📝 Paper Summary
Parameter-efficient fine-tuning (PEFT)
Large Language Model Adaptation
LoRA adapts frozen pre-trained language models by injecting trainable low-rank decomposition matrices into Transformer layers, matching full fine-tuning performance with vastly fewer parameters and no added inference latency.
Core Problem
Full fine-tuning of massive models (like GPT-3 175B) is prohibitively expensive because it requires updating all parameters and storing a separate full-sized model for every downstream task.
Why it matters:
- Deploying independent instances of fine-tuned 175B models for different tasks is operationally infeasible due to storage costs (TB scale per task)
- Existing efficient methods like adapters introduce inference latency by adding depth, interfering with hardware parallelism
- Prompt tuning methods (prefix tuning) reduce usable sequence length and often fail to match full fine-tuning performance
Concrete Example:
Using GPT-3 175B as an example, full fine-tuning requires 1.2TB of VRAM during training and storing 175B parameters per task. Existing adapter layers add latency because they must be processed sequentially, slowing down inference on single-batch settings typical in production.
Key Novelty
Low-Rank Adaptation (LoRA)
- Freezes pre-trained weights and injects trainable rank decomposition matrices (A and B) into dense layers, hypothesizing that weight updates have a low intrinsic rank
- Optimizes only these small matrices during adaptation while the original massive model remains fixed
- Merges the trained low-rank matrices algebraically with the original weights during deployment, eliminating the need for separate modules at inference time
Architecture
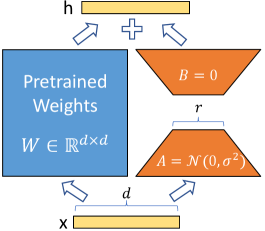
The reparametrization schema of LoRA applied to a dense layer.
Evaluation Highlights
- Reduces trainable parameters by 10,000 times compared to full fine-tuning on GPT-3 175B (from 175B to tiny fraction)
- Reduces GPU memory requirement by 3 times on GPT-3 175B (from 1.2TB to 350GB)
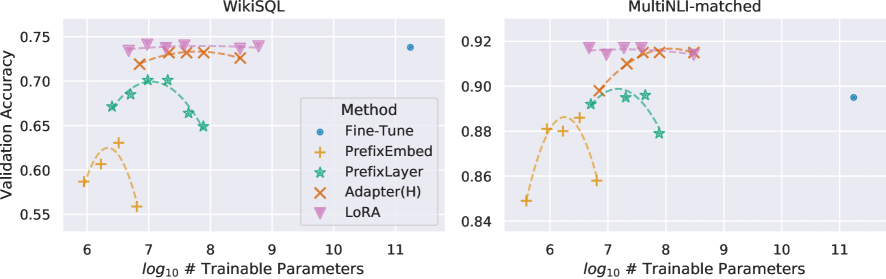
- Matches or exceeds full fine-tuning performance on RoBERTa, DeBERTa, GPT-2, and GPT-3 across GLUE, WikiSQL, and SAMSum benchmarks
Breakthrough Assessment
10/10
LoRA has become the standard for efficient fine-tuning. It solved the latency issues of adapters and the performance gap of prefix tuning, enabling the fine-tuning of massive models on consumer hardware.