📝 Paper Summary
Evaluation methodology
Factuality and hallucination
FActScore evaluates long-form text factuality by breaking generations into atomic facts and verifying them against a knowledge source, using either human annotation or a retrieval-augmented automated estimator.
Core Problem
Evaluating factual precision in long-form generation is difficult because texts contain a mixture of supported and unsupported information, making binary labels inadequate, and human verification is costly.
Why it matters:
- Current binary evaluations ignore partial correctness (e.g., a sentence with 3 true facts and 1 false fact is just labeled 'false')
- Even single sentences often contain multiple pieces of information (4.4 per sentence in ChatGPT), 40% of which are a mix of true and false
- Existing human evaluation is prohibitively expensive ($26K for 6,500 generations), preventing scalable assessment of new models
Concrete Example:
A model generates a bio: 'Michael Jordan played for the Bulls and the Mets.' A binary metric marks this as False because of the baseball error, ignoring the correct basketball fact. FActScore decomposes this into 'played for Bulls' (True) and 'played for Mets' (False), giving a more granular score.
Key Novelty
Atomic-level Factual Precision Scoring (FActScore)
- Decomposes long-form text into 'atomic facts' (short statements conveying one piece of information) rather than evaluating at the sentence or document level
- Defines truthfulness as 'supported by a specific knowledge source' (e.g., Wikipedia) rather than global truth, resolving ambiguity
- Proposes an automated estimator using a retrieve-then-verify pipeline to approximate human judgment without manual effort
Architecture
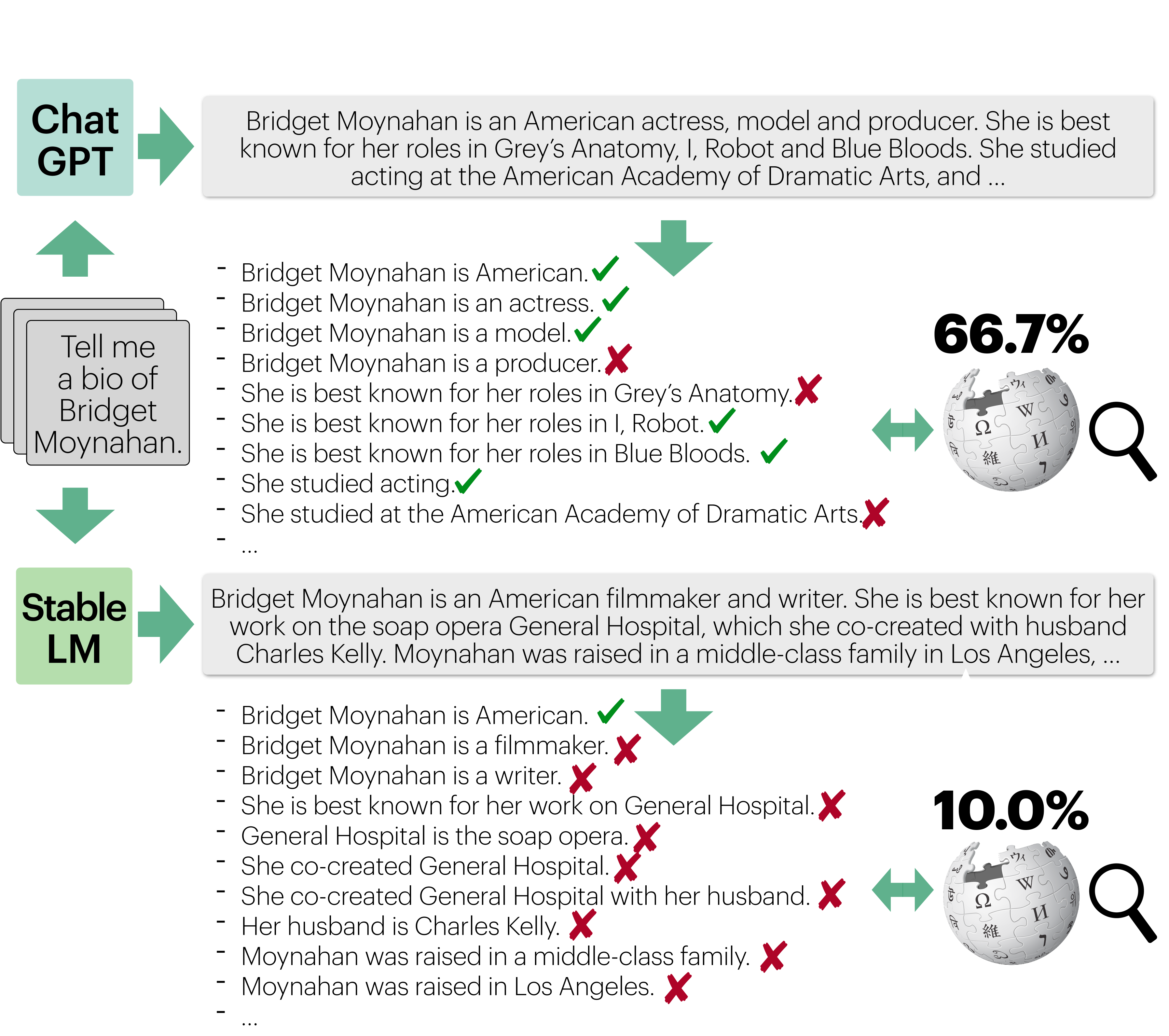
Illustration of the FActScore concept compared to binary labeling. It shows two generated biographies about 'Ed Yost'.
Evaluation Highlights
- Automatic estimator achieves <2% error rate compared to human ground truth when estimating FActScore for various LMs
- ChatGPT achieves only 58% FActScore on biography generation, significantly lower than expected for a state-of-the-art model
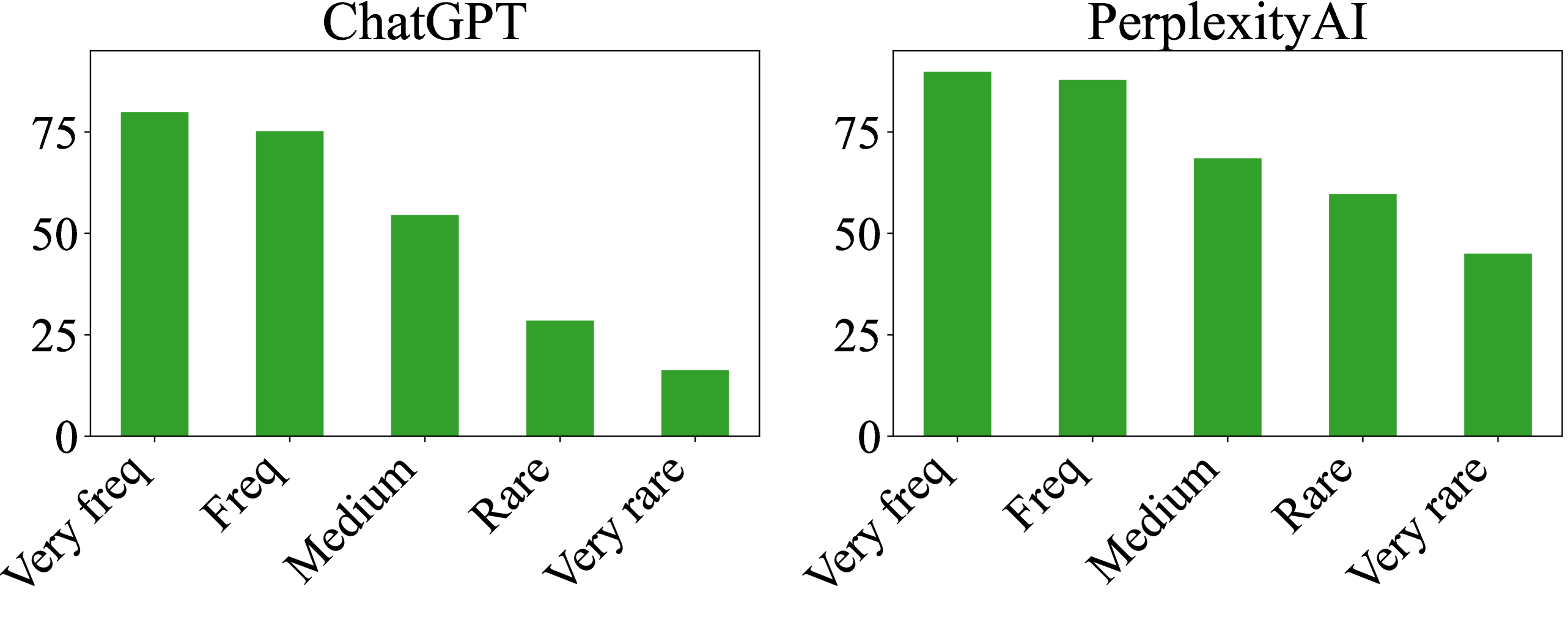
- PerplexityAI (search-augmented) scores 71.5%, dropping to 16% sentence-level accuracy for rare entities, showing search augmentation is not a silver bullet
Breakthrough Assessment
9/10
Establishes a rigorous standard for fine-grained factuality evaluation. The atomic decomposition approach and the release of an automated metric with <2% error rate are significant practical contributions.