📝 Paper Summary
Memory-augmented neural networks
Recurrent attention mechanisms
The authors propose a continuous, end-to-end trainable neural network that performs multiple computational hops over an external memory to answer questions or predict language tokens.
Core Problem
Previous memory-augmented models required strong supervision (labels for which specific sentences support an answer) at each layer, making them difficult to apply in realistic settings where only input-output pairs are available.
Why it matters:
- Realistic datasets rarely provide fine-grained supervision about which specific memory facts are relevant to a query
- Standard RNNs/LSTMs struggle to capture very long-term dependencies compared to explicit memory storage
- Models need to perform multiple reasoning steps (hops) to deduce answers from disparate pieces of information
Concrete Example:
In a story where 'Sam walks into the kitchen' then 'Sam drops the apple', a model asked 'Where is the apple?' must deduce the location. Previous Memory Networks needed training labels explicitly marking 'Sam walks into the kitchen' as the supporting fact. This model learns to find it using only the final answer 'kitchen'.
Key Novelty
End-to-End Memory Network (MemN2N)
- Replaces the hard max/ranking operations of previous Memory Networks with a continuous softmax attention mechanism, allowing gradients to backpropagate through memory accesses
- Introduces a 'multi-hop' architecture where the model reads from memory multiple times, updating its internal query state after each hop to perform chain-of-thought reasoning
Architecture
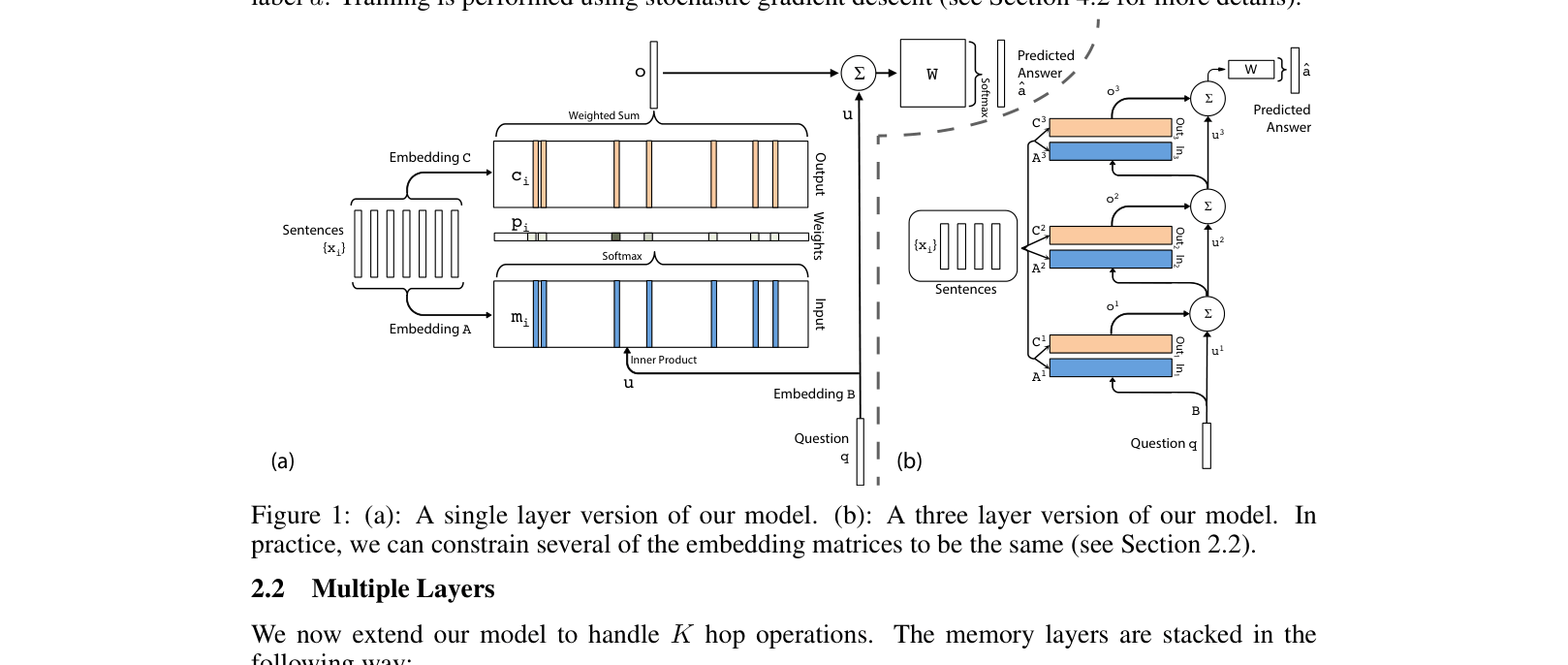
A single layer (a) and a stacked multi-layer (b) version of the End-To-End Memory Network.
Evaluation Highlights
- Achieves 3.2% mean error on bAbI QA tasks (10k training set), comparable to strongly supervised baselines
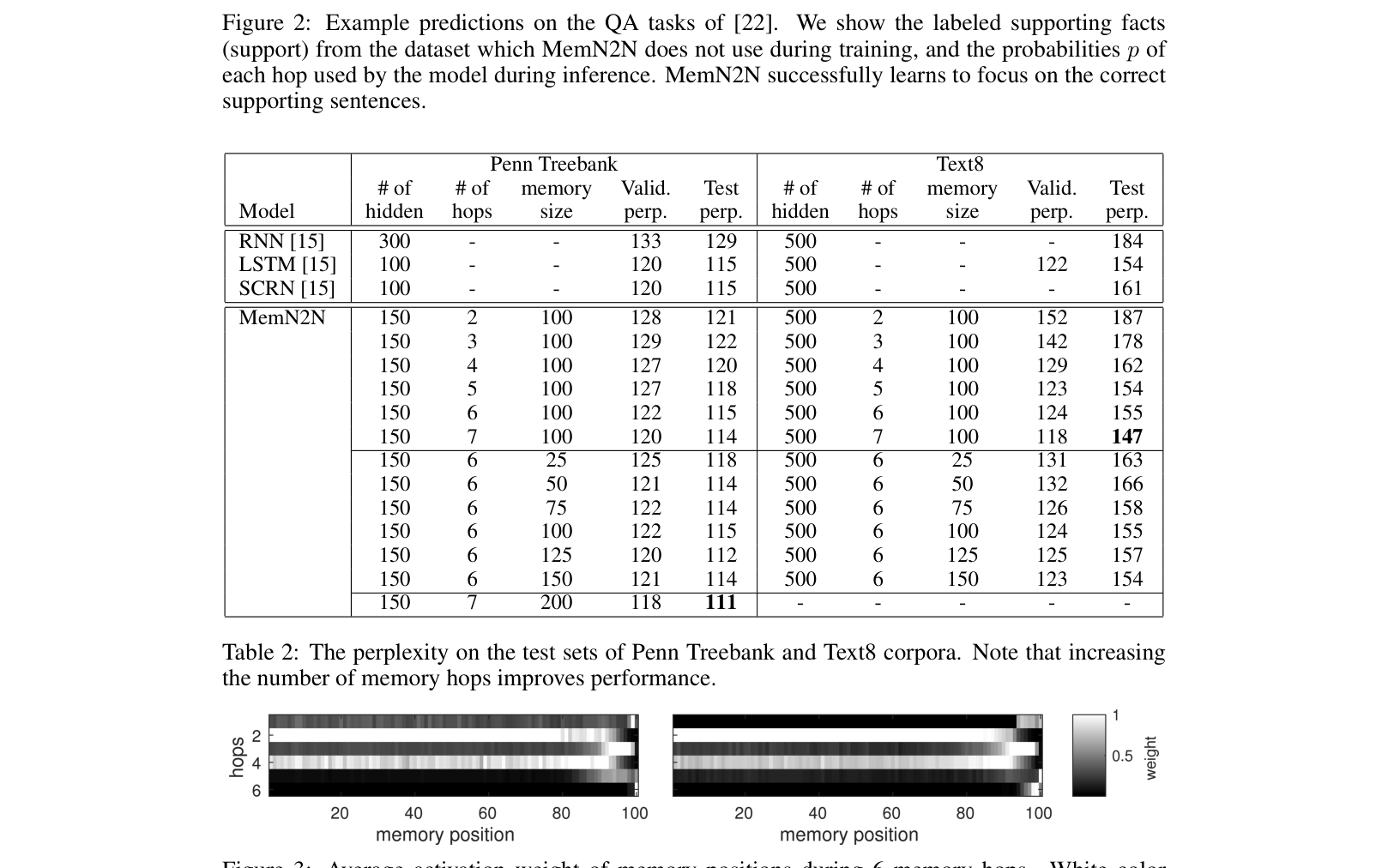
- Outperforms LSTM baselines on language modeling (Penn Treebank perplexity 111 vs. 115 for RNN/SCRN)
- Demonstrates that increasing memory hops (from 1 to 3+) consistently improves performance on both QA and language modeling tasks
Breakthrough Assessment
9/10
A foundational paper in memory-augmented networks. It introduced the standard attention-based memory mechanism used extensively later (e.g., in Transformers) and proved explicit memory could be trained end-to-end without strong supervision.