📝 Paper Summary
Hallucination Detection
Uncertainty Estimation
SAC3 improves hallucination detection in black-box LLMs by extending self-consistency checks with semantically equivalent question perturbations and cross-model verification to identify consistently wrong answers.
Core Problem
Existing self-consistency methods fail when LLMs are consistently wrong (question-level hallucination) or when a specific model architecture is prone to specific errors (model-level hallucination).
Why it matters:
- Self-consistency alone is insufficient because high confidence/consistency does not guarantee factuality (e.g., an LLM might consistently answer that pi is smaller than 3.2)
- Token-level log probabilities required for some uncertainty metrics are unavailable in commercial black-box APIs like ChatGPT
- Reliable detection is critical for deploying LLMs in high-stakes domains where factual accuracy is paramount
Concrete Example:
When asked 'Is pi smaller than 3.2?', ChatGPT consistently answers 'No' (incorrectly). A standard self-consistency check sees consistent answers and falsely labels it factual. SAC3 perturbs the question ('Is 3.2 greater than pi?') and checks across models to expose the error.
Key Novelty
Semantic-Aware Cross-check Consistency (SAC3)
- Perturbs the input question into semantically equivalent variants to check if the model's answers remain consistent across phrasing changes (tackling question-level fixation)
- Introduces a second 'verifier' LLM to cross-check answers, identifying cases where the target model might be confidently wrong due to its specific training biases
Architecture
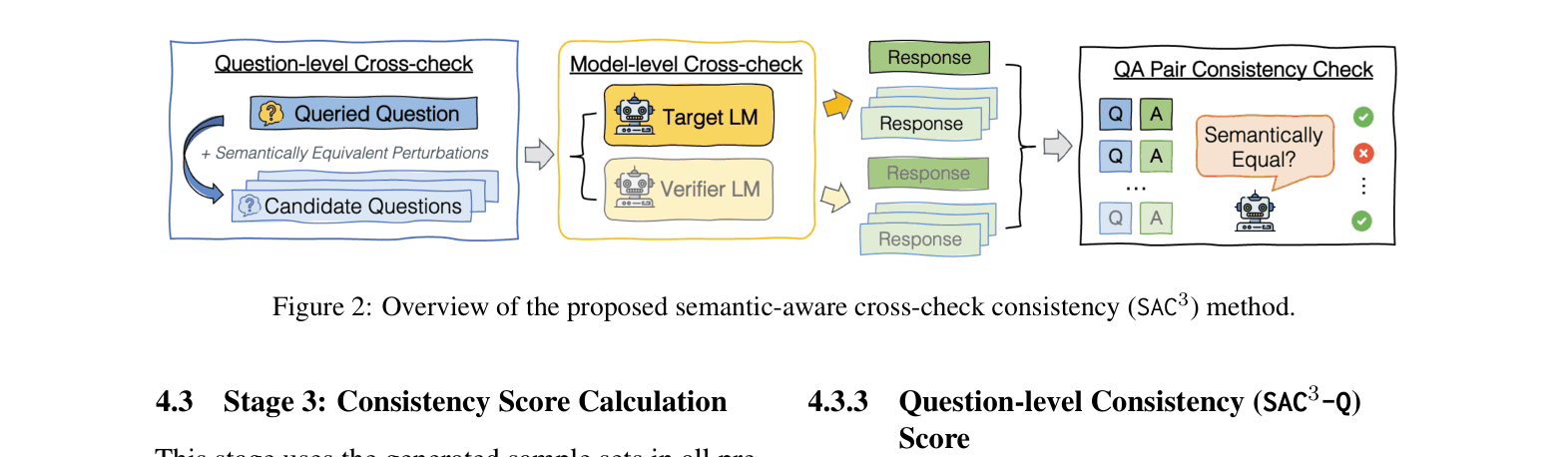
The 3-stage pipeline of SAC3: Question Perturbation, Cross-Checking (Model & Question), and Score Calculation.
Evaluation Highlights
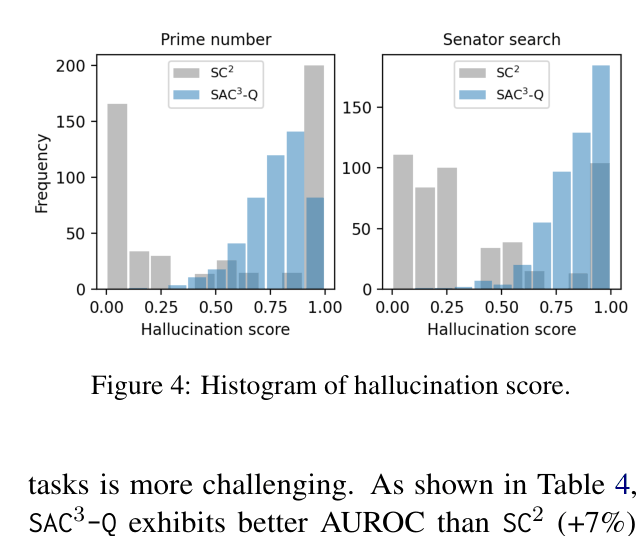
- Achieves 99.4% AUROC on the Prime Number classification task, outperforming the self-consistency baseline (65.9%) by +33.5 points
- Improves hallucination detection on open-domain generation (HotpotQA-halu) to 88.0% AUROC compared to 74.2% for the baseline
- Demonstrates robustness across model scales, with SAC3-Q outperforming self-consistency on GPT-3.5, GPT-4, and PaLM 2
Breakthrough Assessment
8/10
Significantly exposes the failure modes of standard self-consistency (consistent hallucinations) and provides a practical, black-box compatible solution with large empirical gains.