📝 Paper Summary
Prompt Engineering
Zero-shot Reasoning
Chain-of-Thought (CoT)
Plan-and-Solve Prompting replaces simple zero-shot triggers with explicit instructions to devise a plan and execute it, reducing missing steps and calculation errors in LLM reasoning.
Core Problem
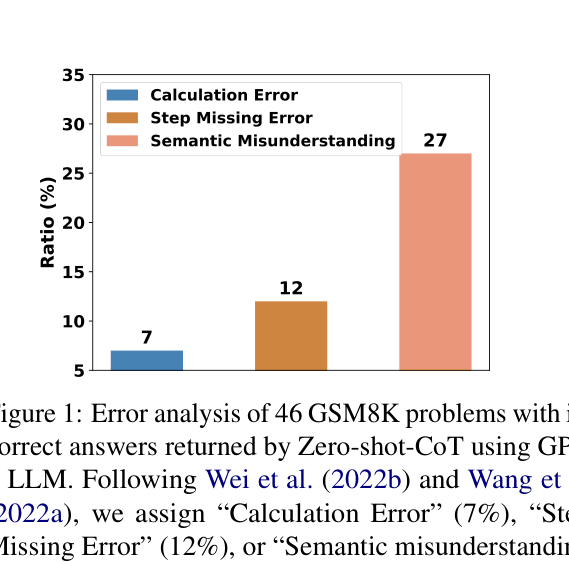
Zero-shot Chain-of-Thought (CoT) prompting often fails due to calculation errors, missing reasoning steps, and semantic misunderstandings.
Why it matters:
- Existing Zero-shot-CoT ('Let's think step by step') lacks specific guidance, leading models to skip crucial intermediate steps in complex multi-step problems
- Few-shot CoT requires manually crafting task-specific demonstrations, which is labor-intensive and not always feasible for every new task
Concrete Example:
In a math problem about combining weights, Zero-shot-CoT might immediately jump to adding numbers without defining variables, missing a step. Plan-and-Solve explicitly prompts: 'Let's first understand the problem... devise a plan... then carry out the plan', ensuring the variable is defined before calculation.
Key Novelty
Plan-and-Solve (PS) Prompting
- Replaces the generic 'Let's think step by step' trigger with a two-stage instruction: first devise a plan to break the task into subtasks, then execute that plan
- PS+ Prompting extends this by adding specific instructions to extract variables and pay attention to calculations, acting as a checklist for the LLM during generation
Architecture
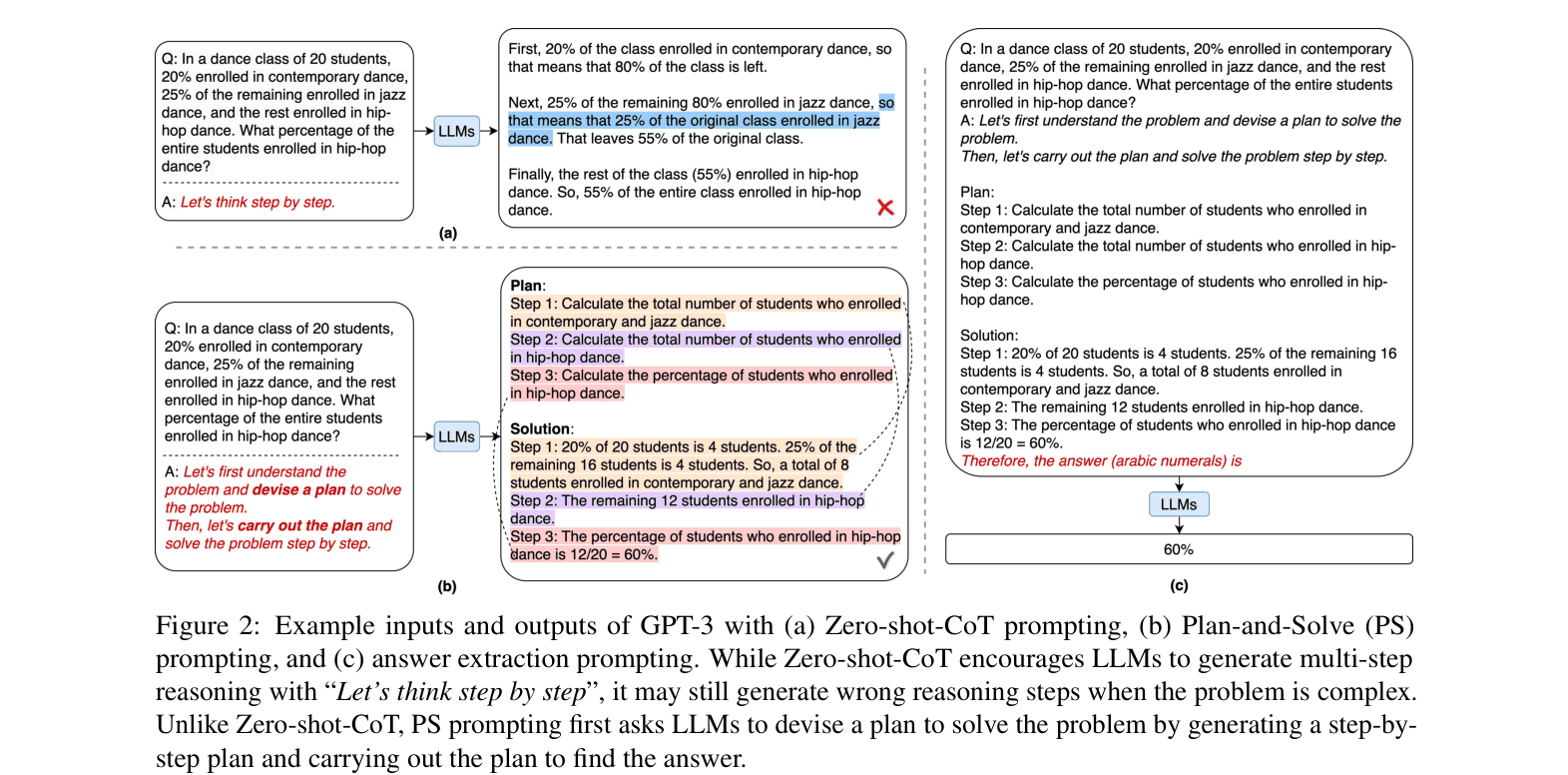
Comparison of prompt templates and outputs between Zero-shot-CoT and Plan-and-Solve (PS) Prompting.
Evaluation Highlights
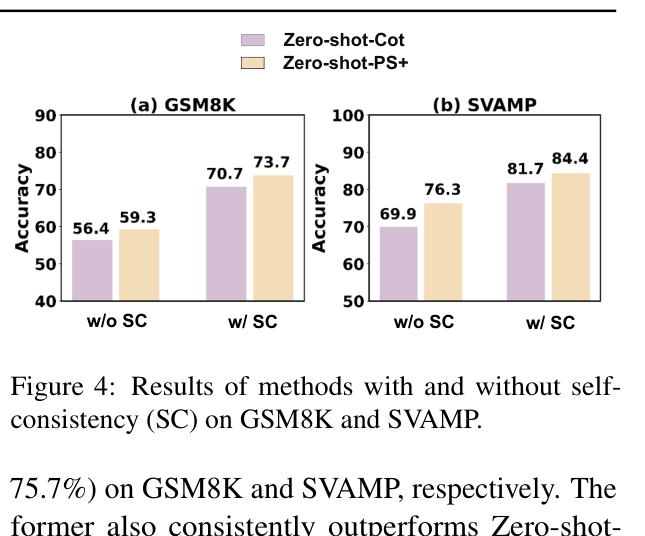
- Outperforms Zero-shot-CoT on all 6 arithmetic datasets, with a +2.5% average accuracy gain for basic PS and +6.3% for PS+
- PS+ prompting (76.7% average) performs comparably to 8-shot Manual-CoT (77.6%) on arithmetic reasoning without needing any demonstration examples
- Achieves 99.6% accuracy on the Coin Flip symbolic reasoning task, effectively matching the 100% accuracy of few-shot baselines
Breakthrough Assessment
7/10
Significant improvement over Zero-shot-CoT with minimal cost (just a better prompt). Bridges the gap between zero-shot and few-shot performance, though fundamentally an incremental prompt engineering technique.