📝 Paper Summary
Knowledge-grounded dialogue
Dataset auditing
Auditing standard dialogue benchmarks reveals they consist of over 60% hallucinated responses, which models then amplify during training rather than mitigate.
Core Problem
Knowledge-grounded conversational models frequently generate hallucinations, but it is unclear whether this stems primarily from the models themselves or the underlying training data.
Why it matters:
- Existing datasets are crowdsourced with loose incentives, encouraging workers to ignore knowledge snippets and use personal opinions or external knowledge.
- Neural models trained on noisy data may not only replicate but amplify hallucination behavior at inference time.
- Improving models to be faithful is futile if the ground-truth benchmarks themselves are fraught with unverifiable content.
Concrete Example:
In the Wizard of Wikipedia dataset, a 'wizard' ignores the provided text about science fiction's consequences and instead claims the show 'Fringe' is 'incredibly well written'—a subjective opinion not found in the source text. A model trained on this learns to hallucinate subjective content.
Key Novelty
Comprehensive Dataset Audit & Amplification Analysis
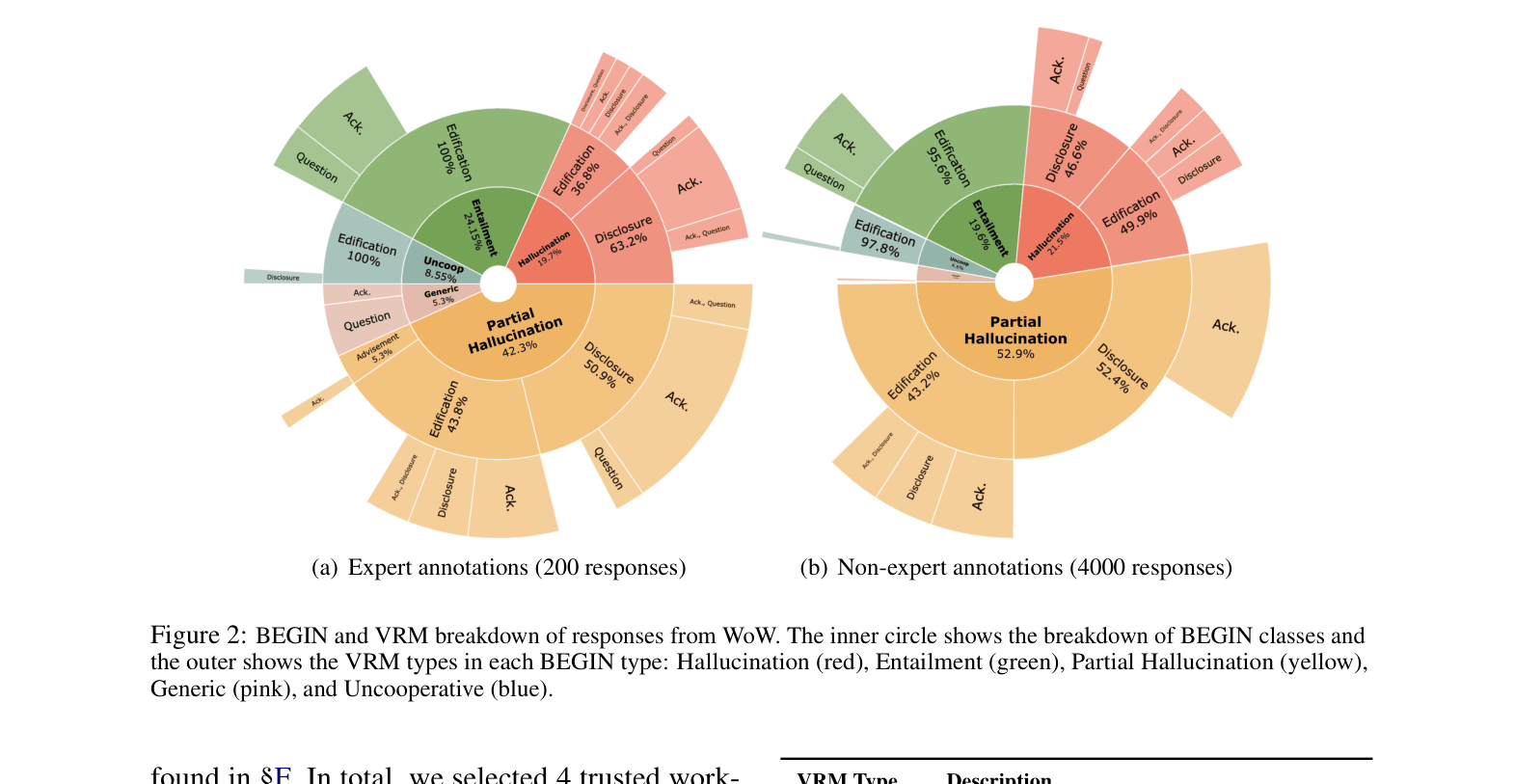
- Conducts a large-scale human annotation of three major benchmarks (Wizard of Wikipedia, CMU-DoG, TopicalChat) using the BEGIN taxonomy to quantify hallucination levels.
- Analyzes the 'Verbal Response Modes' (VRM) to categorize hallucinations linguistically (e.g., Disclosure of opinion vs. Edification of facts).
- Measures 'hallucination amplification' by comparing the hallucination rates of trained SOTA models against the hallucination rates of the gold training data.
Architecture

An example of a hallucinated conversation from the Wizard of Wikipedia dataset.
Evaluation Highlights
- Over 60% of responses in standard benchmarks (WoW, CMU-DoG, TopicalChat) are hallucinated (not supported by the source text).
- State-of-the-art models amplify hallucination: GPT2 trained on WoW increases fully hallucinated responses by 19.2% compared to the gold data.
- Subjective 'Disclosure' (opinions/feelings) is the primary mode of hallucination, accounting for >50% of hallucinations in all three datasets.
Breakthrough Assessment
9/10
A seminal audit paper that fundamentally challenged the reliability of standard benchmarks. It shifted the field's focus from purely architectural fixes to data quality and faithfulness.