📝 Paper Summary
Chain-of-Thought Reasoning
Self-Improvement / Bootstrapping
Reasoning Dataset Generation
STaR iteratively bootstraps a language model's reasoning ability by generating rationales, filtering for correct answers, and retraining on those successful rationales, using hint-based rationalization for failed problems.
Core Problem
Generating high-quality reasoning (rationales) usually requires massive human-annotated datasets or relies on few-shot prompting, which sacrifices accuracy compared to fine-tuning.
Why it matters:
- Manual rationale annotation is expensive and scales poorly to new domains
- Template-based generation only works when general solutions are already known
- Few-shot prompting with rationales underperforms models fine-tuned on large datasets, creating a gap between few-shot inference and fully supervised learning
Concrete Example:
In arithmetic, a model might fail to sum two numbers because it cannot generate the intermediate 'scratchpad' steps correctly. Standard training without rationales fails to generalize. Few-shot prompting helps but is limited by context window and lacks the performance of fine-tuning.
Key Novelty
Self-Taught Reasoner (STaR)
- Iterative Loop: The model generates its own training data by attempting to solve problems with rationales; only rationales leading to correct final answers are kept for fine-tuning.
- Rationalization: For problems the model initially fails to solve, it is given the correct answer as a hint to generate a rationale backwards. This data is then treated as valid training data (without the hint) to teach the model how to solve hard problems.
Architecture
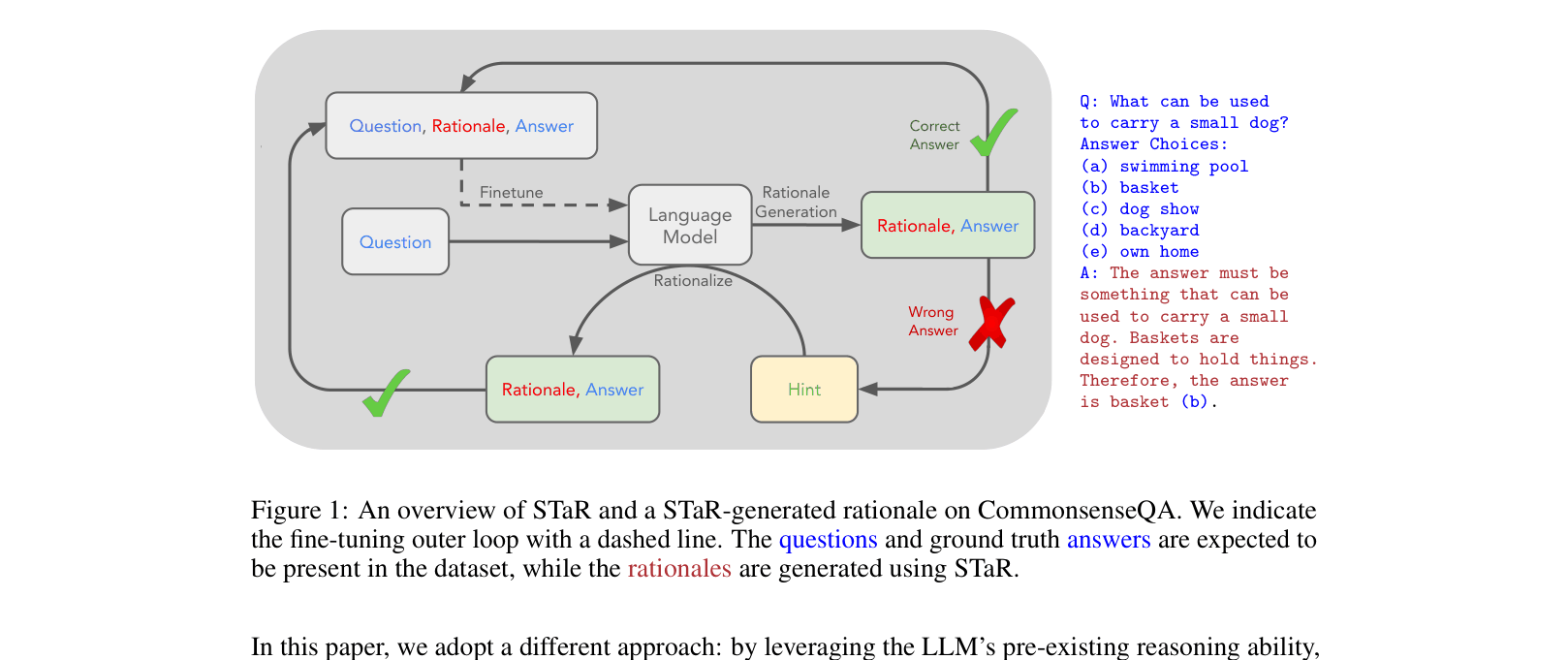
The STaR loop: generating rationales, filtering for correctness, fine-tuning, and the rationalization loop where answers are provided as hints for failed questions.
Evaluation Highlights
- +12.5% accuracy improvement on CommonsenseQA compared to a GPT-J baseline fine-tuned to directly predict answers
- Performance comparable to a 30x larger GPT-3 model (72.5% vs 73.0%) on CommonsenseQA
- Improves 2-digit addition accuracy from <1% to 32% in a single iteration using rationalization
Breakthrough Assessment
8/10
A significant methodology for self-improving reasoning without large human-labeled datasets. The introduction of 'rationalization' to learn from failures is a clever and effective contribution.