📝 Paper Summary
Language Model Pretraining
Lexical Semantics
Word Embedding Specialization
LIBERT augments BERT's pretraining with a third auxiliary task—lexical relation classification—using external constraints (synonyms/hypernyms) to force the model to distinguish true semantic similarity from broad topical relatedness.
Core Problem
Unsupervised pretraining models like BERT rely solely on distributional co-occurrence patterns, which conflates true semantic similarity (e.g., car/automobile) with broad topical relatedness (e.g., car/road).
Why it matters:
- Downstream tasks like lexical simplification and dialog state tracking require precise semantic similarity, which standard distributional models fail to capture accurately
- Existing specialization methods for static embeddings (retrofitting) are not directly applicable to deep transformer-based pretraining objectives
- Models struggle with rare linguistic structures and specific lexical entailments when relying only on raw text corpora
Concrete Example:
In the sentence 'Einstein unlocked the door to the atomic age', a distributional model might suggest 'repaired' (topically related) or 'closed' (antonym) as substitutes for 'unlocked', whereas a specialized model correctly identifies 'opened' based on semantic similarity.
Key Novelty
Lexically Informed BERT (LIBERT)
- Adds a third pretraining task (Lexical Relation Classification) alongside Masked Language Modeling and Next Sentence Prediction
- Feeds pairs of words from external resources (WordNet) as input sequences, classifying whether they hold a specific semantic relation (synonymy/hypernymy)
- Jointly optimizes the encoder to capture clean lexical constraints, steering representations away from mere co-occurrence associations
Architecture
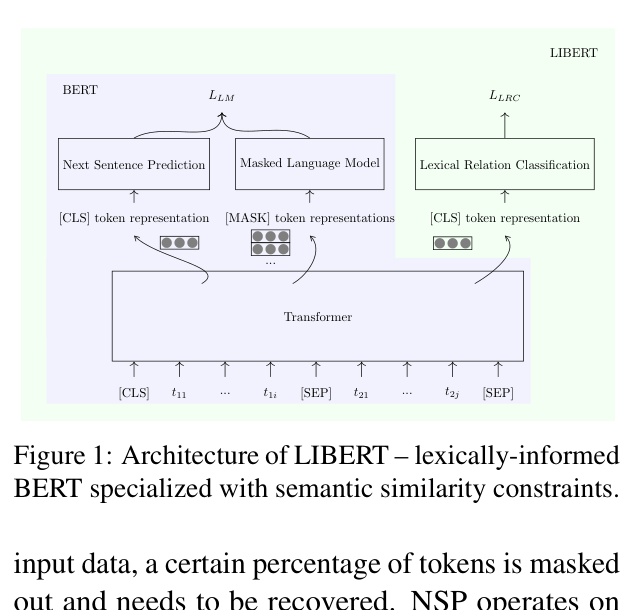
The multi-task training architecture of LIBERT compared to BERT.
Evaluation Highlights
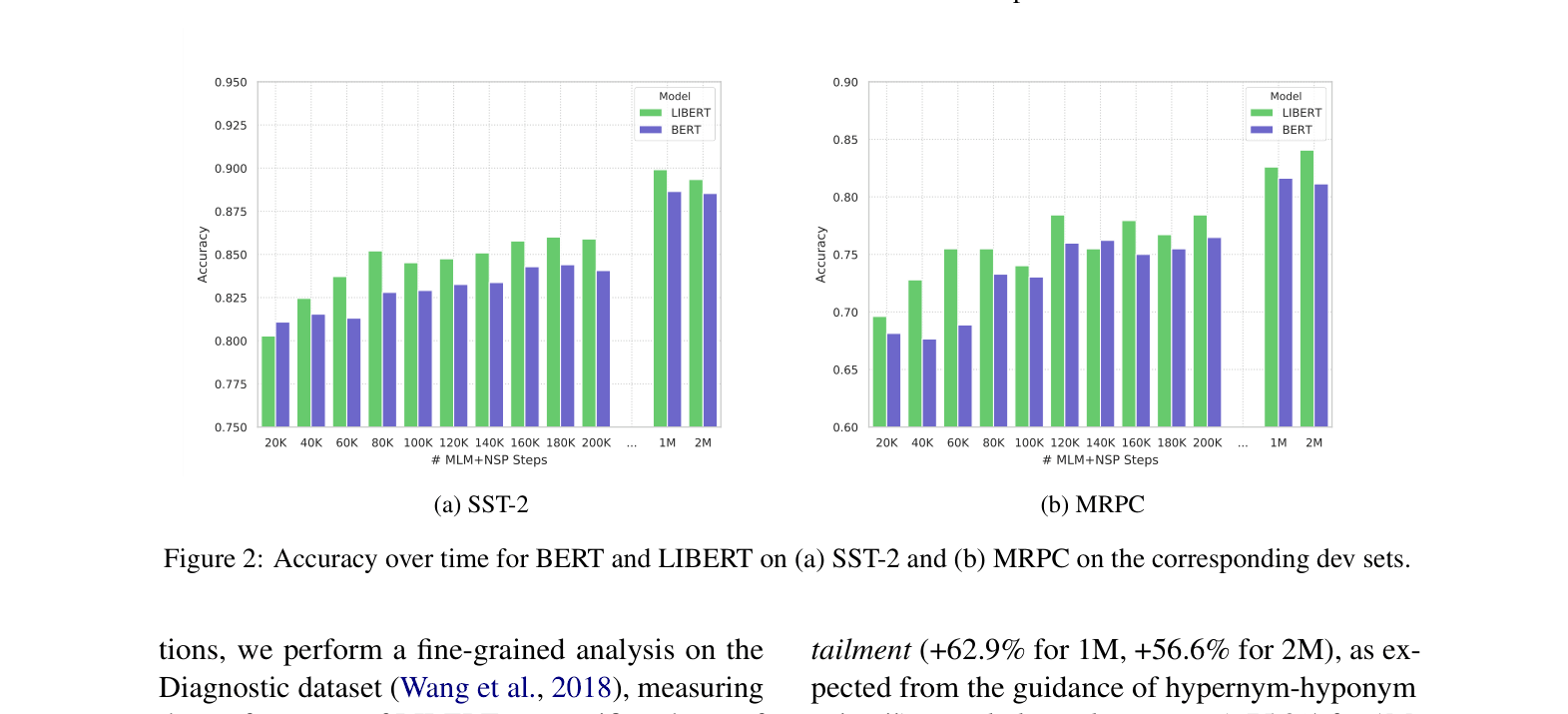
- Outperforms BERT on 9 out of 10 GLUE benchmark tasks, with notable gains on CoLA (+9.9 MCC) and AX (+6.0 MCC)
- Improves Lexical Simplification accuracy by up to 8.2% (LexMTurk dataset) compared to vanilla BERT
- Demonstrates +62.9% improvement on Lexical Entailment and +281.7% on Factivity detection in diagnostic linguistic analysis (1M steps)
Breakthrough Assessment
6/10
Solid methodological extension applying known static embedding specialization techniques to BERT. Results are consistent and positive, though the architectural innovation is a relatively straightforward multi-task addition.