📝 Paper Summary
Prompt Engineering
Large Language Model Reasoning
Compositional Generalization
Least-to-most prompting enables large language models to solve complex reasoning tasks harder than their prompt exemplars by decomposing problems into simpler subproblems and solving them sequentially.
Core Problem
Chain-of-thought prompting often fails on tasks requiring generalization to problems harder or longer than the provided few-shot exemplars (easy-to-hard generalization).
Why it matters:
- Language models typically struggle to generalize from short training examples to long test cases (length generalization), unlike humans
- Existing neural-symbolic approaches for compositional generalization benchmarks like SCAN require training on thousands of examples, whereas prompting uses almost none
- Standard few-shot prompting hits a ceiling on complex symbolic manipulation and multi-step math problems where reasoning depth exceeds the prompt's scope
Concrete Example:
In the last-letter-concatenation task, chain-of-thought prompting correctly solves lists of length 4 (seen in prompt) but fails completely (0% accuracy) on lists of length 12. It fails to generalize the recursion needed for longer sequences.
Key Novelty
Least-to-Most Prompting
- Decomposition Stage: Prompts the model to break a complex problem down into a list of simpler subproblems using few-shot exemplars demonstrating decomposition.
- Subproblem Solving Stage: Sequentially solves each subproblem, appending the answer to the previous subproblem to the context for the next one.
- Progressive Context: borrow from educational psychology where the model is 'taught' to build answers recursively using previous results.
Architecture
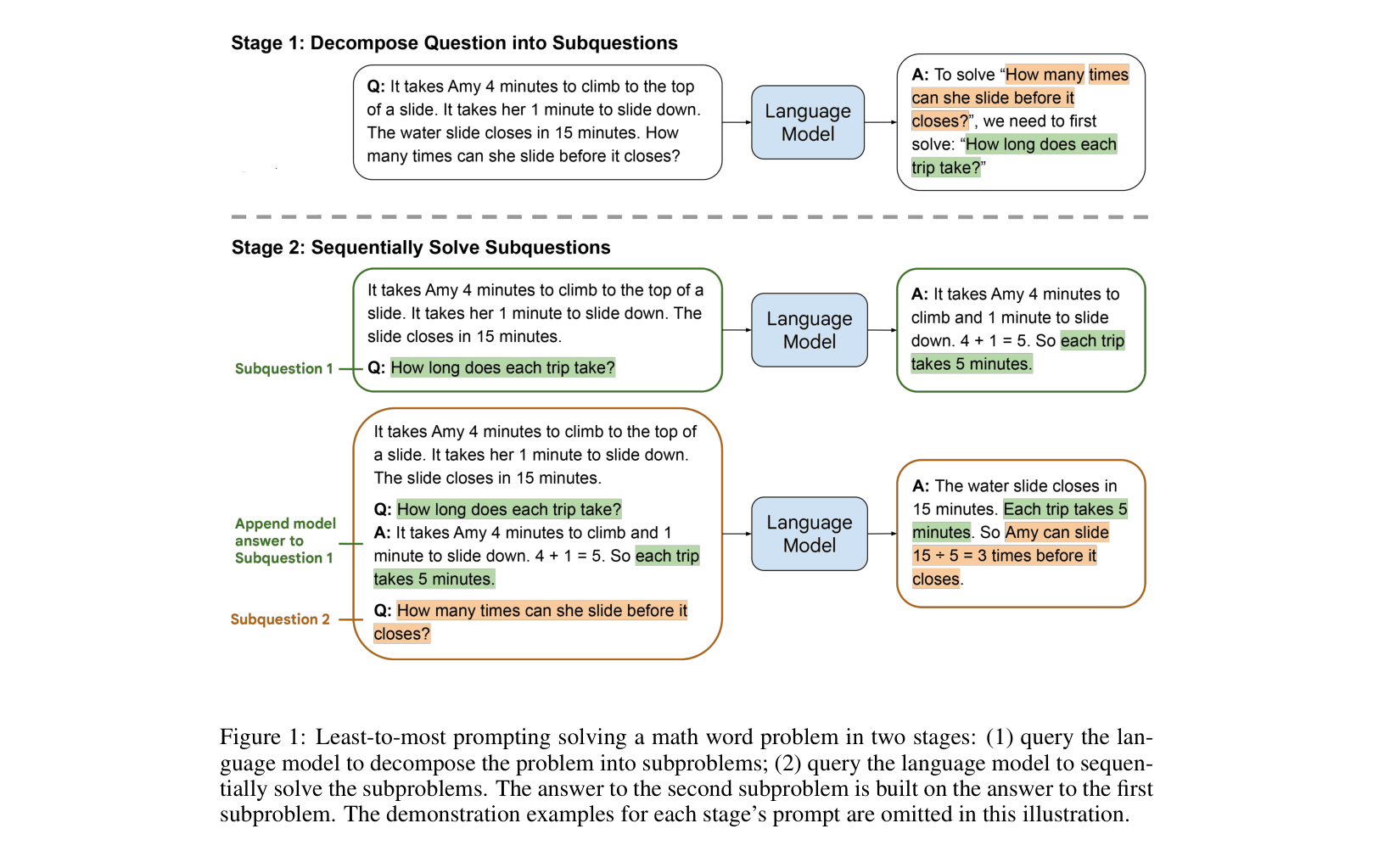
Illustration of the two-stage Least-to-Most prompting process on a math word problem.
Evaluation Highlights
- 99.7% accuracy on SCAN length split using code-davinci-002 with just 14 exemplars, compared to 16.2% with chain-of-thought prompting.
- 74.0% accuracy on last-letter-concatenation for length-12 lists (harder than prompt), while chain-of-thought gets 31.8% and standard prompting gets 0%.
- Improvements on GSM8K math reasoning for problems requiring 5+ steps, raising accuracy from 39.07% (Chain-of-Thought) to 45.23%.
Breakthrough Assessment
9/10
Achieved near-perfect results on the SCAN length split via prompting alone, a massive leap over previous prompting methods and comparable to specialized trained models, essentially solving a major OOD generalization benchmark.