📝 Paper Summary
Iterative refinement
Self-correction
Feedback generation
SELF-REFINE enables a single Large Language Model (LLM) to iteratively improve its own outputs by generating feedback on its drafts and then refining them, without requiring additional training or supervised data.
Core Problem
LLMs often produce suboptimal initial outputs for complex tasks (like code optimization or dialogue), and existing refinement methods typically require expensive supervised training data or separate reward models.
Why it matters:
- Training separate refinement models requires large, domain-specific datasets which are often unavailable.
- Reinforcement learning approaches (RLHF) rely on costly human annotations or reward models.
- Models like GPT-4 have latent capabilities to correct errors but don't utilize them in standard one-pass generation.
Concrete Example:
When asking a model to 'Send me the data ASAP', a standard model might output just that. A refined model should recognize this is impolite, generate feedback ('potential impoliteness'), and rewrite it as 'Hi Ashley, could you please send me the data at your earliest convenience?'.
Key Novelty
Iterative Feedback-Refinement Loop using a Single LLM
- Uses the *same* LLM to act as the Generator, Feedback Provider, and Refiner.
- Alternates between two steps: (1) FEEDBACK (criticizing the current output) and (2) REFINE (improving the output based on that criticism).
- Requires no gradient updates, fine-tuning, or external reward models; relies entirely on few-shot prompting.
Architecture
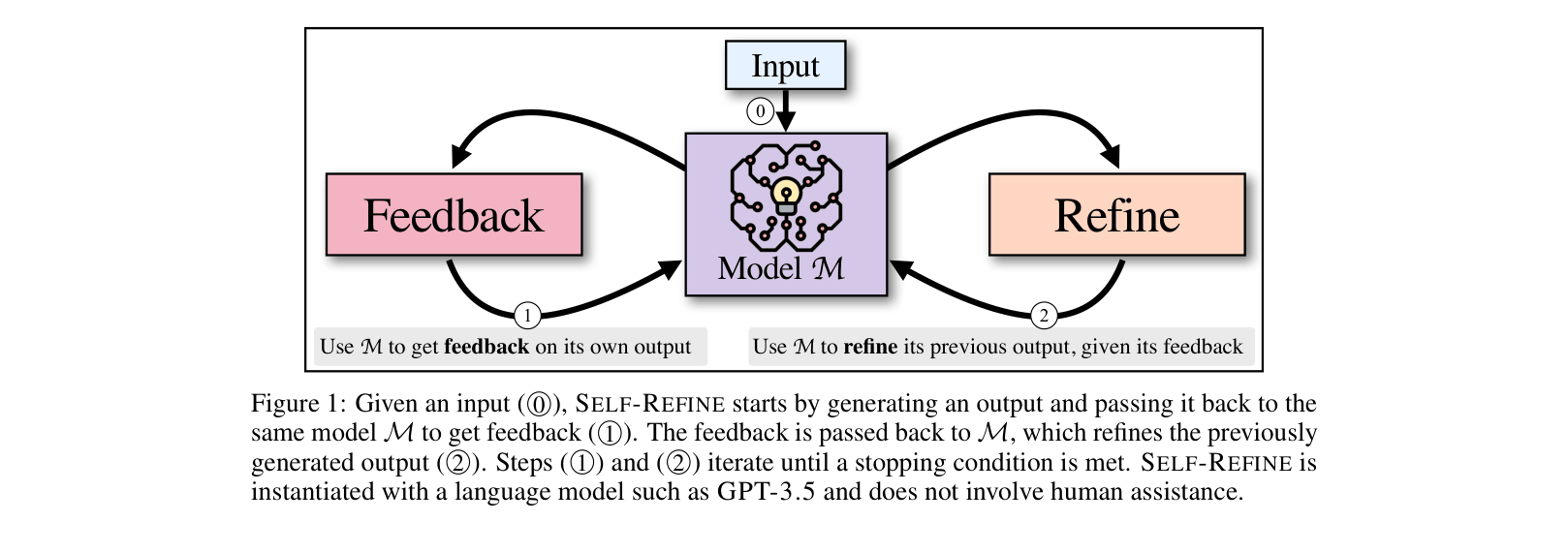
The iterative process of SELF-REFINE.
Evaluation Highlights
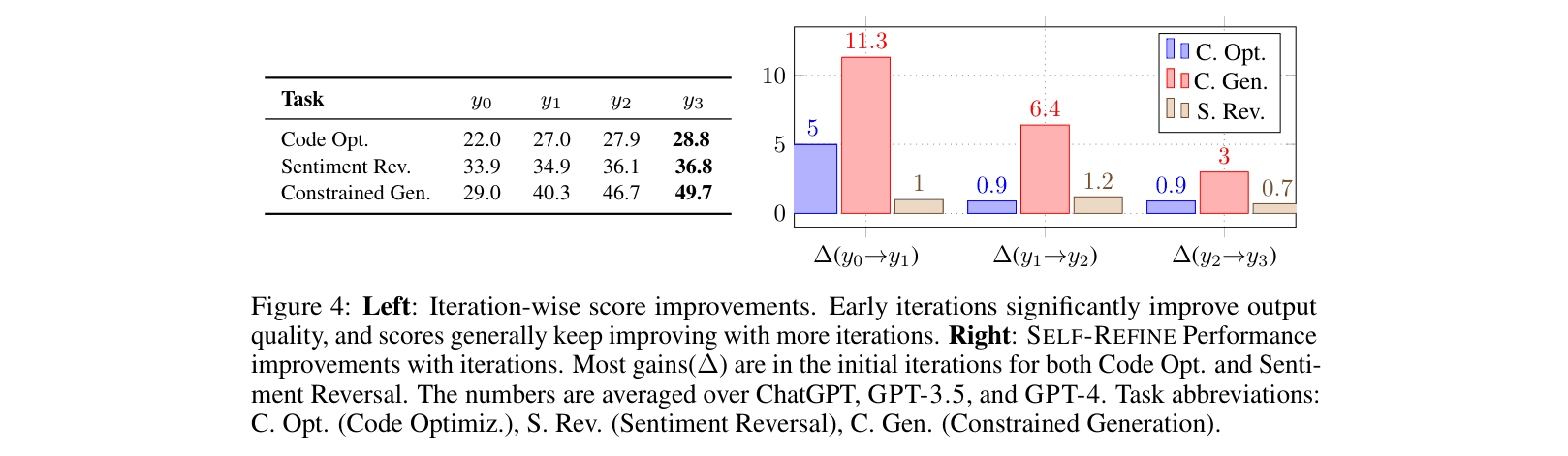
- Outperforms base LLMs (GPT-3.5, GPT-4) across 7 diverse tasks with ~20% absolute average improvement.
- GPT-4 with SELF-REFINE improves Dialogue Response Generation by +49.2% (absolute) over base GPT-4.
- Achieves +13.9% absolute improvement in Code Readability on the CodeNet dataset using GPT-3.5.
Breakthrough Assessment
8/10
Simple yet highly effective method that unlocks significant performance gains in SOTA models without training. Demonstrates that LLMs can self-correct via natural language feedback.