📝 Paper Summary
Knowledge Injection
Parameter-Efficient Fine-Tuning
K-ADAPTER injects diverse knowledge into pre-trained models via independent neural adapters that keep the original model fixed, preventing catastrophic forgetting and enabling disentangled representations.
Core Problem
Injecting knowledge into pre-trained models typically involves updating all parameters, which causes 'catastrophic forgetting' where previously learned knowledge is lost when new knowledge is added.
Why it matters:
- Standard pre-trained models (like BERT/RoBERTa) often struggle with factual reasoning and negation despite high linguistic performance
- Multi-task learning approaches produce entangled representations, making it difficult to investigate specific knowledge effects or add new knowledge sources without retraining everything
- Retraining massive models for every new knowledge type is computationally expensive and inefficient
Concrete Example:
Given 'New Fabris closed down June 16', RoBERTa predicts 'no relation'. To correctly predict 'city of birth' for the entity pair, the model needs external factual knowledge that 'New Fabris' is a company, which RoBERTa lacks but K-ADAPTER provides.
Key Novelty
Modular Knowledge Infusion via Parallel Adapters
- Keeps the large pre-trained model frozen and plugs in compact neural 'adapters' (small transformer networks) that run in parallel to the main model
- Each adapter is trained independently on a specific knowledge task (e.g., relation classification for facts, dependency parsing for linguistics), allowing modular additions without retraining previous components
- Outputs from the frozen model and relevant adapters are concatenated to form a final representation that fuses general language understanding with specific injected knowledge
Architecture
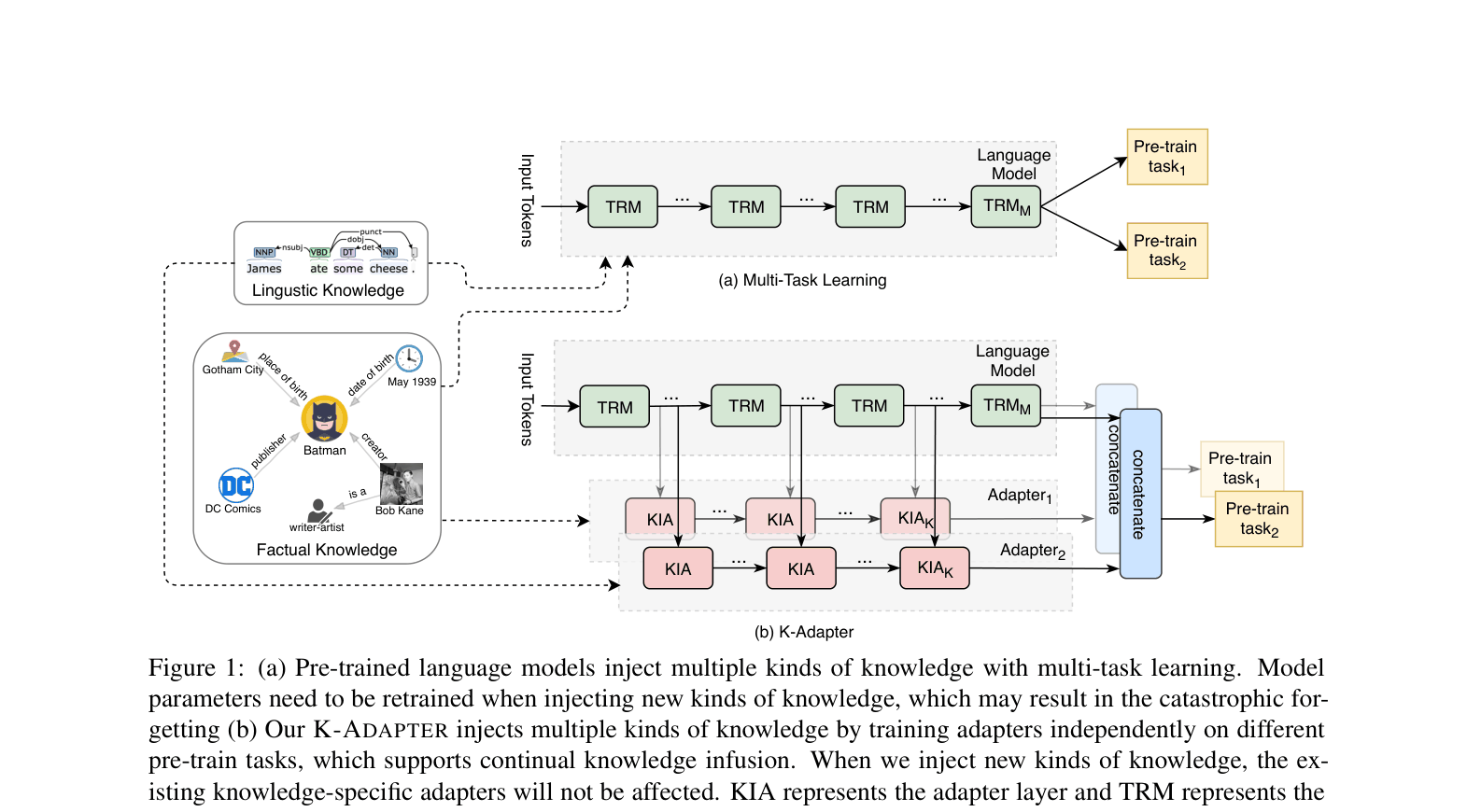
The conceptual framework of K-ADAPTER with parallel adapters and the detailed internal structure of an adapter layer.
Evaluation Highlights
- Outperforms RoBERTa Large on Entity Typing (OpenEntity) by +1.38% F1 using combined factual and linguistic adapters
- Achieves +4.01% F1 improvement over WKLM on SearchQA open-domain question answering
- Surpasses RoBERTa Large on CosmosQA commonsense reasoning by +1.24% accuracy with combined adapters
Breakthrough Assessment
8/10
Pioneered the use of adapters specifically for disentangled knowledge injection rather than just transfer learning. Solves catastrophic forgetting in knowledge infusion effectively.