📝 Paper Summary
Mathematical Reasoning
LLM Scaling Laws
Data Augmentation
Empirically establishes scaling laws for math reasoning, finding pre-training loss predicts performance better than model size, and rejection sampling fine-tuning (RFT) significantly boosts performance via diverse reasoning paths.
Core Problem
The scaling relationship between LLM capacity (parameters, pre-training loss) and mathematical reasoning ability is under-explored, making it difficult to predict performance or optimize data collection efforts.
Why it matters:
- Understanding these laws helps allocate resources efficiently between pre-training better base models versus collecting more supervised data.
- Generating high-quality math data is expensive; knowing how augmented data (RFT) scales is crucial for improving models without human effort.
- Current methods often rely on expensive inference-time techniques (e.g., majority voting), whereas this work focuses on improving the base supervised model for efficient single-inference deployment.
Concrete Example:
A LLaMA-7B model fine-tuned on standard data achieves only 35.9% on GSM8K. Simply increasing model size to 65B is expensive, while the paper shows that augmenting data via rejection sampling can boost the 7B model to 49.3%, rivaling larger models.
Key Novelty
Rejection Sampling Fine-Tuning (RFT) scaling & Pre-training Loss Indicator
- Identifies pre-training loss as a better predictor of reasoning performance than parameter count.
- Proposes Rejection Sampling Fine-Tuning (RFT) to augment data using the model's own correct reasoning paths.
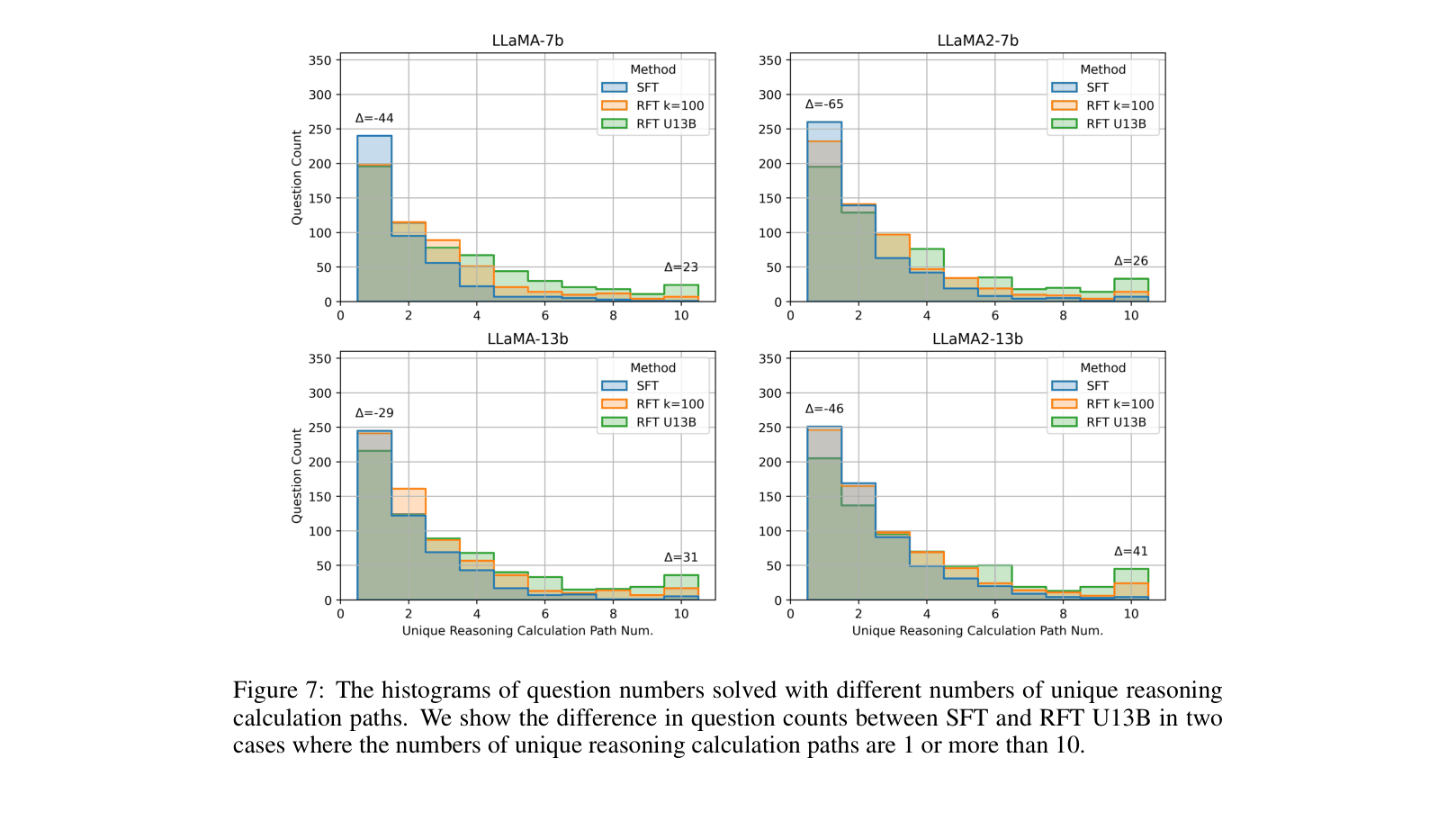
- Demonstrates that RFT performance scales with the number of *distinct* reasoning paths, and aggregating paths from multiple models yields superior results.
Architecture
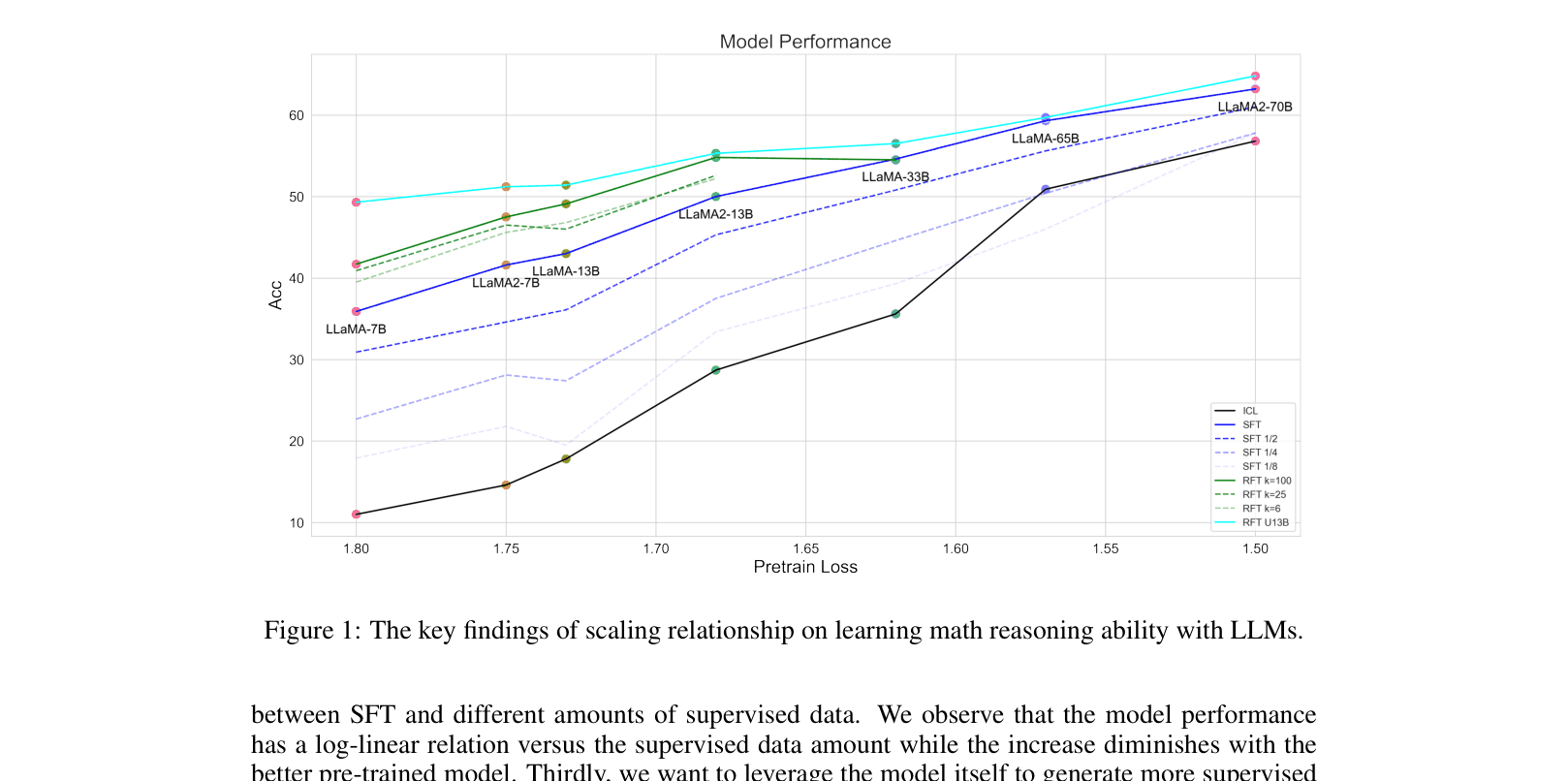
A conceptual summary of the scaling relationships found in the paper.
Evaluation Highlights
- LLaMA-13B with multi-model RFT achieves 52.1% accuracy on GSM8K, outperforming standard SFT (43.0%) by +9.1 points.
- LLaMA-7B with multi-model RFT reaches 49.3%, surpassing the standard SFT baseline of 35.9% by +13.4 points.
- Pre-training loss shows a strong linear correlation with SFT accuracy, while doubling supervised data volume yields log-linear improvements.
Breakthrough Assessment
7/10
Provides valuable empirical scaling laws for math reasoning and a highly effective, simple data augmentation strategy (RFT) that significantly boosts open-source model performance.