📝 Paper Summary
Uncertainty Quantification (UQ)
Hallucination Detection
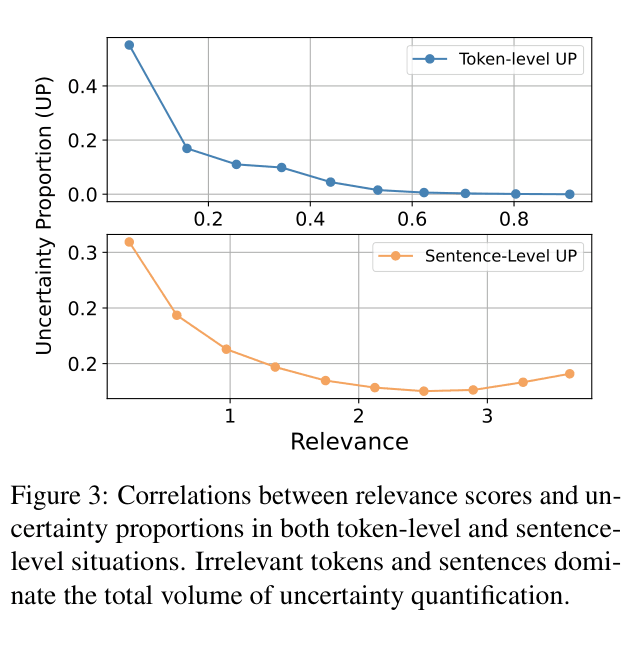
SAR improves uncertainty estimation in LLMs by down-weighting linguistic redundancy (irrelevant tokens like 'the', 'of') and up-weighting semantically relevant components at both token and sentence levels.
Core Problem
Standard uncertainty metrics (like Predictive Entropy) treat all tokens equally, even though 'irrelevant' tokens (e.g., articles, prepositions) often dominate the uncertainty calculation despite having little semantic meaning.
Why it matters:
- High uncertainty on irrelevant tokens (e.g., 'of' in 'density of an object') can falsely trigger refusal or low confidence scores even when the model knows the core answer
- Existing methods underestimate 'generative inequality'—the fact that a few keywords convey the essence of a long sentence while linguistic redundancy dilutes uncertainty measurements
- Accurate UQ is critical for high-stakes Human-AI interaction (e.g., medical Q&A) where users must know when to trust free-form model outputs
Concrete Example:
For the question 'What is the ratio of mass to volume?', the model generates 'density of an object'. The token 'of' might have high entropy (uncertainty), misleading the total score to suggest the model is uncertain, even though the core token 'density' is correct and confident.
Key Novelty
Shifting Attention to Relevance (SAR)
- Token-level shifting: Calculate how much the meaning changes if a token is removed; use this 'relevance score' to re-weight the entropy contribution of each token
- Sentence-level shifting: Reduce the uncertainty estimate for sentences that are semantically similar to other generated samples, assuming consistency implies correctness
- Joint optimization: Combine both shifting strategies to focus uncertainty quantification on the semantically loaded parts of the generation
Architecture
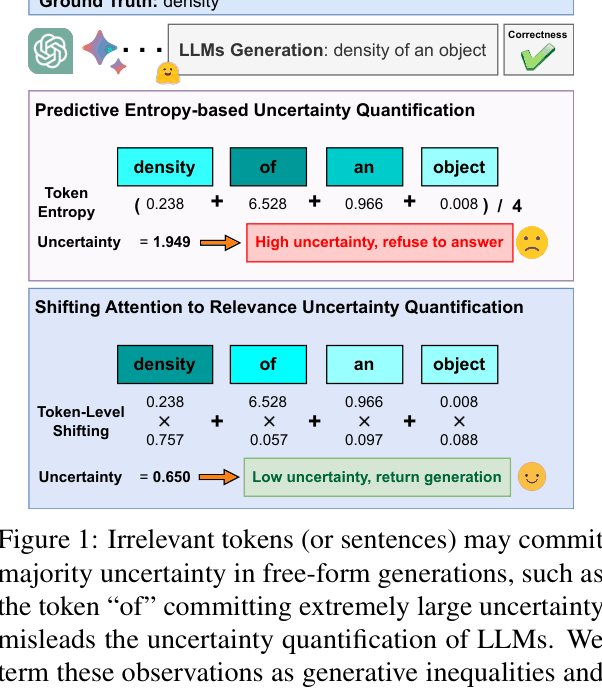
Comparison between standard Predictive Entropy and SAR on a specific example ('density of an object'). Shows how standard UQ adds high uncertainty from the token 'of', while SAR suppresses it.
Evaluation Highlights
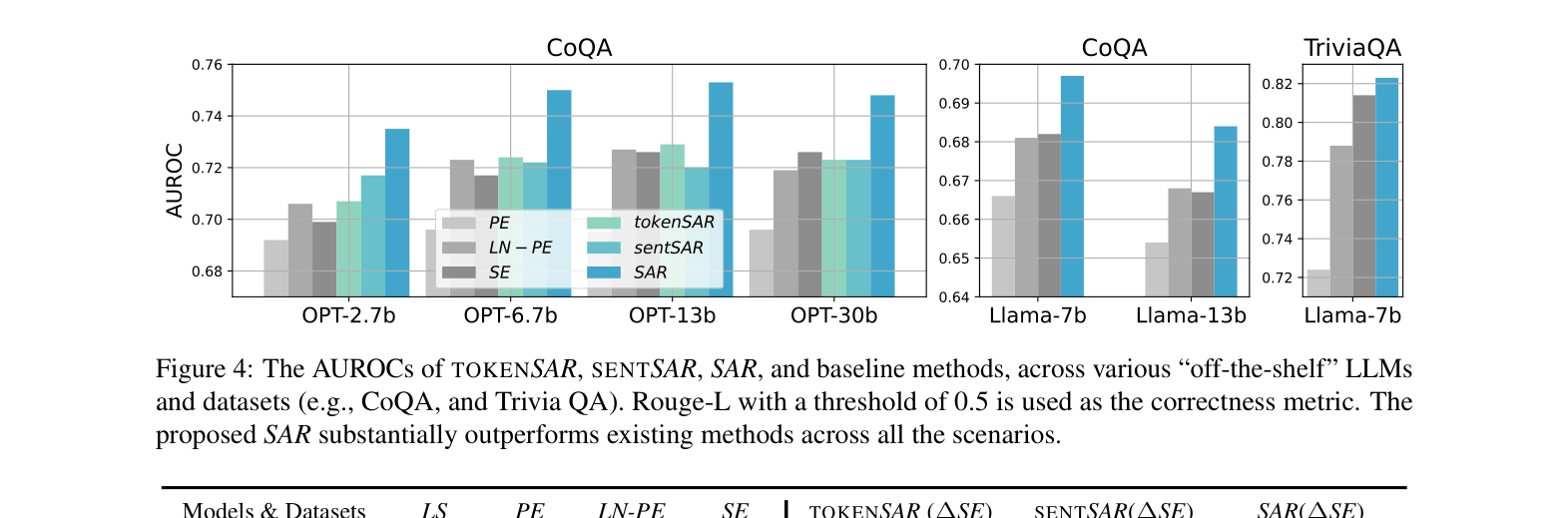
- +11.9% AUROC improvement on TriviaQA using Vicuna-13b compared to Semantic Entropy (SE) baseline
- +7.1% average AUROC improvement over Semantic Entropy across multiple datasets and models (Vicuna, WizardLM, LLaMA-2-chat)
- Achieves superior performance with only 5 generations compared to baselines requiring more samples, demonstrating higher generation efficiency
Breakthrough Assessment
7/10
Simple yet effective heuristic that addresses a fundamental flaw in how token-level entropy is aggregated. Significant empirical gains, though relies on auxiliary models for similarity.