📝 Paper Summary
Hallucination suppression
Self-Correction/Reasoning
Chain-of-Verification (CoVe) reduces hallucinations by prompting LLMs to plan verification questions, answer them independently to avoid bias, and produce a revised response based on those checks.
Core Problem
Large Language Models (LLMs) often generate plausible but incorrect factual information (hallucinations), particularly for rare facts or in longform generation where exposure bias exacerbates errors.
Why it matters:
- Scaling model size or data does not fully resolve hallucination, especially for tail distribution facts.
- Models often repeat their own hallucinations when verifying them if the verification step attends to the original incorrect response.
Concrete Example:
When asked to list politicians born in NY, ChatGPT generates a list including Hillary Clinton (incorrect). CoVe generates the question 'Where was Hillary Clinton born?', answers 'Chicago' independently, and removes her from the final list.
Key Novelty
Chain-of-Verification (CoVe)
- Splits verification into four steps: (1) Draft response, (2) Plan verification questions, (3) Execute verifications independently, (4) Generate final verified response.
- Crucially uses a 'factored' approach where verification questions are answered without attending to the original draft to prevent repeating hallucinations.
Architecture
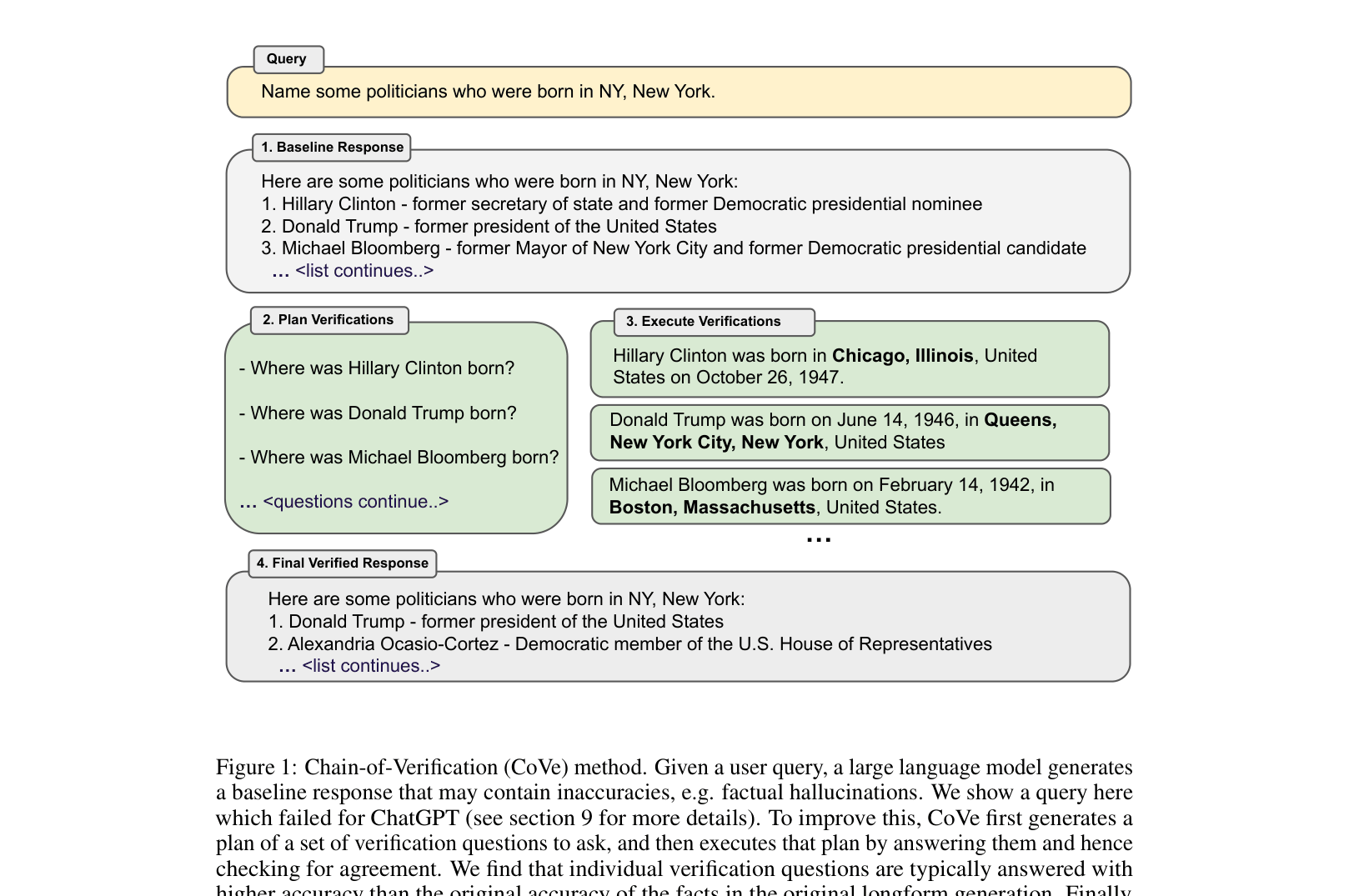
Overview of the Chain-of-Verification (CoVe) method illustrating the four-step process on a specific example (politicians born in NY).
Evaluation Highlights
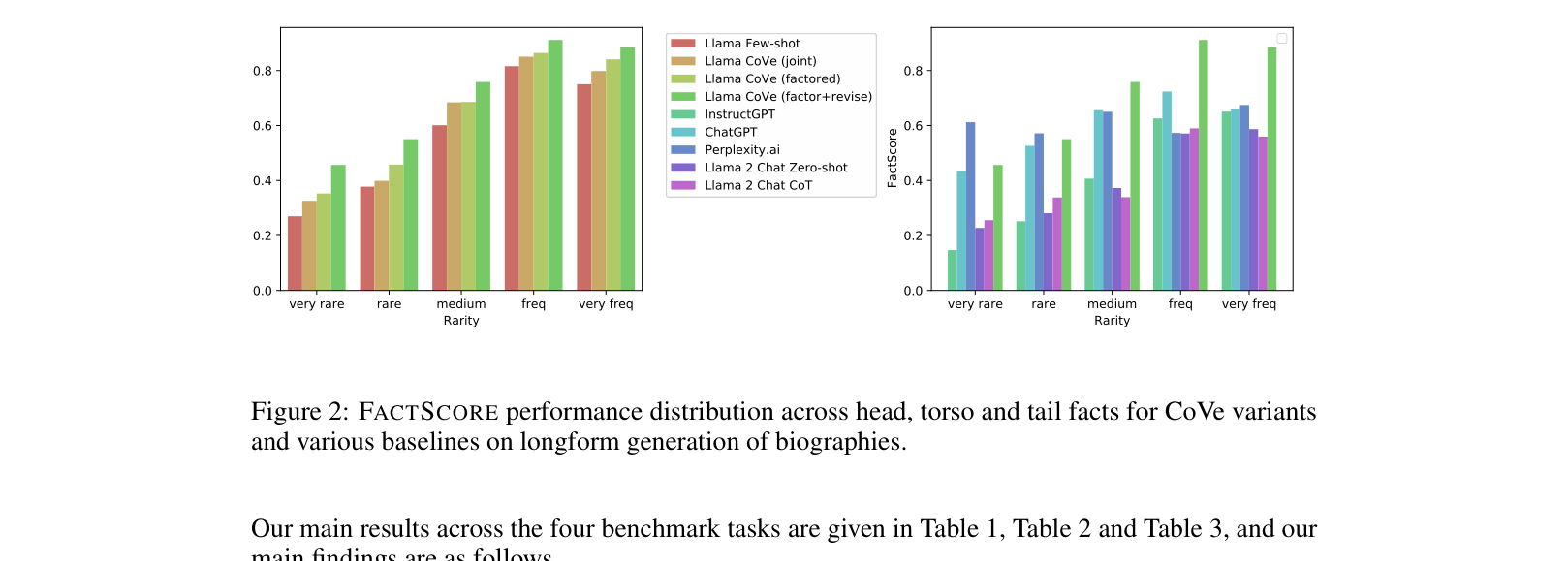
- Increases FACTSCORE on longform biography generation to 71.4 (CoVe factor+revise) from 55.9 (Few-shot baseline), outperforming ChatGPT (58.7).
- Doubles precision on Wikidata list-based questions from 0.17 (Llama 65B Few-shot) to 0.36 (CoVe two-step).
- Improves F1 on closed-book MultiSpanQA by 23% over the few-shot baseline (0.39 -> 0.48) by increasing both precision and recall.
Breakthrough Assessment
8/10
Significant performance gains across multiple tasks by simply changing the reasoning structure, outperforming larger commercial models (ChatGPT) without external retrieval tools.