📝 Paper Summary
Hallucination suppression
Calibration of language models
GPT-3 can be fine-tuned to express calibrated uncertainty about its own answers using natural language (verbalized probability), generalizing reasonably well to new tasks without relying solely on output logits.
Core Problem
Language models often hallucinate false statements with high confidence, and their internal token-level probabilities (logits) represent uncertainty over text strings rather than epistemic uncertainty about the truth of claims.
Why it matters:
- Users need to know when to trust model outputs, especially for economic forecasts or scientific problems where ground truth is unknown
- Standard logit-based calibration fails when a claim can be paraphrased many ways (uncertainty over tokens vs. uncertainty over claims)
- Pre-trained models like GPT-3 are often uncalibrated and overconfident on tasks outside their training distribution
Concrete Example:
If a model is asked 'What is 952 - 55?', it might answer '897' (correct) but assign low token probability because there are many ways to write the answer, or answer '900' (incorrect) with high confidence. A calibrated model should output '897' and explicitly state 'Confidence: 61%' or 'Medium', matching the actual probability of correctness.
Key Novelty
Verbalized Probability via Supervised Fine-Tuning
- Train the model to output its confidence in natural language (e.g., '90%' or 'High confidence') alongside its answer, treating confidence as a text generation task
- Use the model's own empirical accuracy on specific question types as the ground-truth label for training, allowing it to learn its own epistemic uncertainty
Architecture

The inference workflow for verbalized probability calibration
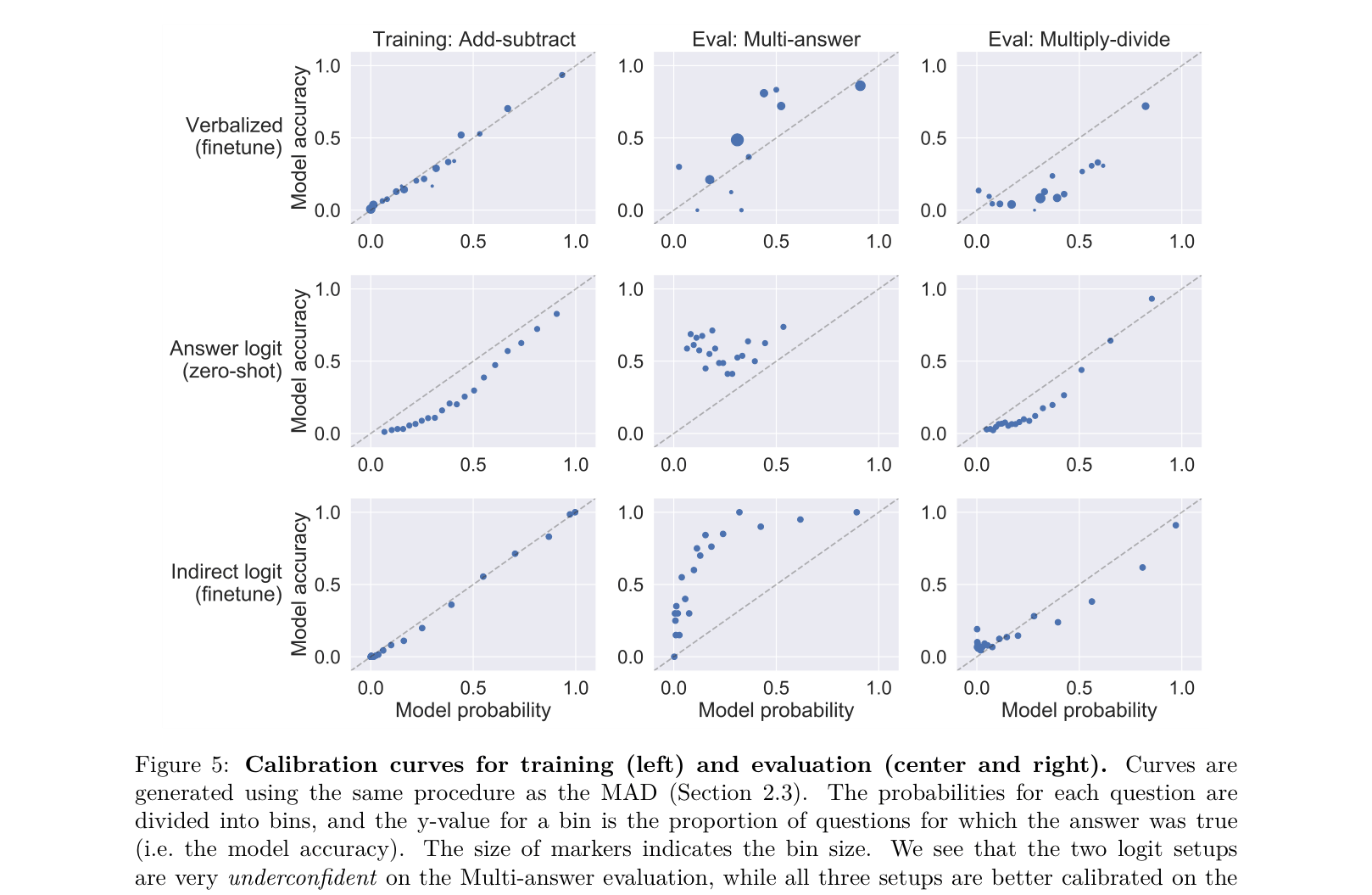
Evaluation Highlights
- Verbalized probability achieves 16.4% MAD (Mean Absolute Deviation) on the out-of-distribution Multi-answer evaluation set, significantly better than the answer logit baseline (33.7% MAD)
- Verbalized probability reaches 10.6% MAD on the Multiply-divide evaluation set, generalizing from the simpler Add-subtract training set
- Stochastic 50-shot learning achieves calibration performance close to the fully fine-tuned model (roughly matching the calibration curve visually in Figure 6)
Breakthrough Assessment
8/10
First demonstration of a model expressing calibrated epistemic uncertainty in natural language that generalizes to new distributions. Shifts calibration paradigm from logits to language.