📝 Paper Summary
Hallucination suppression
Confidence-based fine-tuning
RLHF for Factuality
Fine-tuning language models using Direct Preference Optimization on automatically generated preference pairs—based on either external knowledge retrieval or the model's own confidence—significantly reduces factual errors in long-form generation.
Core Problem
Large language models frequently generate convincing but incorrect claims (hallucinations), and standard pre-training objectives do not sufficiently penalize these errors.
Why it matters:
- Manual fact-checking is expensive and slow (e.g., 9 minutes per biography), making human-labeled preference datasets costly to acquire
- Maximum likelihood pre-training encourages 'smearing' probability mass over many possible answers, leading to hallucinations when the model is uncertain or underfits
- Existing RLHF methods focus on helpfulness/harmfulness but don't explicitly target factual correctness, sometimes exacerbating hallucinations
Concrete Example:
When asked 'Where was Yo-Yo Ma born?', a standard model might confidently guess 'Paris' (incorrect) to minimize loss if it lacks the specific fact. A factual model should recognize its internal uncertainty and avoid the claim, but standard training doesn't distinguish between 'confidently wrong' and 'cautiously vague'.
Key Novelty
Automated Factuality Preference Tuning (FactTune)
- Construct preference datasets automatically by sampling two responses from the model and ranking them based on estimated truthfulness (either via external retrieval or internal confidence)
- Use Direct Preference Optimization (DPO) to fine-tune the model on these ranked pairs, teaching it to prefer more factual generation styles without needing human labels
- Introduce a 'reference-free' estimation method that uses the model's own eigencan-confidence (consistency across resampled answers) as a proxy for truthfulness, eliminating the need for Wikipedia/Google
Architecture
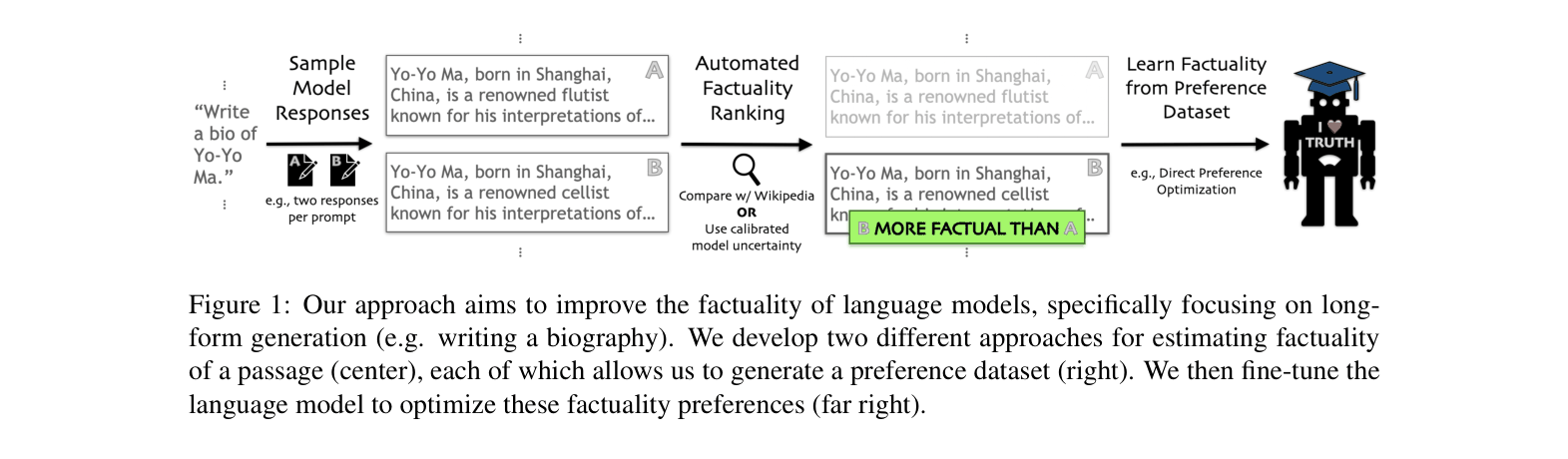
The complete pipeline for Factuality Tuning, from sampling to scoring to DPO updates.
Evaluation Highlights
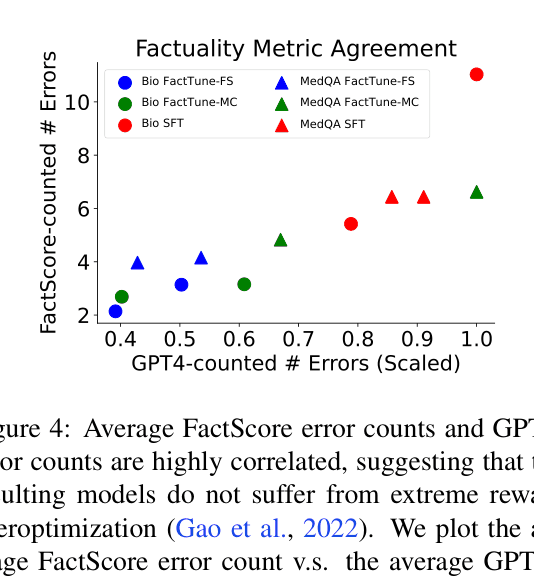
- Reduces factual error rate by 58% on biography generation compared to Llama-2-chat (7B scale)
- Reduces factual error rate by 40% on medical question answering compared to Llama-2-chat
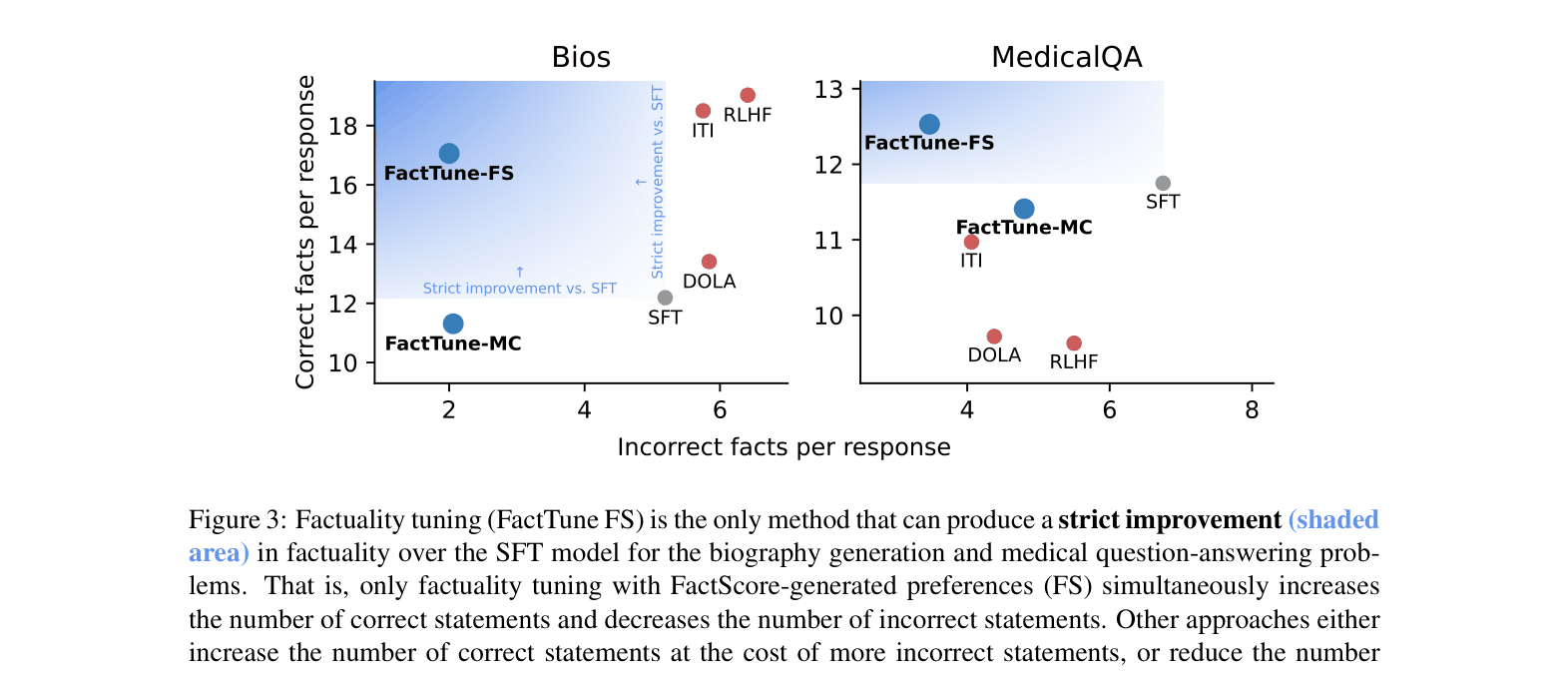
- FactTune-FS (reference-based) achieves 89.5% factual accuracy on biographies, outperforming RLHF (74.8%) and inference-time intervention baselines
Breakthrough Assessment
8/10
Significant because it demonstrates that costly human labeling isn't necessary for alignment on factuality. The reference-free approach is particularly promising for domains where ground truth is scarce.