📝 Paper Summary
Prompt Engineering
Reasoning
Chain-of-thought prompting enables large language models to solve complex reasoning tasks by generating intermediate natural language steps before the final answer, without any model parameter updates.
Core Problem
Standard few-shot prompting works poorly on tasks requiring multi-step reasoning (arithmetic, commonsense, symbolic), and scaling model size alone does not sufficiently solve these problems.
Why it matters:
- Scaling laws alone have shown diminishing returns or flat scaling curves for complex reasoning tasks
- Fine-tuning models for reasoning requires large, expensive datasets of rationales
- Standard prompting (Input -> Answer) forces models to perform complex computations in a single pass, often leading to errors
Concrete Example:
Question: 'The cafeteria had 23 apples... used 20... bought 6 more. How many...?' Standard prompting outputs '27' (incorrect). Chain-of-thought prompting outputs 'The cafeteria had 23 apples... used 20... had 23-20=3... bought 6... 3+6=9. The answer is 9.' (correct).
Key Novelty
Chain-of-Thought Prompting
- Augment few-shot exemplars with a series of intermediate natural language reasoning steps (a 'chain of thought') that leads to the final answer
- Elicit the same step-by-step reasoning behavior in the model's output simply by showing it examples, rather than fine-tuning
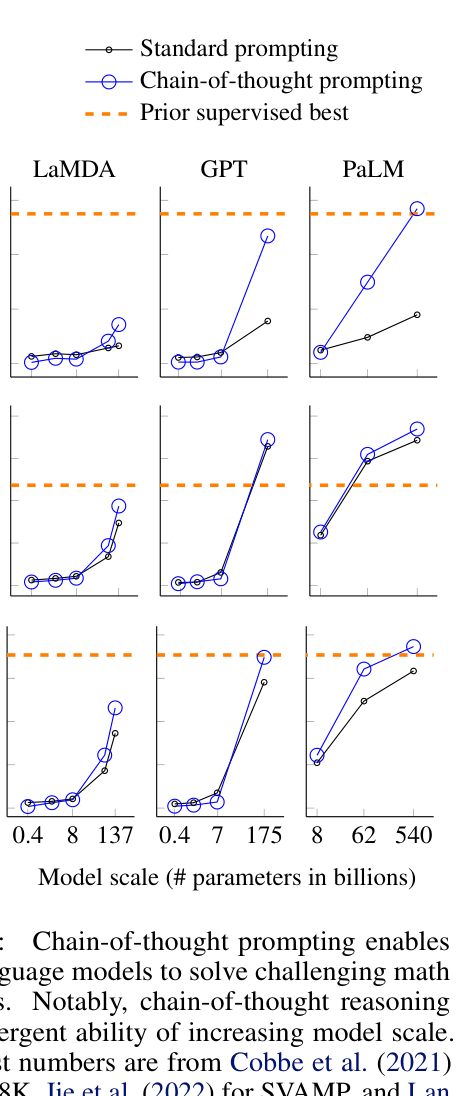
- Demonstrate that this ability is an emergent property of model scale, only appearing in sufficiently large language models (~100B+ parameters)
Architecture
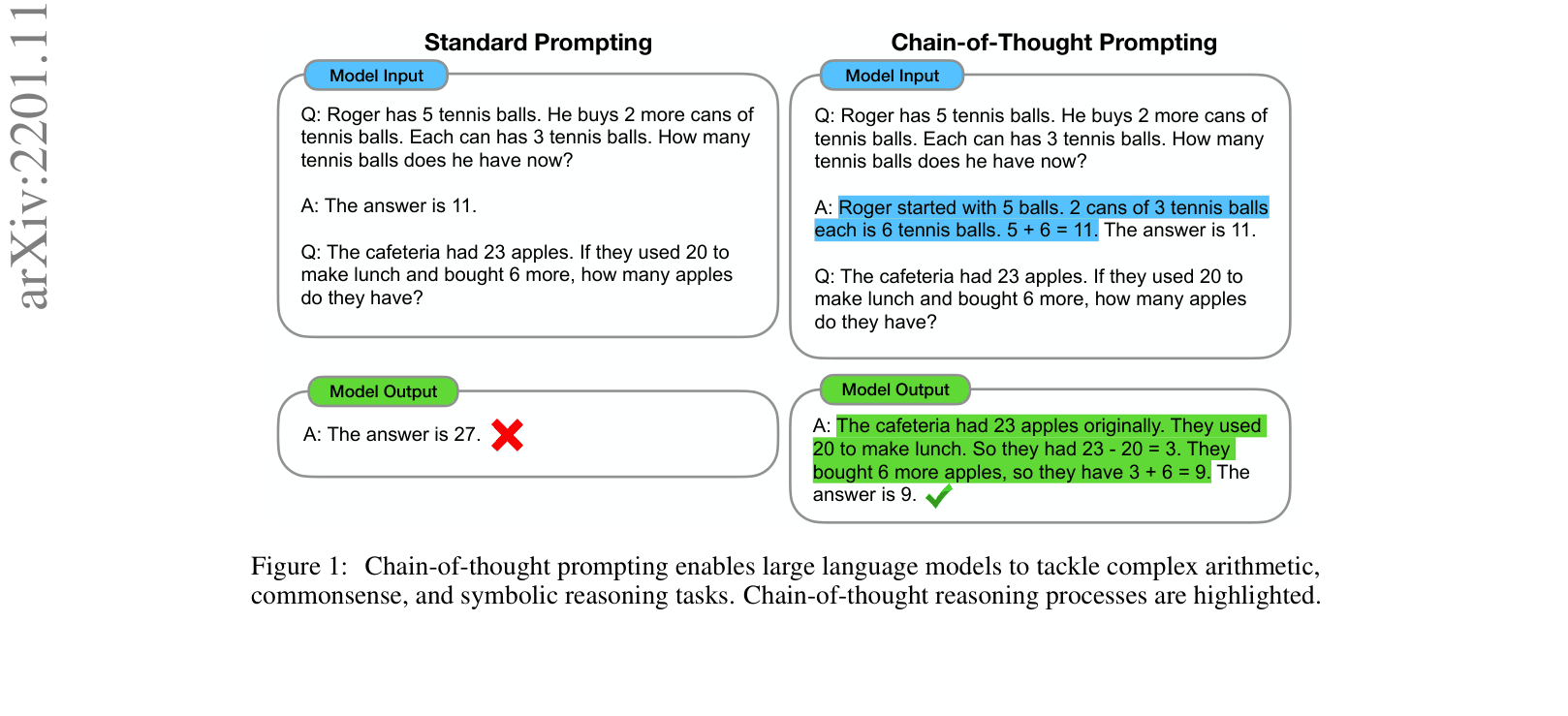
Comparison of Standard Prompting vs. Chain-of-Thought Prompting inputs and outputs.
Evaluation Highlights
- PaLM 540B with chain-of-thought prompting achieves 58% solve rate on GSM8K, surpassing the prior supervised state-of-the-art of 55%
- Chain-of-thought prompting enables near-perfect solve rates (approx 100% and 90%+) on symbolic tasks (Coin Flip, Last Letter Concatenation) where standard prompting completely fails
- Outperforms standard prompting on StrategyQA (75.6% vs ~60s%) and Sports Understanding (95.4% vs ~80s%) using PaLM 540B
Breakthrough Assessment
10/10
This is a seminal paper that introduced 'chain-of-thought' prompting, fundamentally changing how LLMs are used for reasoning. It demonstrated emergent abilities and unlocked performance previously thought impossible without fine-tuning.