📝 Paper Summary
Transformer Interpretability
Mechanism Analysis
Feed-forward layers in Transformers function as key-value memories where keys detect specific input patterns (shallow or semantic) and values induce probability distributions over the output vocabulary.
Core Problem
Feed-forward layers constitute two-thirds of a Transformer's parameters, yet their specific role and internal mechanics remain largely unexplained compared to self-attention layers.
Why it matters:
- Understanding the dominant parameter blocks (FFNs) is crucial for interpretability, model debugging, and architectural improvements.
- Prior work focused heavily on self-attention, leaving a gap in understanding how the bulk of the model's capacity stores and retrieves information.
- Clarifying this mechanism could aid in controlling model predictions or understanding data privacy risks (memorization).
Concrete Example:
In a sentence ending with '...no substitutes', a specific FFN key activates. If we don't know this key correlates to the pattern 'substitutes at end of sentence' and its value predicts the next likely token, we cannot explain why the model outputs a specific word next.
Key Novelty
Feed-Forward Layers as Key-Value Memories
- Reinterprets the first parameter matrix of an FFN as 'keys' that match input patterns (like soft-lookup) and the second matrix as 'values' that output token distributions.
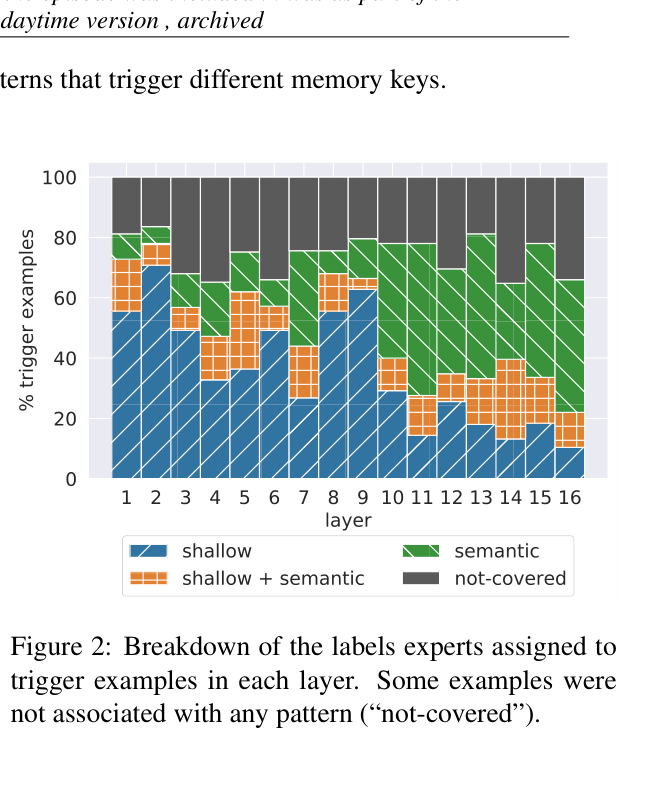
- Demonstrates that lower layers act as shallow pattern detectors (n-grams), while upper layers detect semantic concepts (topics).
- Shows that the final prediction is a composition of these memory retrievals, refined layer-by-layer via residual connections.
Architecture
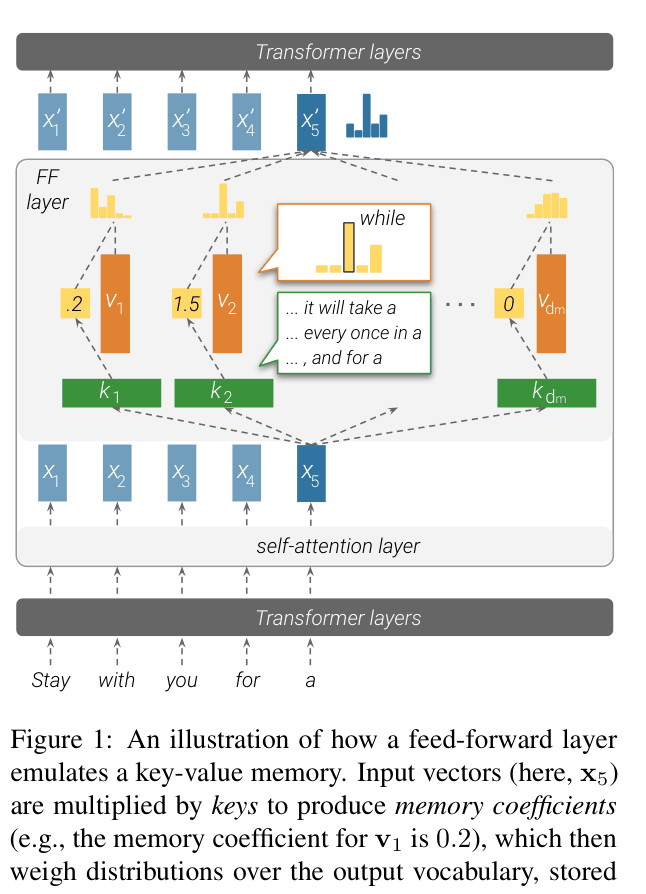
Illustration of the mapping between Feed-Forward Layer mathematics and Key-Value Memory mechanics.
Evaluation Highlights
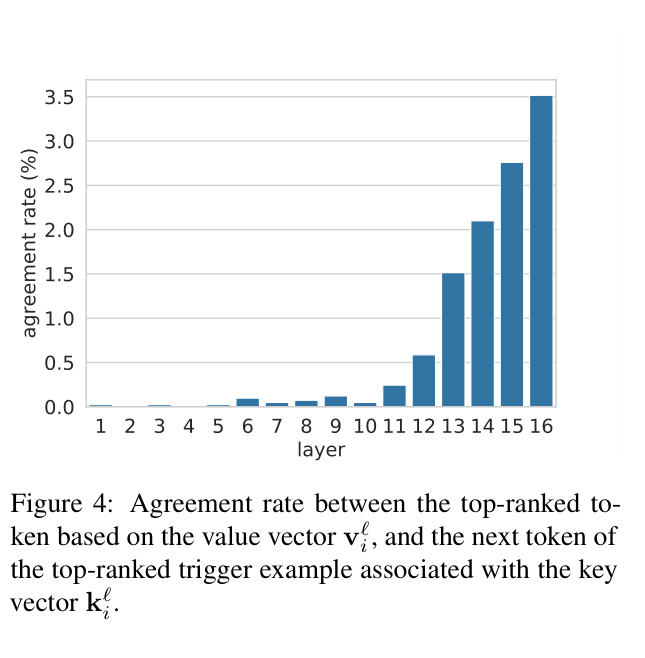
- In upper layers (11-16), value vectors correctly predict the next token of their key's trigger examples in up to 3.5% of cases (orders of magnitude above random chance ~0.0004%).
- Human experts identified coherent patterns for 100% of analyzed keys (average 3.6 patterns per key).
- In 68% of examples, the layer's final output differs from every single individual memory's top prediction, proving the mechanism is compositional.
Breakthrough Assessment
8/10
Provides a fundamental mechanistic explanation for the majority of Transformer parameters. Shifts the mental model of FFNs from generic non-linearities to interpretable memory stores.