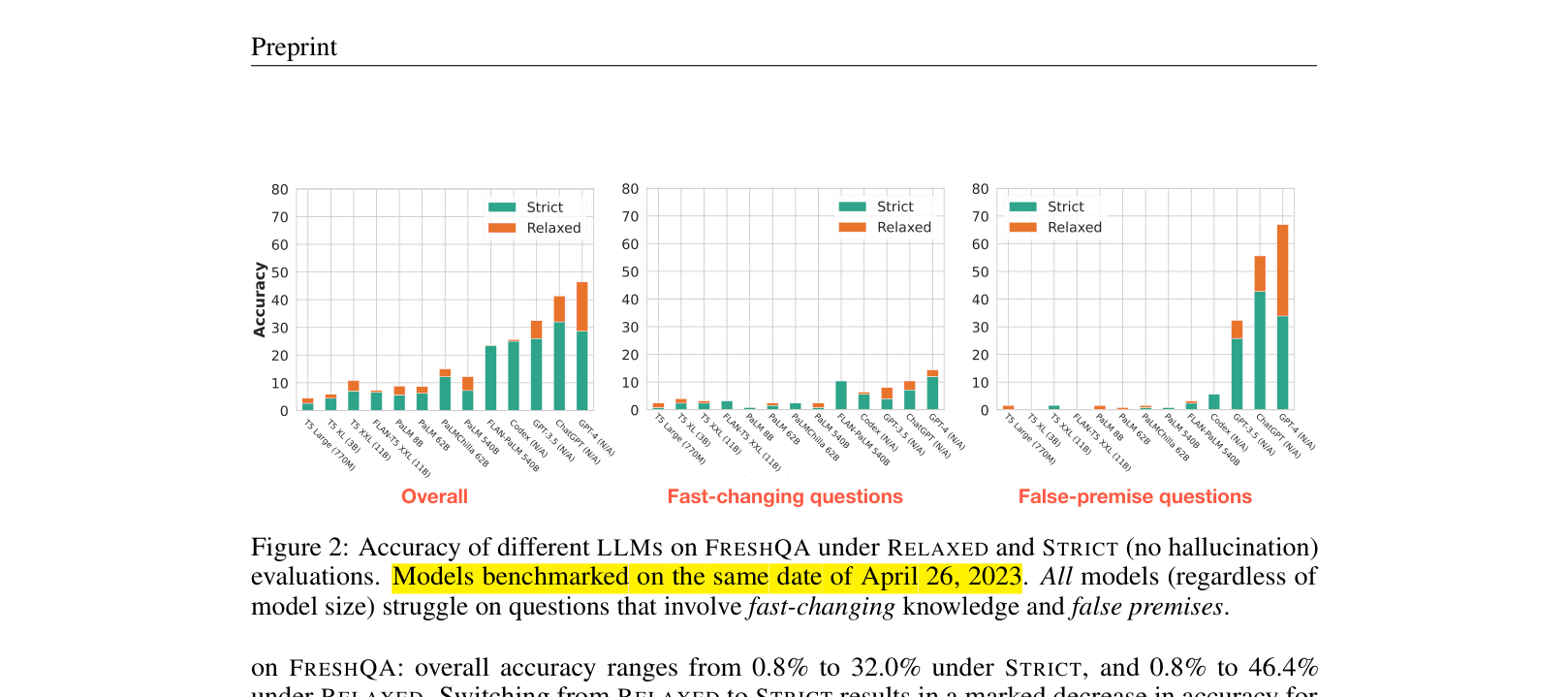
The paper introduces a dynamic QA benchmark for evaluating LLM factuality on changing world knowledge and proposes a few-shot prompting method that incorporates search engine results to significantly improve accuracy.
Core Problem
Most Large Language Models (LLMs) are trained once and lack the ability to adapt to fast-changing world knowledge, leading to hallucinations or outdated answers.
Why it matters:
- Models like ChatGPT and GPT-4 often hallucinate plausible but incorrect information, reducing trustworthiness in settings requiring up-to-date accuracy
- Retraining models to update knowledge is not easily scalable for real-time information (e.g., stock prices)
- Existing benchmarks do not adequately test dynamic, fast-changing knowledge or the ability to debunk false premises
Concrete Example:
When asked 'Which game won the Spiel des Jahres award most recently?', a model trained in 2021 might answer 'MicroMacro: Crime City' (the 2021 winner) instead of the current winner, or refuse to answer due to a knowledge cutoff.
Key Novelty
FreshQA Benchmark and FreshPrompt Method
- Creates a dynamic QA benchmark (FreshQA) categorized by how frequently answers change (never, slow, fast) and including false premises, requiring regular updates
- Develops FreshPrompt, a few-shot prompting strategy that integrates diverse search engine evidence (organic results, answer boxes, related questions) into the prompt to ground LLM reasoning
Architecture
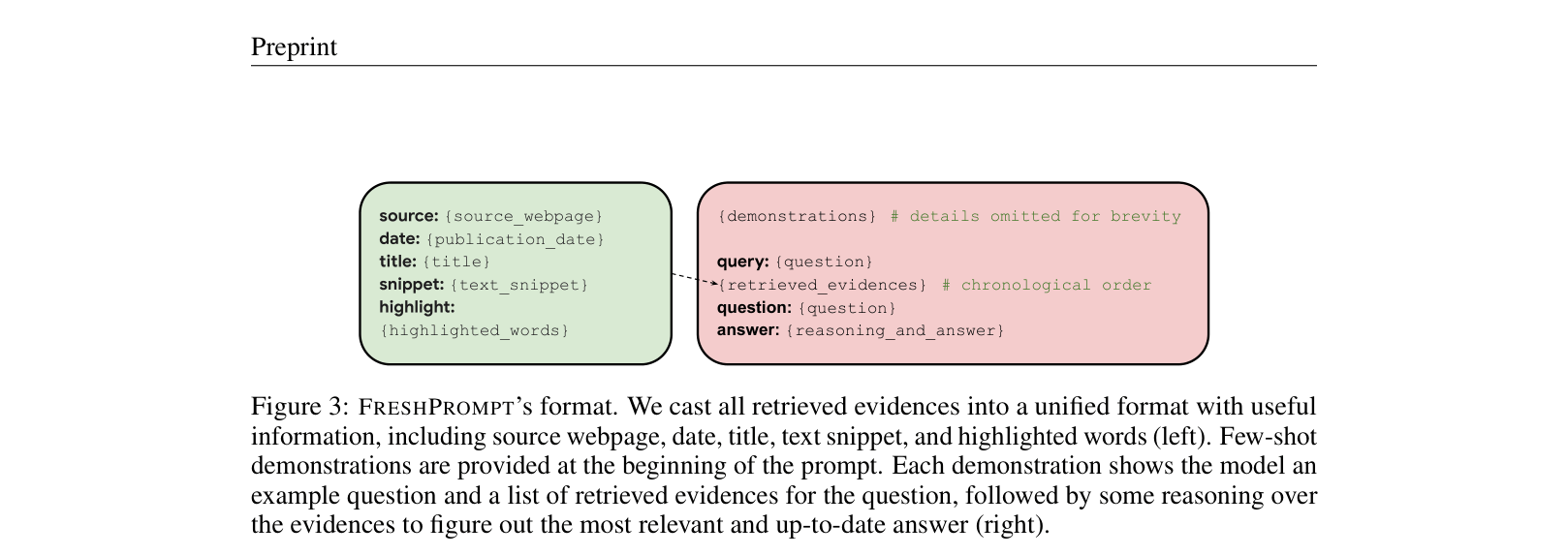
The format of FreshPrompt, illustrating how search results are structured and fed into the LLM.
Evaluation Highlights
- GPT-4 with FreshPrompt achieves +49.0% absolute accuracy improvement over vanilla GPT-4 under STRICT evaluation on FreshQA
- FreshPrompt outperforms competing search-augmented methods like Self-Ask (+33.7% accuracy) and Perplexity.ai (+38.7% accuracy) under STRICT evaluation on GPT-4
- Increasing retrieved evidences from 1 to 15 improves FreshPrompt accuracy by +16.2% under STRICT evaluation
Breakthrough Assessment
8/10
Significant contribution in benchmarking dynamic knowledge (a major LLM weakness) and providing a strong baseline method that outperforms commercial systems like Perplexity.ai at the time of publication.