📝 Paper Summary
Modularized RAG pipeline
Knowledge internalization
RECITE improves Large Language Models' ability to answer factual questions by prompting them to first self-generate (recite) relevant knowledge passages from their own parameters before producing an answer.
Core Problem
LLMs struggle to directly retrieve exact factual knowledge from their parameters for QA tasks because the task format differs from the causal language modeling pre-training objective.
Why it matters:
- Direct generation often leads to hallucinations or incorrect answers even if the model 'knows' the fact in its weights
- Retrieval-augmented models require external corpora and indexes, which may not always be available or up-to-date
- Standard few-shot prompting does not leverage the intermediate 'study' or 'recitation' step humans use to recall complex facts
Concrete Example:
When asked 'What is the tenth decimal of pi?', a model might fail to answer '5' directly. However, it can successfully complete the sequence 'The first 10 digits of pi are 3.1415926535...' and then deduce the answer. RECITE mimics this intermediate step.
Key Novelty
Recitation-Augmented Generation (RECITE)
- Decomposes QA into two steps: (1) Recitation (generating relevant passages from model memory) and (2) Answering (using the recited passage to answer the question)
- Leverages 'fuzzy memorization' where the model generates approximate but factually correct context, rather than retrieving exact strings from a database
- Utilizes passage hints (section titles) to diversify the generated recitations, ensuring coverage of different potential knowledge sources within the model
Architecture
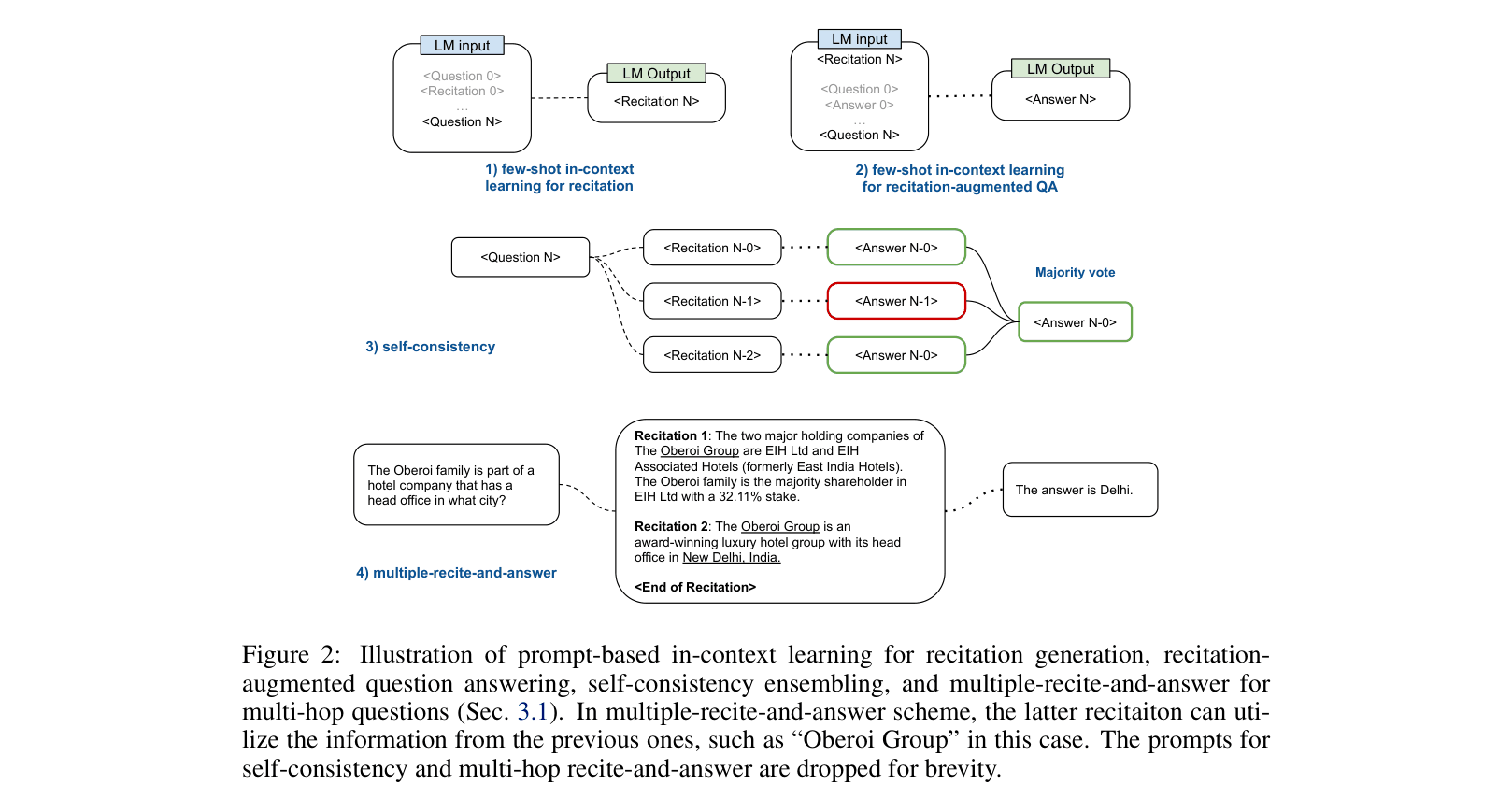
Conceptual flow of the Recitation-Augmented Generation process compared to direct generation
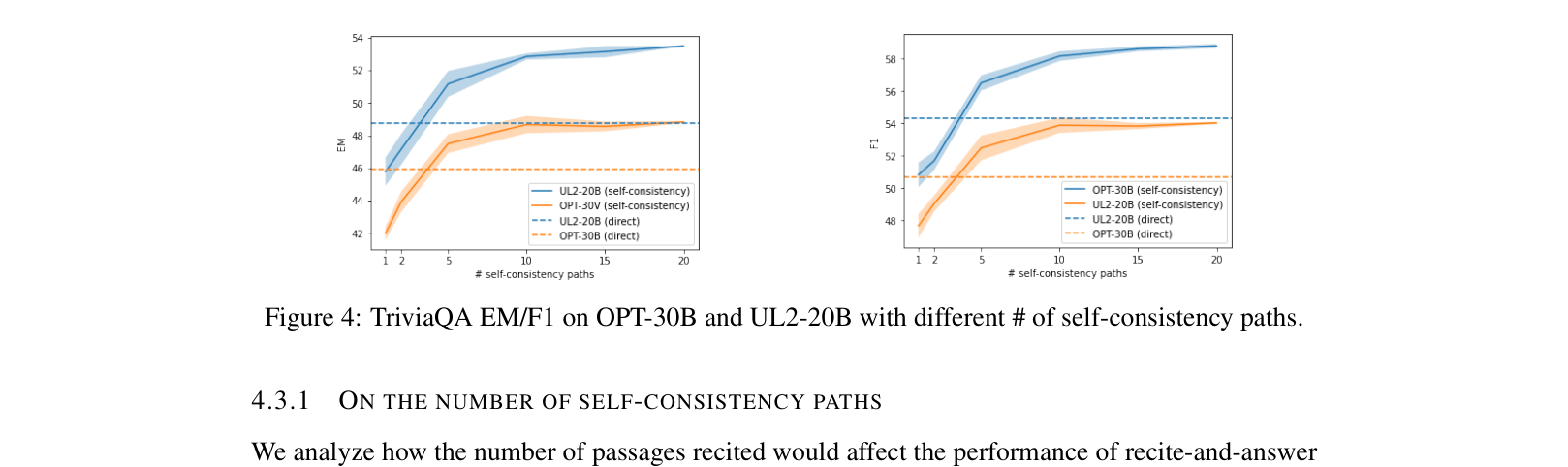
Evaluation Highlights
- Achieves state-of-the-art performance on Natural Questions (64-shot) with 31.34 EM using PaLM-62B, surpassing direct generation (28.98 EM)
- Outperforms standard prompting on TriviaQA (5-shot) with Codex, achieving 83.50 EM compared to 81.84 EM
- RECITE with PaLM-62B (4-shot) scores 26.46 EM on HotpotQA, outperforming standard prompting (20.51 EM) and Chain-of-Thought (23.73 EM)
Breakthrough Assessment
7/10
Strong conceptual contribution showing LLMs can self-retrieve knowledge without external indices. Significant gains on closed-book QA, though reliance on model scale and hallucination risks in recitation remain limitations.