📝 Paper Summary
Hallucination suppression
Mechanistic interpretability
Activation editing
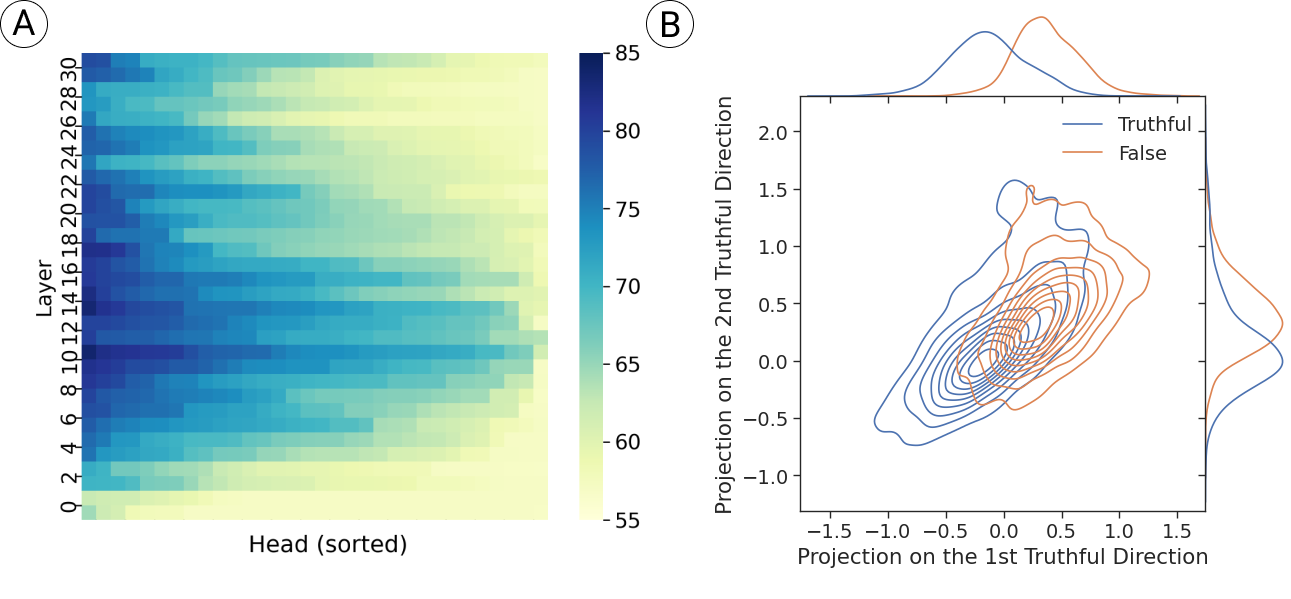
Inference-Time Intervention (ITI) improves LLM truthfulness by identifying attention heads highly correlated with factual accuracy and shifting their activations towards 'truthful' directions during inference.
Core Problem
LLMs often 'know' the correct answer (evidenced by internal activations) but fail to produce it, instead generating hallucinations or mimicking common misconceptions.
Why it matters:
- Correctness is critical in high-stakes contexts, yet models often hallucinate despite having the necessary knowledge internally
- Existing methods like RLHF require massive annotation resources and compute, and may encourage sycophancy rather than truthfulness
- There is a 'generation-discrimination gap' where models can classify truth accurately but fail to generate it
Concrete Example:
When asked a question from TruthfulQA, a standard LLaMA model might mimic a human misconception. However, a probe on its internal activations can classify the true answer with 83.3% accuracy, showing the model 'knows' the truth but doesn't 'say' it.
Key Novelty
Inference-Time Intervention (ITI)
- Identifies a sparse set of attention heads that have high linear probing accuracy for distinguishing truth from falsehood
- During inference, shifts the activations of these specific heads along a learned 'truthful direction' (vector) to steer generation toward accuracy
- Minimally invasive approach that requires no parameter updates (fine-tuning) and uses very few labeled examples (as few as 40)
Architecture
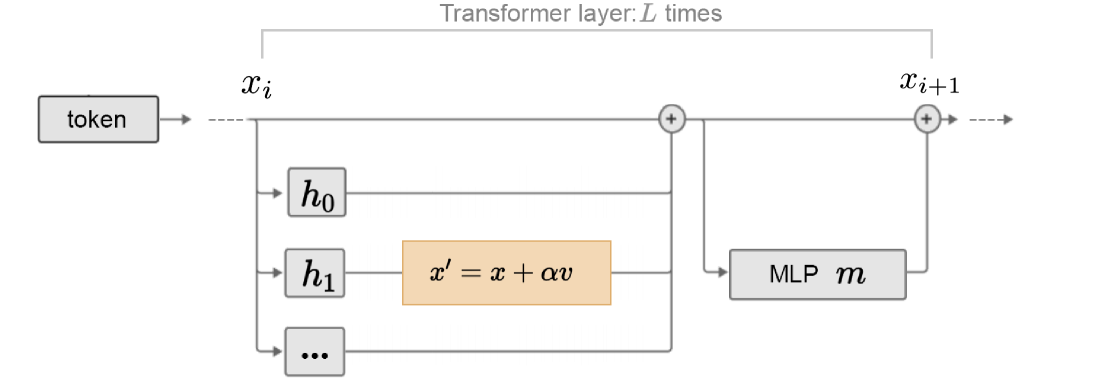
Overview of the ITI method. It shows the process of identifying truthful heads using probes and then shifting activations during inference.
Evaluation Highlights
- Improves Alpaca model's truthfulness on TruthfulQA from 32.5% to 65.1%
- Achieves 40% difference between probe accuracy and generation accuracy on LLaMA-7B, highlighting the gap ITI aims to close
- Locates truthful directions using as few as 40 examples, significantly more efficient than RLHF
Breakthrough Assessment
8/10
Significant improvement in truthfulness with a lightweight, inference-only method. Demonstrates that LLMs have an internal 'world model' of truth distinct from their output behavior.