📝 Paper Summary
Memory internalization
Continual Learning (CL)
MEGa enables LLMs to continually learn and recall specific episodic memories by storing each memory in a dedicated, query-gated LoRA adapter rather than overwriting shared weights.
Core Problem
Standard fine-tuning for knowledge injection causes catastrophic forgetting of previous memories, while RAG relies on external buffers rather than internalizing knowledge like biological long-term memory.
Why it matters:
- Current methods struggle to sequentially add new memories without degrading general language capabilities or forgetting old data
- RAG models external environments rather than the biological process of long-term memory formation via synaptic changes
- Hebbian learning rules in classical RNNs fail to store highly correlated, semantic-rich data at scale
Concrete Example:
When a model sequentially learns stories about fictional characters (e.g., a trip to the Alps), standard fine-tuning (Full or LoRA) forgets earlier stories as it learns new ones. MEGa retains access to the 'Alps' story even after learning subsequent, unrelated events.
Key Novelty
Memory Embedded in Gated LLMs (MEGa)
- Assigns a unique, trainable LoRA adapter to each new memory (document) during the fine-tuning phase
- Freezes the adapter after training and stores a 'context key' (embedding) derived from the document
- At inference, a gating mechanism compares the user query to all context keys and activates only the relevant adapters via a weighted sum
Architecture
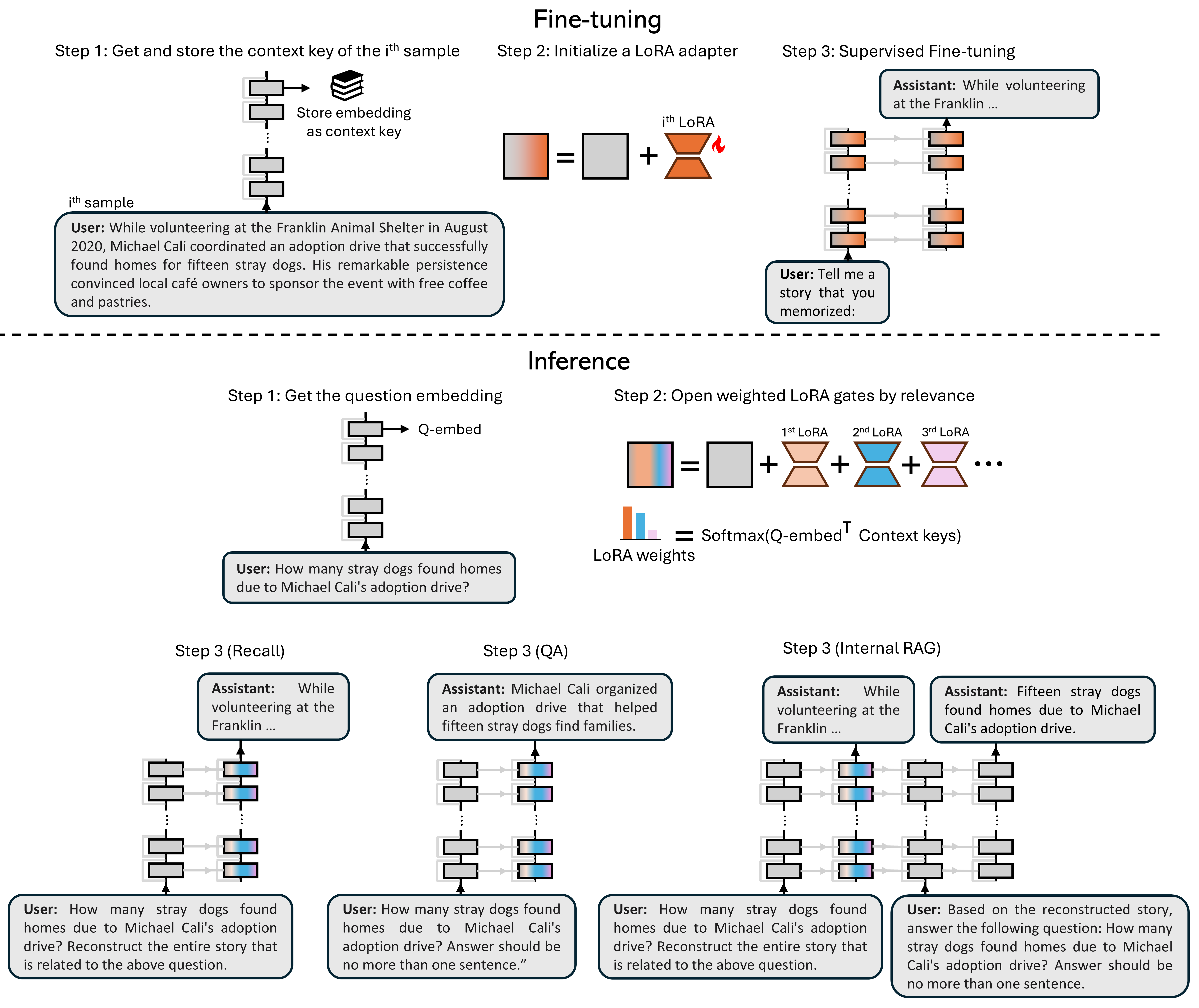
Schematic of MEGa's fine-tuning and inference process. It shows how distinct LoRA adapters are created for each memory and how a query-based gating mechanism selects them during inference.
Evaluation Highlights
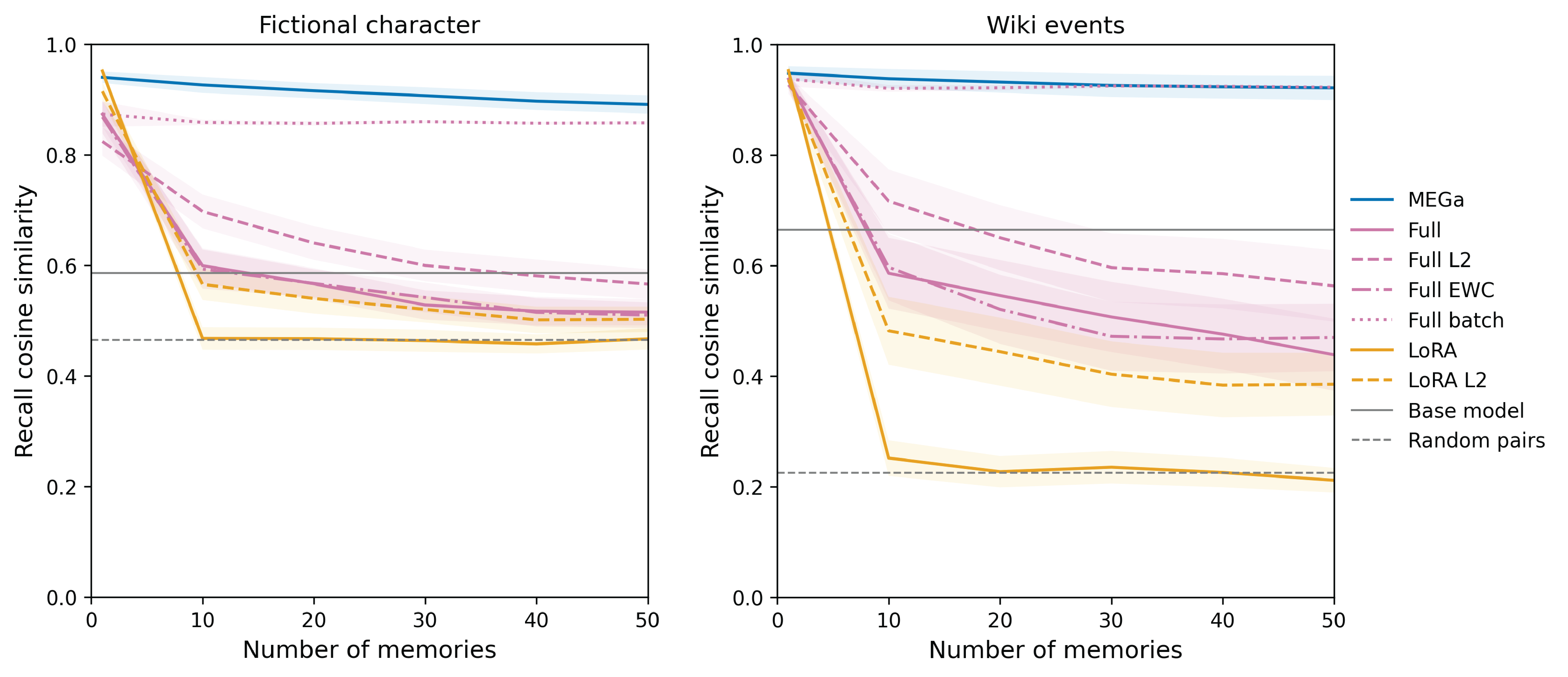
- Achieves >90% recall cosine similarity on Fictional Character dataset after 50 sequential tasks, while baselines (LoRA, Full) drop to <10%
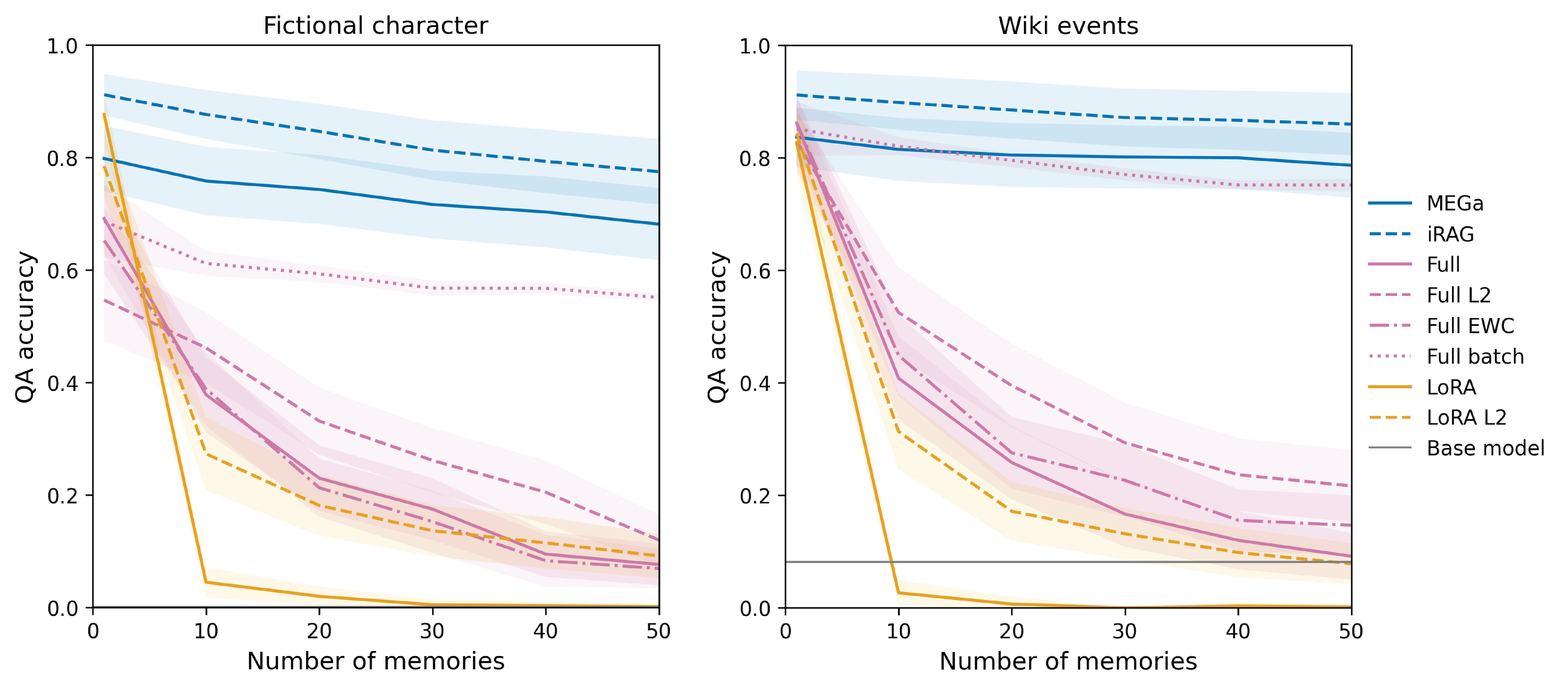
- Maintains near-perfect Question Answering accuracy (~100%) on Wikipedia events, significantly outperforming regularization baselines (EWC, L2) which degrade to ~20-40%
- Preserves general language ability (MMLU score ~66%) effectively, comparable to the frozen base model, whereas full fine-tuning degrades to ~38%
Breakthrough Assessment
7/10
Strong empirical results on mitigating catastrophic forgetting for sequential memory injection. The architecture is novel for this specific use case, though the scalability of storing one adapter per memory is a potential limitation.