📊 Experiments & Results
Evaluation Setup
Zero-shot question answering with autograding
Benchmarks:
- SimpleQA (Short-form Fact-seeking QA) [New]
Metrics:
- Overall Correct (%)
- Correct Given Attempted (%)
- F-score (harmonic mean of Correct and Correct Given Attempted)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Performance of OpenAI models shows scaling behavior, with larger models outperforming smaller ones. | ||||
| SimpleQA | Overall Correct | 8.6 | 38.2 | +29.6 |
| SimpleQA | Overall Correct | 24.7 | 41.6 | +16.9 |
| Performance of Anthropic models; Claude 3.5 Sonnet performs competitively but attempts fewer questions. | ||||
| SimpleQA | Overall Correct | 6.8 | 24.4 | +17.6 |
| SimpleQA | Not Attempted | 12.8 | 41.6 | +28.8 |
Experiment Figures
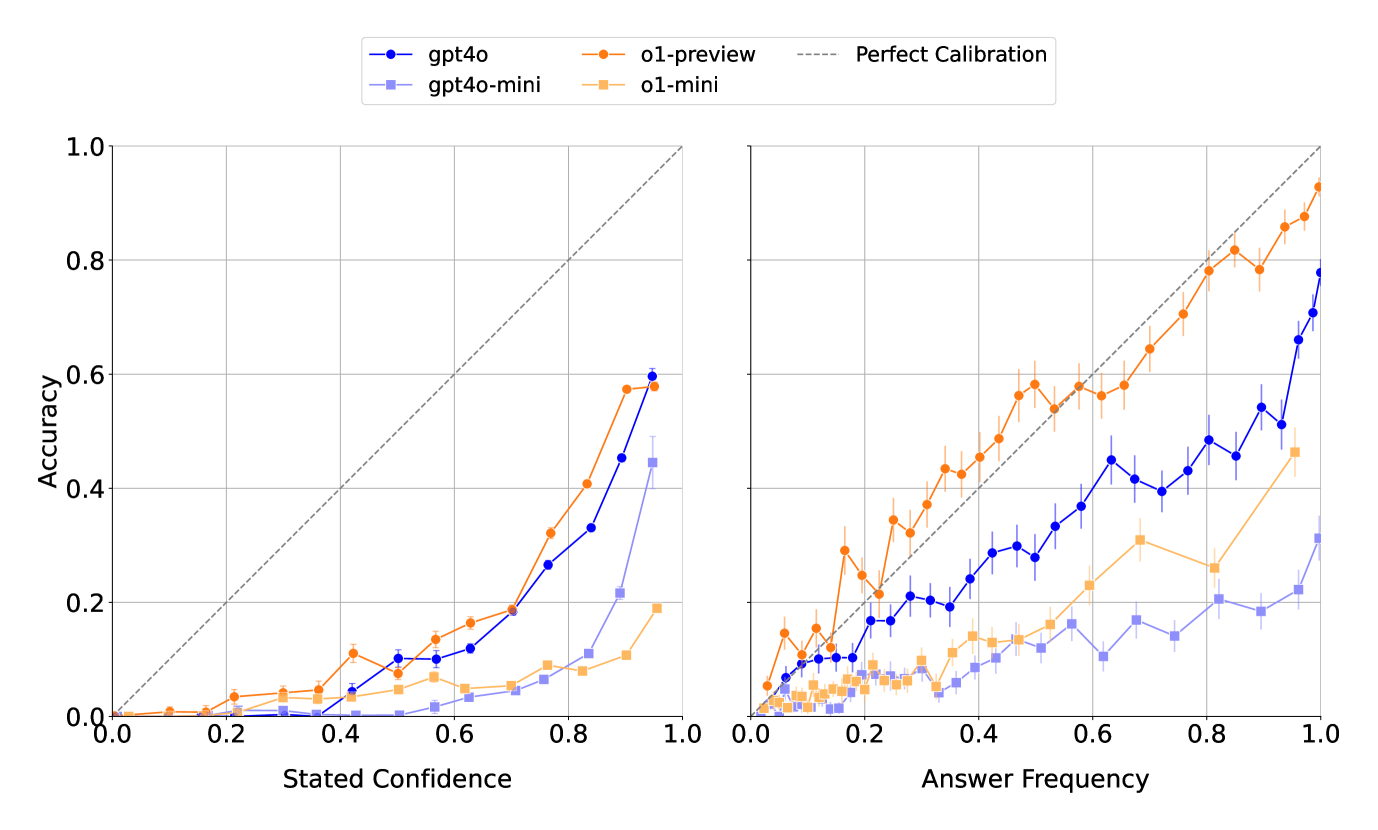
Calibration plot: Stated Confidence (x-axis) vs. Actual Accuracy (y-axis) for 4 OpenAI models
Calibration plot: Frequency of Same Answer (x-axis) vs. Accuracy (y-axis) over 100 samples
Main Takeaways
- SimpleQA is challenging: even top models (o1-preview, gpt-4o) score below 45% correct, while older benchmarks are saturated.
- Larger models are better calibrated: o1-preview and gpt-4o show better correlation between confidence and accuracy than their mini counterparts.
- Models are generally overconfident: stated confidence consistently exceeds actual accuracy (performance below y=x line).
- Claude models exhibit different behavior, attempting significantly fewer questions (higher refusal rates) compared to GPT-4o models.