📝 Paper Summary
Factuality evaluation
Long-form text generation
Hallucination detection
VeriScore improves long-form factuality evaluation by extracting only verifiable atomic claims (filtering out subjective or unverifiable content) and verifying them against Google Search results using fine-tuned open-weight models.
Core Problem
Existing factuality metrics like FActScore and SAFE assume all generated text can be decomposed into verifiable atomic claims, leading to errors when texts contain subjective, unverifiable, or complex content.
Why it matters:
- Current metrics extract unverifiable content (e.g., opinions, fictional stories) as claims, unfairly penalizing models when these cannot be verified
- Metrics optimized for biographies (like FActScore) fail on diverse tasks (like LFQA) where claims are not atomic or contain complex inter-sentence dependencies
- Relying solely on expensive closed-source models (GPT-4) for evaluation is costly and hinders reproducibility
Concrete Example:
In a generated text 'Betacyanin is like a superhero cape', existing metrics like SAFE extract 'Betacyanin is like a superhero cape' as a factual claim to verify, which is metaphorical and unverifiable, leading to a false penalty.
Key Novelty
VeriScore: Evaluating Verifiable Claims
- selectively extracts only 'verifiable claims' (statements describing specific events or states) rather than decomposing the entire text
- uses a sliding-window context approach during extraction to resolve pronouns and dependencies without a separate, expensive revision step
- provides a cost-effective implementation by fine-tuning open-weight models (Mixtral-8x22B, Llama-3) on high-quality data generated by GPT-4 and GPT-4o
Architecture
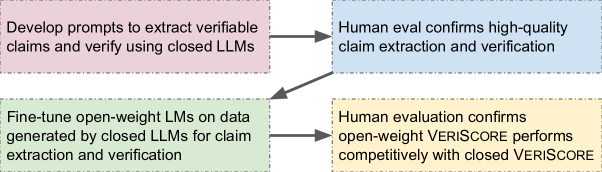
The VeriScore pipeline consisting of claim extraction and verification phases.
Evaluation Highlights
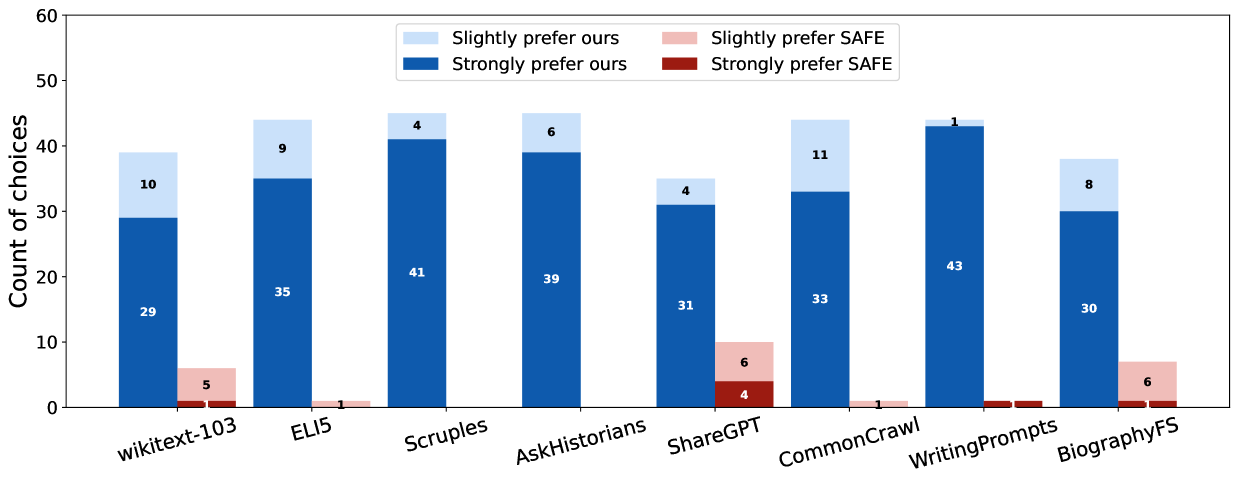
- Human annotators preferred VeriScore's claim extraction over SAFE's 93% of the time across diverse tasks
- VeriScore with Llama-3-70B achieves 0.77 Spearman correlation with human judgments on claim extraction (comparable to GPT-4's 0.79)
- GPT-4o achieves the highest average VeriScore (65.8) across 8 diverse datasets, while open-weight Mixtral-8x22B (60.9) is closing the gap with closed models
Breakthrough Assessment
8/10
Addresses a critical flaw in current factuality metrics (the assumption that all text is verifiable). The shift to 'verifiable claims' and the release of fine-tuned open-weight evaluators make this a practical and methodologically sound contribution.