📊 Experiments & Results
Evaluation Setup
Uncertainty correctness prediction: Can the uncertainty score distinguish between correct and incorrect answers?
Benchmarks:
- TriviaQA (Closed-book Question Answering)
- CoQA (Open-book Conversational Question Answering)
Metrics:
- AUROC (Area Under Receiver Operating Characteristic)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| TriviaQA | AUROC | 0.79 | 0.83 | +0.04 |
| CoQA | AUROC | 0.73 | 0.77 | +0.04 |
| TriviaQA | AUROC | 0.68 | 0.83 | +0.15 |
| TriviaQA | AUROC | 0.79 | 0.83 | +0.04 |
Experiment Figures
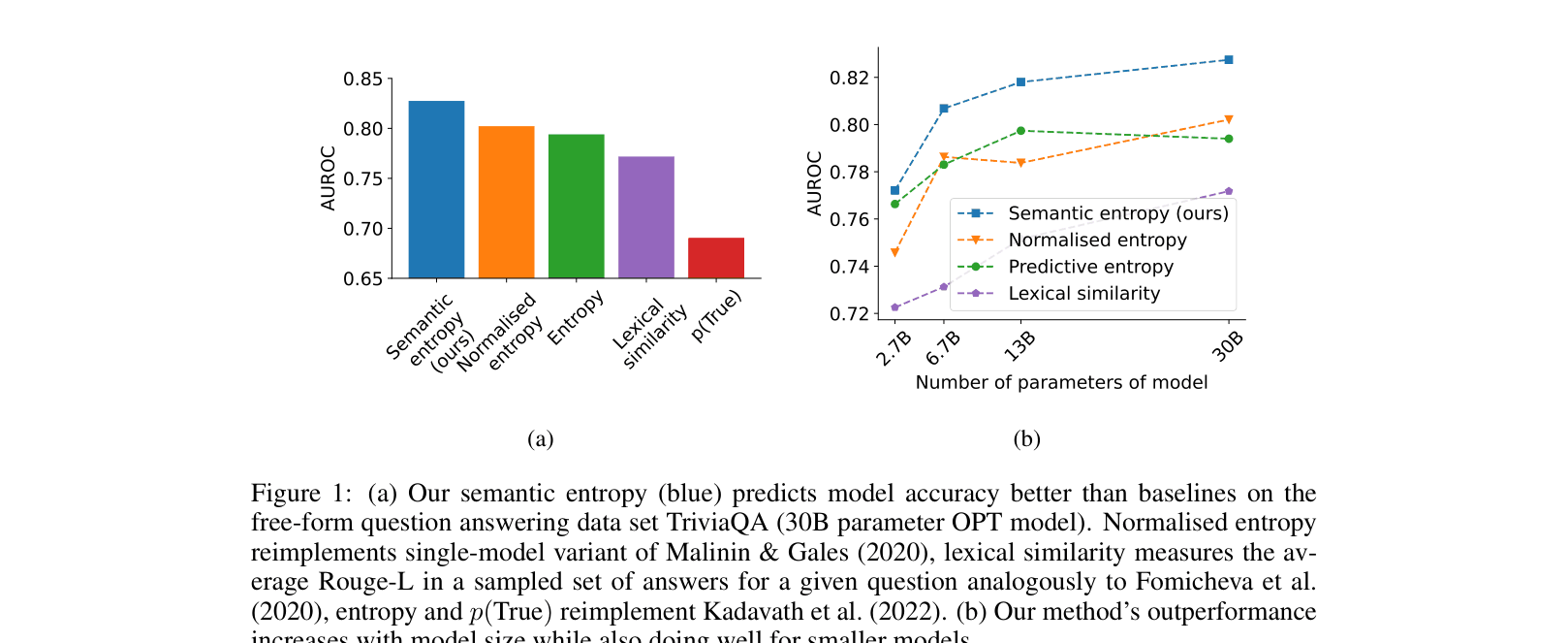
AUROC performance on TriviaQA across different model sizes (2.7B to 30B)
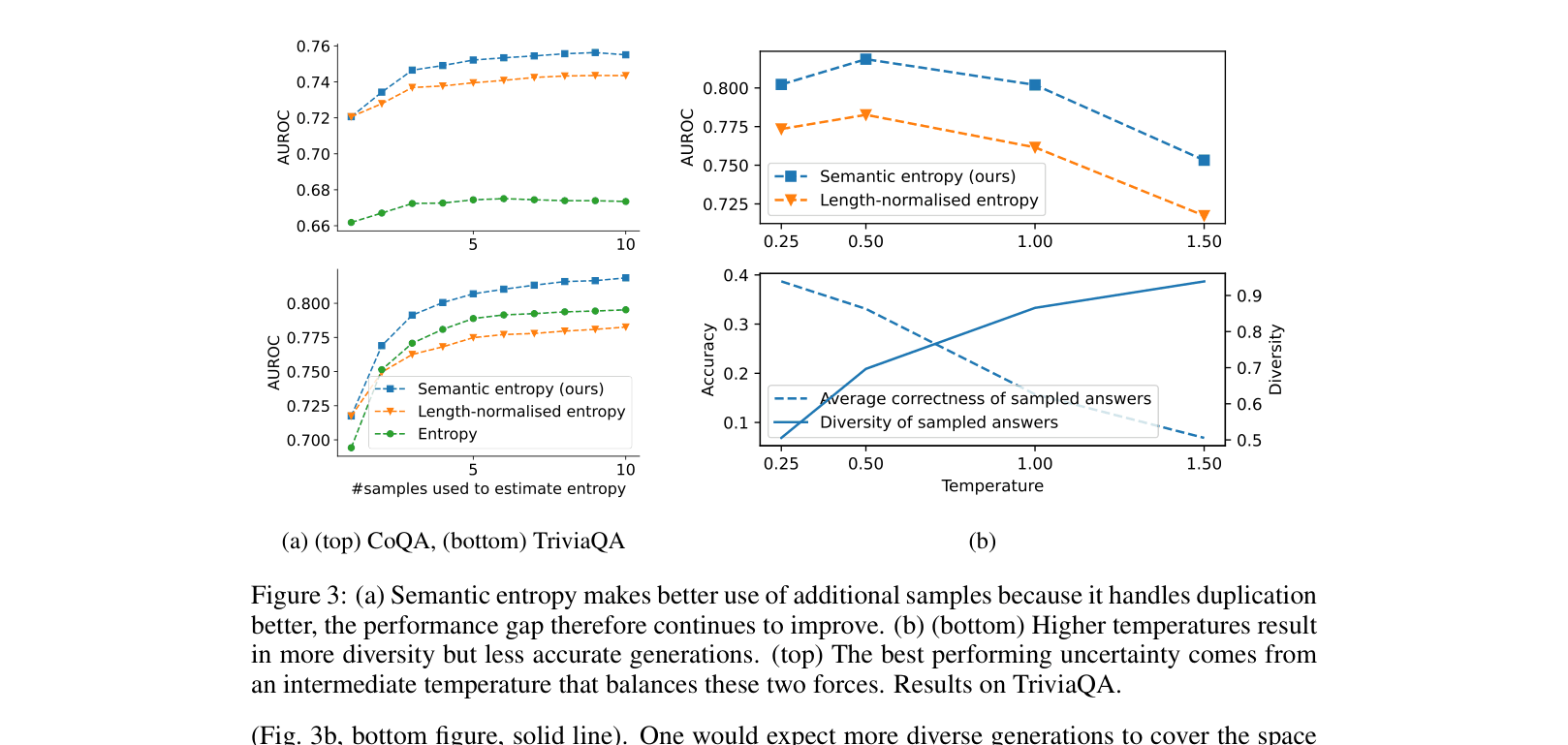
Impact of sample count (left) and temperature (right) on AUROC
Main Takeaways
- Semantic entropy consistently outperforms standard predictive entropy, p(True), and lexical similarity across datasets and model sizes
- The method scales well: performance improves as the underlying language model size increases (from 2.7B to 30B)
- Sampling temperature is critical; an intermediate temperature (e.g., 0.5) balances diversity and accuracy better than 1.0
- Incorrect answers tend to have a higher number of semantically distinct clusters (3.89 vs 1.89 on TriviaQA), validating the core hypothesis