📝 Paper Summary
Modularized RAG pipeline
Benchmark
The paper demonstrates that combining Retrieval-Augmented Generation (RAG) with fine-tuning cumulatively improves accuracy in domain-specific tasks, using a new pipeline for generating industrial agricultural datasets.
Core Problem
General-purpose Large Language Models (LLMs) lack specific, localized knowledge required for specialized industries like agriculture, and the trade-offs between RAG and fine-tuning for addressing this are poorly understood.
Why it matters:
- Farmers require location-specific advice (e.g., planting times vary by state) that general models often miss or hallucinate
- The industry lacks high-quality, structured training data due to information being locked in complex PDF formats
- Developers need guidance on whether to invest in RAG, fine-tuning, or both for industrial applications
Concrete Example:
When asked 'What is the best time to plant trees in Arkansas?', GPT-4 gives a generic answer. An expert gives specific months (Spring/Fall). A fine-tuned model leverages cross-geography knowledge to increase answer similarity to the expert from 47% to 72%.
Key Novelty
End-to-End Industrial Data Generation & Optimization Pipeline
- Proposes a comprehensive pipeline that extracts structure from PDFs (not just text), generates synthetic Q&A pairs using GPT-4, and uses these to fine-tune models
- Conducts a direct quantitative comparison of RAG, Fine-Tuning, and RAG + Fine-Tuning strategies specifically for the agriculture domain across multiple geographies (USA, Brazil, India)
Architecture
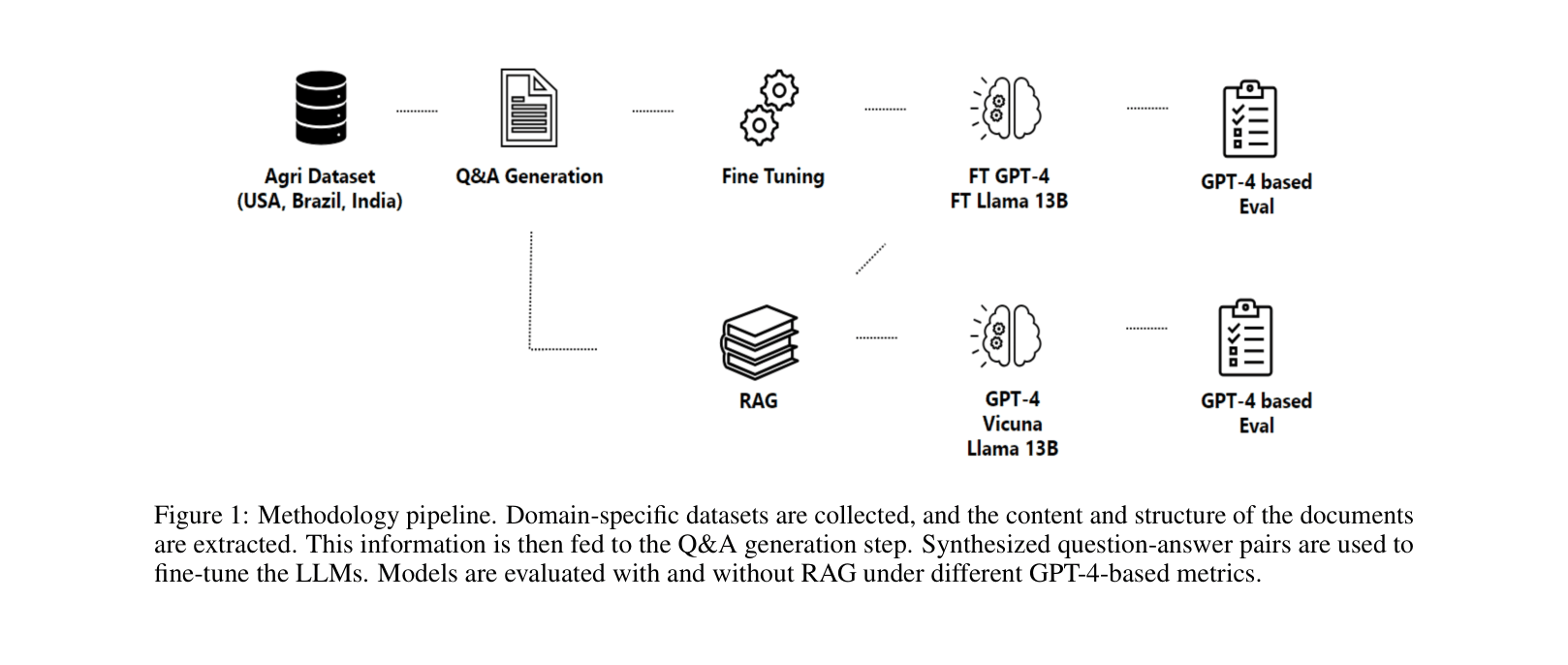
The end-to-end pipeline for dataset generation, model training, and evaluation
Evaluation Highlights
- Fine-tuning Llama2-13B increases accuracy by over 6 percentage points compared to the base model on agricultural queries
- Combining RAG with fine-tuning yields a cumulative effect, increasing accuracy by a further 5 percentage points (total >11 p.p. gain)
- Fine-tuning enables the model to leverage information across geographies, increasing answer similarity from 47% to 72% in specific experiments
Breakthrough Assessment
7/10
Provides a valuable, rigorous empirical study on the additive benefits of RAG and fine-tuning in a specific vertical (agriculture), though the underlying techniques (LoRA, RAG) are standard.