📝 Paper Summary
Knowledge internalization
Memory organization
MEMOIR introduces a sparse residual memory layer that distributes updates across distinct parameter subsets for each edit, using activation-based hashing to retrieve relevant knowledge while minimizing interference.
Core Problem
Existing parametric model editing methods suffer from catastrophic forgetting during long sequences of edits because new updates overwrite parameters storing previous knowledge.
Why it matters:
- LLMs frequently require updates to correct outdated information or hallucinations without expensive full retraining
- Current methods fail to scale to thousands of sequential edits, degrading performance on both new and old data
- Balancing reliability (learning the edit), generalization (handling rephrasings), and locality (not damaging other knowledge) remains unsolved for long edit streams
Concrete Example:
When editing a model to update the answer for 'Where was the last Summer Olympics held?', standard methods might overwrite the weights used for a previous edit like 'Who won the 2020 World Cup?', causing the model to forget the earlier fact.
Key Novelty
Sparse Residual Memory with TopHash Retrieval
- Introduces a residual memory layer (a parallel fully-connected layer) initialized to zero, preserving the original pre-trained weights
- Uses 'TopHash': a mechanism that generates sample-dependent sparse masks based on activation magnitudes, ensuring only a small subset of memory parameters is updated per edit
- Retrieves edits at inference by comparing the sparse mask of a new query to stored edit masks; if they match (high overlap), the residual memory is activated, otherwise it is skipped.
Architecture
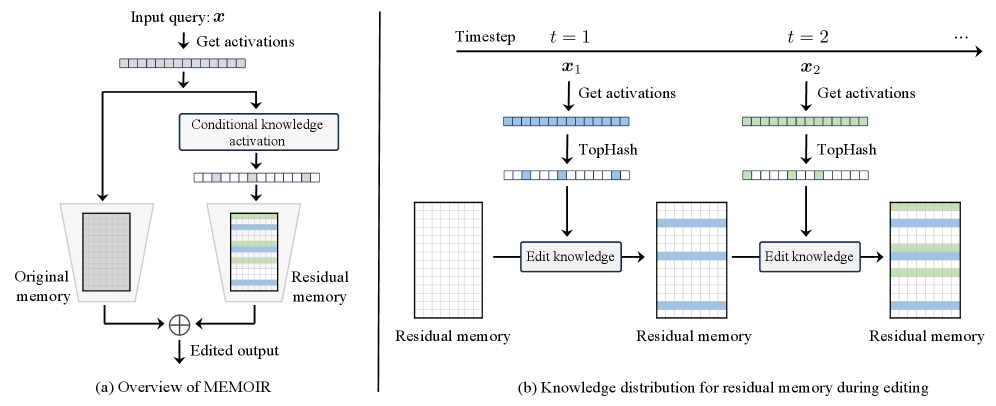
The workflow of MEMOIR. It shows the original FFN layer (frozen) and the parallel Residual Memory layer (trainable). It illustrates the 'TopHash' process generating a sparse mask from input activations, which is used to select specific columns in the Residual Memory for updating/retrieval.
Evaluation Highlights
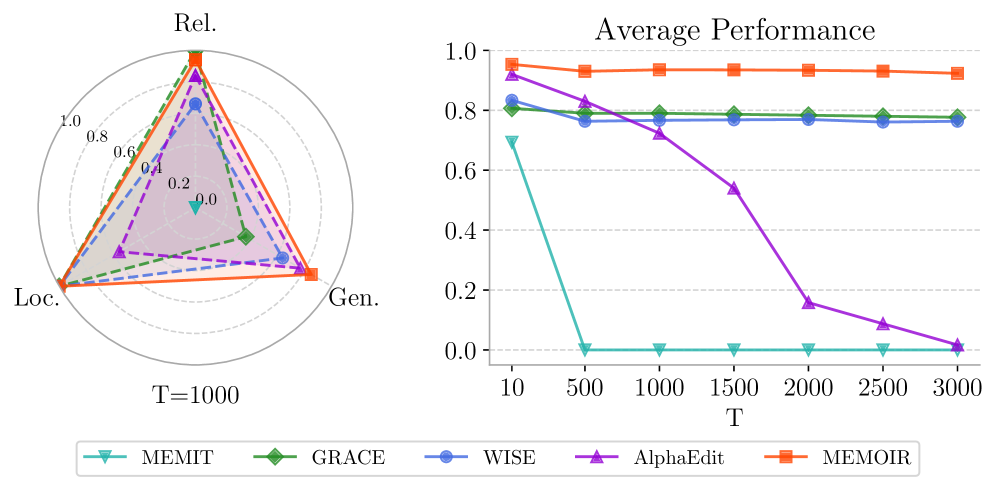
- Achieves state-of-the-art editing performance on LLaMA-3-8B, maintaining high reliability and locality even after 15,000 sequential edits
- Outperforms current methods (like GRACE and MALMEN) on multi-hop reasoning and hallucination correction benchmarks
- Significantly reduces catastrophic forgetting compared to ROME and MEMIT, which degrade rapidly as the number of edits increases
Breakthrough Assessment
8/10
Strong contribution to the specific sub-field of lifelong model editing. The use of sparse, activation-based addressing effectively solves the interference problem for large numbers of edits, a major bottleneck in current techniques.