📝 Paper Summary
Hallucination suppression
Knowledge internalization
CoKE teaches LLMs to identify their own knowledge boundaries using internal confidence signals and fine-tunes them to honestly decline unknown questions while answering known ones.
Core Problem
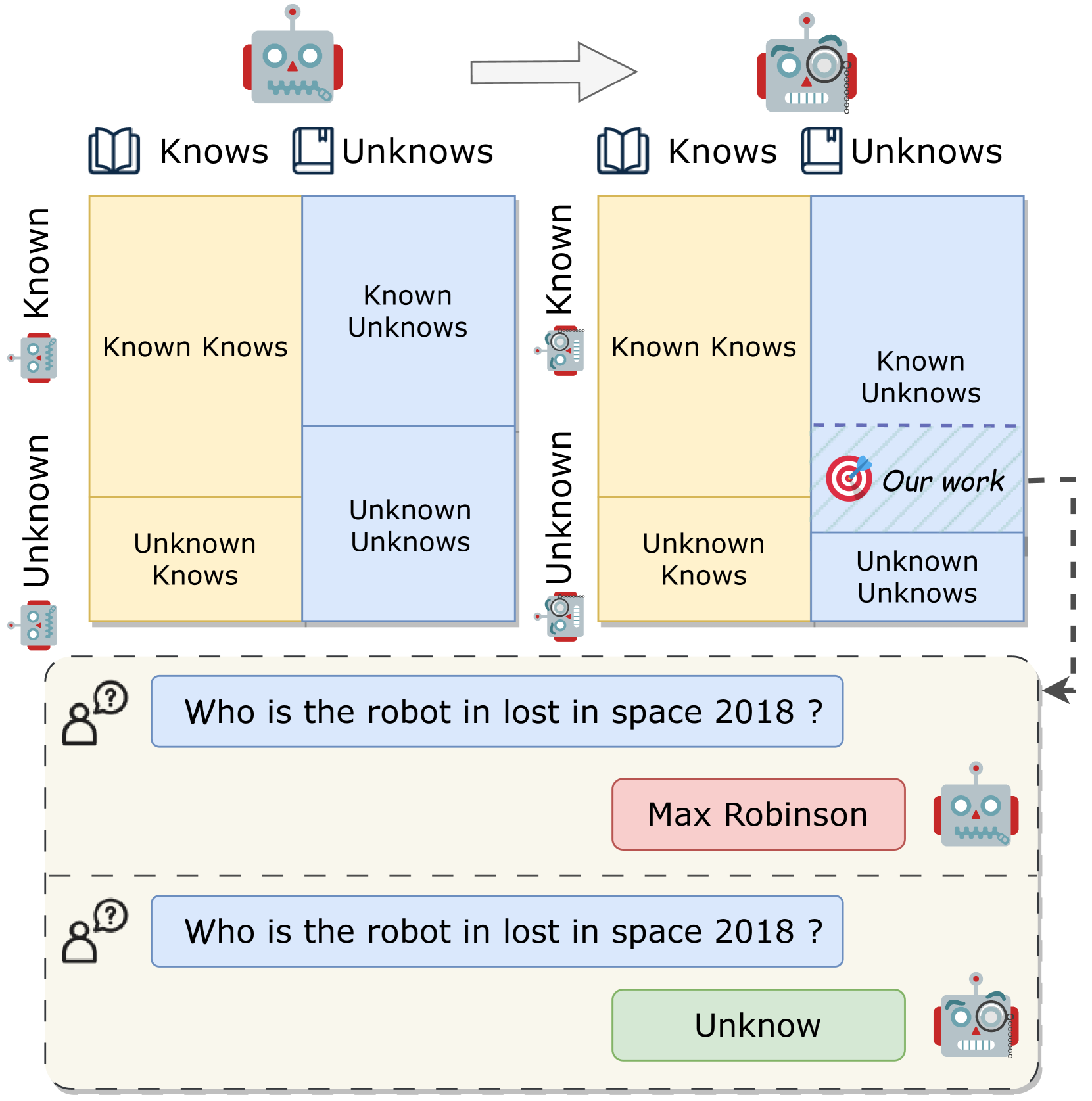
LLMs struggle to admit ignorance because their training encourages generating text even when they lack relevant parametric knowledge, leading to hallucinations in 'Unknown Unknowns' scenarios.
Why it matters:
- Hallucinations severely undermine user trust, preventing the adoption of LLMs in high-stakes domains like medicine and law
- Current methods often rely on costly external annotations or complex uncertainty thresholds that are hard for users to manage
- Models often lack consistency, expressing ignorance in one phrasing but hallucinating an answer when prompted differently about the same fact
Concrete Example:
When asked 'panda is a national animal of which country', an LLM might hallucinate an answer if it doesn't know. CoKE enables it to detect low internal confidence (e.g., Min-Prob) and output 'I don't know' instead.
Key Novelty
Confidence-derived Knowledge Boundary Expression (CoKE)
- Probes the model's internal confidence (using minimum token probability) on unlabeled questions to automatically classify them as 'known' or 'unknown' without external supervision
- Fine-tunes the model to align its verbal responses with these internal signals, teaching it to refuse 'unknown' questions and answer 'known' ones
- Uses a multi-prompt consistency loss to ensure the model maintains the same knowledge boundary across different question formulations (prior, direct, and posterior awareness)
Architecture
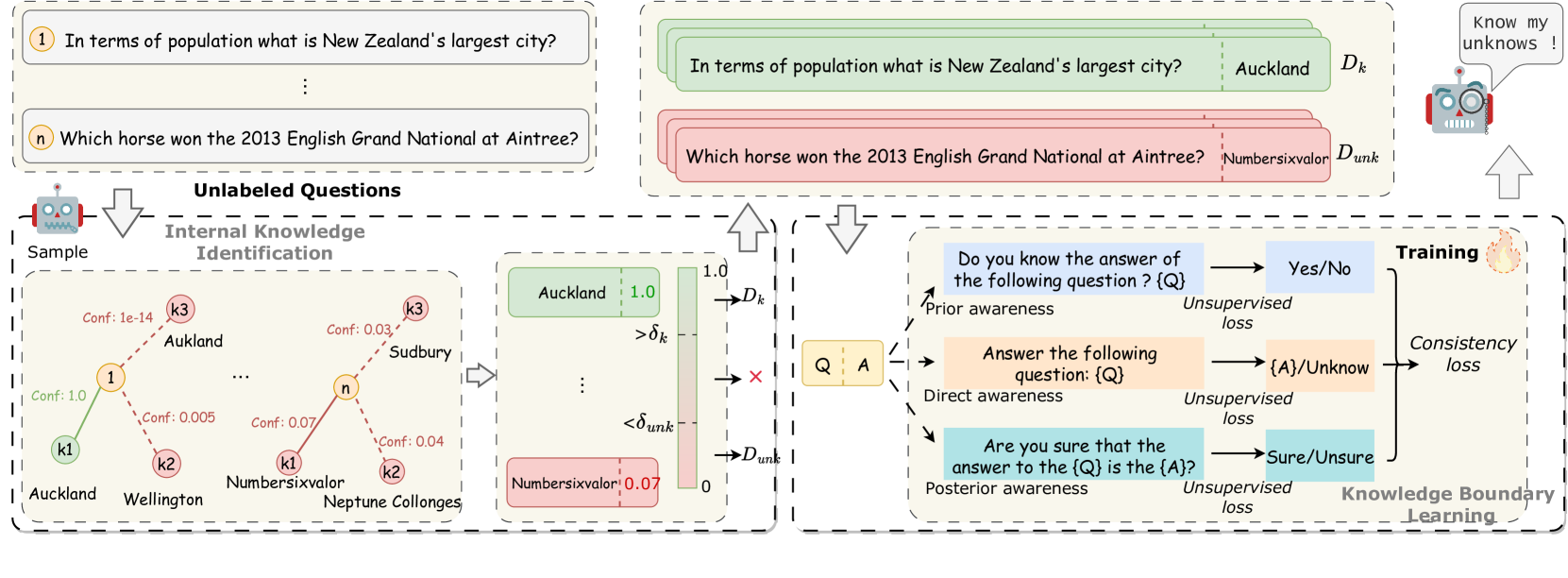
The CoKE method workflow consisting of two stages: Probing and Training.
Evaluation Highlights
- Significant improvement in knowledge boundary awareness (S_aware) on in-domain datasets (e.g., +26.3% on TriviaQA with Llama3-8B-Instruct)
- Strong generalization to out-of-domain datasets (e.g., +13.6% on TruthfulQA with Llama3-8B-Instruct)
- Reduces 'Unknown Unknowns' (hallucinations where the model is unaware of its ignorance) while maintaining high accuracy on known questions
Breakthrough Assessment
7/10
Offers a practical, unsupervised method for hallucination reduction via refusal. The consistency regularization is a clever addition, though reliance on simple probability thresholds is a known technique.