📝 Paper Summary
Language Model Pre-training
Word Sense Disambiguation
SenseBERT augments BERT pre-training by predicting both masked words and their WordNet supersenses, enabling the model to learn lexical semantics directly from unlabeled text.
Core Problem
Standard self-supervised models like BERT operate at the word-form level, which acts as an ambiguous surrogate for underlying meaning (senses), leading to poor performance on tasks requiring explicit semantic categorization.
Why it matters:
- Word forms are ambiguous (e.g., 'bass' can mean fish or guitar), causing standard models to struggle with distinguishing meanings in context
- Existing sense-aware approaches rely on static embeddings or small annotated datasets, failing to leverage the scale of unannotated corpora used by BERT
- Vanilla BERT often fails to grasp lexical semantics, exhibiting high misclassification rates on supersense tasks despite its strong general performance
Concrete Example:
In the sentence 'Dan cooked a bass on the grill', a standard model sees only the word 'bass'. It might predict 'salmon' based on co-occurrence but miss the semantic category. SenseBERT is explicitly trained to recognize 'bass' here as 'noun.food' rather than 'noun.artifact' (musical instrument), improving disambiguation.
Key Novelty
Weakly-Supervised Supersense Pre-training
- Adds a 'supersense prediction' auxiliary task during pre-training: the model must predict the WordNet semantic category (supersense) of a masked word alongside the word itself
- Uses WordNet as a weak supervisor to generate allowed sense labels for unannotated text, enabling semantic learning at scale without human-annotated datasets
- Introduces a soft-labeling scheme where the model predicts any valid supersense for a word, allowing context to naturally reinforce the correct meaning over time
Architecture
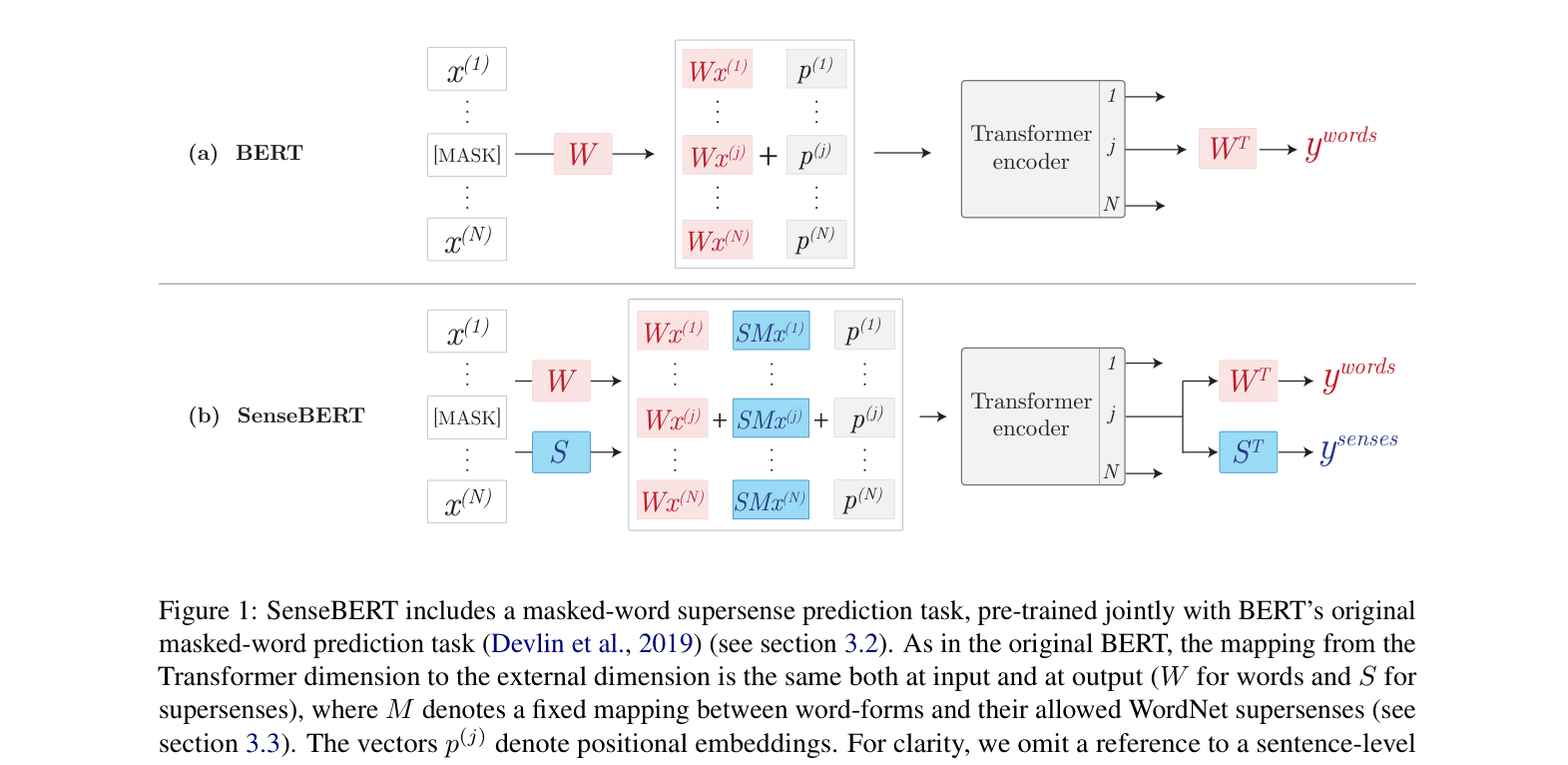
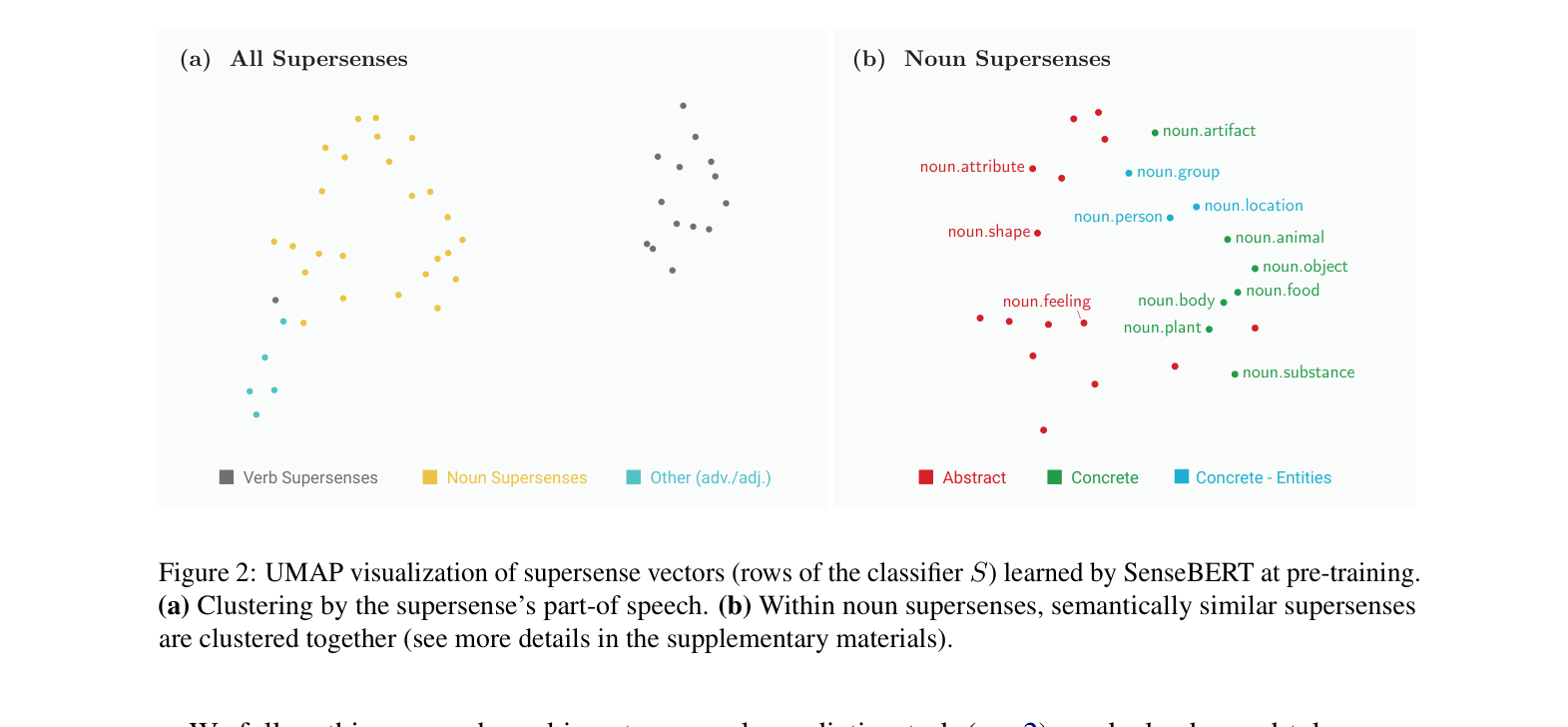
Comparison of BERT and SenseBERT pre-training architectures. SenseBERT adds a parallel output head for supersense prediction and injects supersense embeddings into the input.
Evaluation Highlights
- +10.5 points accuracy improvement on SemEval-SS (Supersense Disambiguation) over BERT Base in the 'Frozen' setting, showing superior intrinsic semantic knowledge
- Achieves state-of-the-art score of 72.14 on the Word in Context (WiC) task with SenseBERT Large, surpassing BERT Large by 2.5 points
- Outperforms BERT Large on SemEval-SS without fine-tuning (Frozen setting), attaining 79.5 vs 67.3 accuracy
Breakthrough Assessment
7/10
Significant improvement on semantic tasks (WiC, WSD) by integrating external knowledge (WordNet) into pre-training. While a strong conceptual advance, it relies on legacy WordNet resources.