📝 Paper Summary
Prompt Engineering
Chain of Thought Reasoning
Zero-Shot Learning
Large language models can perform complex multi-step reasoning zero-shot by simply adding the prompt 'Let's think step by step' before the answer, without needing task-specific examples.
Core Problem
Large language models (LLMs) struggle with multi-step reasoning tasks (like arithmetic) in standard zero-shot settings, typically requiring carefully crafted few-shot examples to elicit reasoning.
Why it matters:
- Creating task-specific few-shot examples requires manual engineering and expertise, limiting the broad applicability of LLMs.
- The assumption that LLMs require few-shot examples to reason obscures their fundamental zero-shot capabilities.
- Standard scaling laws for LLMs often fail on system-2 tasks (slow, multi-step reasoning) without specific prompting techniques.
Concrete Example:
In a math problem asking for the number of blue golf balls, a standard zero-shot model immediately guesses a wrong number. In contrast, Zero-shot-CoT forces the model to articulate 'There are 16 balls... Half are golf balls...' leading to the correct answer.
Key Novelty
Zero-shot Chain of Thought (Zero-shot-CoT)
- Proposes a single, task-agnostic prompt ('Let's think step by step') to trigger multi-step reasoning in LLMs without any examples.
- Uses a two-stage prompting pipeline: first to generate the reasoning path, and second to extract the final concise answer from that reasoning.
Architecture
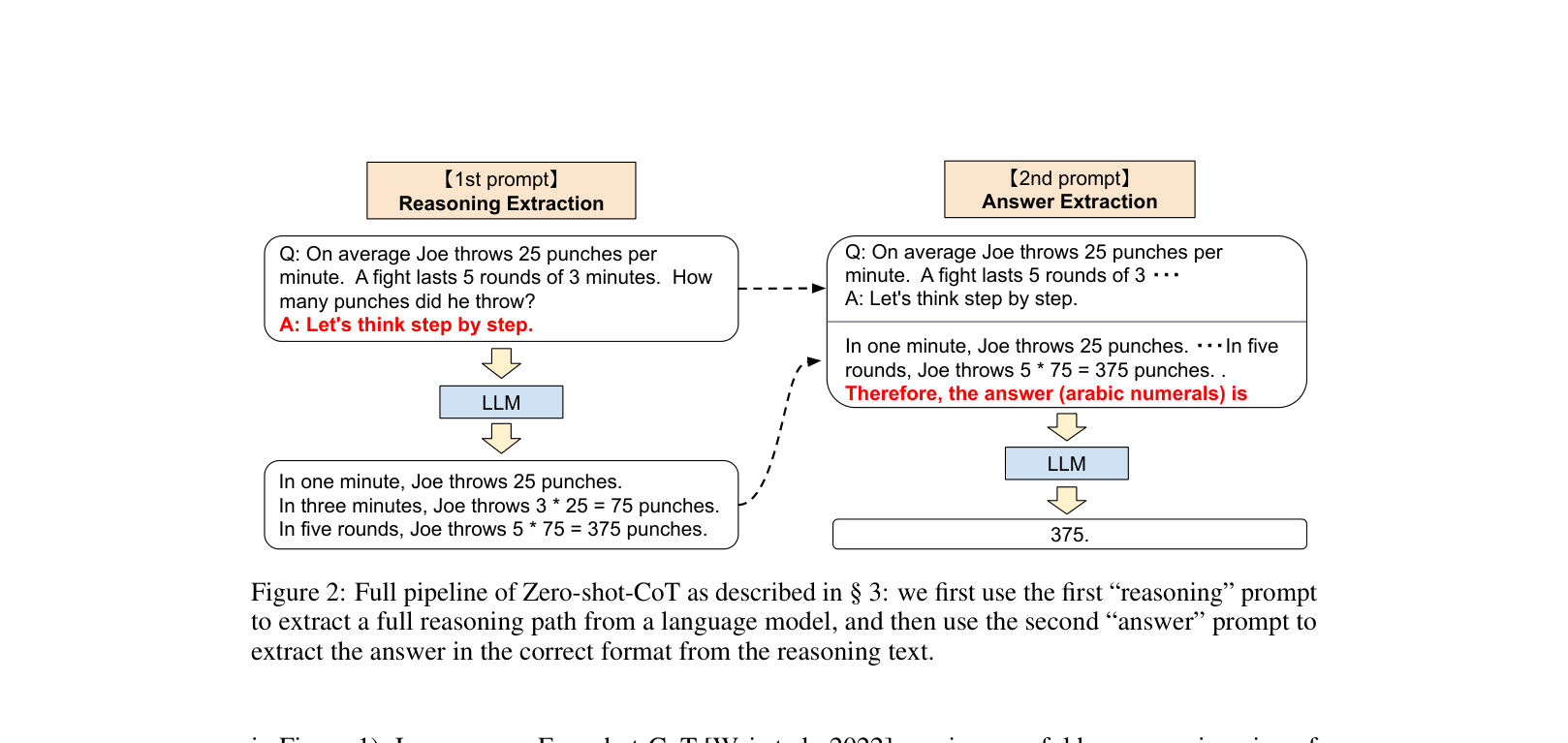
The full pipeline of Zero-shot-CoT compared to standard prompting.
Evaluation Highlights
- Increases accuracy on MultiArith from 17.7% (standard zero-shot) to 78.7% (Zero-shot-CoT) using text-davinci-002.
- Improves GSM8K performance from 10.4% to 40.7% with text-davinci-002, significantly closing the gap with few-shot methods.
- Outperforms standard Few-shot prompting (without CoT) on MultiArith even when the few-shot baseline uses 8 examples (78.7% vs 33.8%).
Breakthrough Assessment
9/10
A seminal paper that fundamentally changed how researchers interact with LLMs, proving that reasoning is an emergent zero-shot capability triggerable by a simple phrase rather than requiring complex few-shot engineering.